





1. Introduction to Concurrency and Parallelism
Concurrency and parallelism are two fundamental concepts in programming that often get confused. Understanding the distinction between them is crucial for effective software development, especially in systems programming languages like Rust, particularly when dealing with concurrency and parallelism in Rust.
1.1. Understanding Concurrency vs. Parallelism
Concurrency refers to the ability of a program to manage multiple tasks at the same time. It does not necessarily mean that these tasks are being executed simultaneously; rather, they can be interleaved. This is particularly useful in scenarios where tasks are I/O-bound, such as reading from a file or waiting for network responses.
- Concurrency allows for better resource utilization.
- It can improve responsiveness in applications.
- It is often implemented using threads, async/await patterns, or event loops.
Parallelism, on the other hand, involves executing multiple tasks simultaneously, typically on multiple CPU cores. This is beneficial for CPU-bound tasks that require significant computational power.
- Parallelism can significantly reduce execution time for large computations.
- It requires careful management of shared resources to avoid race conditions.
- It is often implemented using multi-threading or distributed computing.
In Rust, both concurrency and parallelism are supported through its powerful type system and ownership model, which help prevent common pitfalls like data races and memory safety issues.
Key Differences Between Concurrency and Parallelism
- Execution:
- Concurrency is about dealing with lots of things at once (interleaving).
- Parallelism is about doing lots of things at once (simultaneously).
- Use Cases:
- Concurrency is ideal for I/O-bound tasks.
- Parallelism is suited for CPU-bound tasks.
- Implementation:
- Concurrency can be achieved with threads, async programming, or event-driven models.
- Parallelism typically requires multi-threading or distributed systems.
Rust's Approach to Concurrency and Parallelism
Rust development provides several features that make it an excellent choice for concurrent and parallel programming:
- Ownership and Borrowing: Rust's ownership model ensures that data is safely shared between threads without the risk of data races.
- Fearless Concurrency: Rust's type system enforces rules at compile time, allowing developers to write concurrent code without fear of common pitfalls.
- Concurrency Primitives: Rust offers various concurrency primitives, such as threads, channels, and async/await, making it easier to write concurrent applications.
Steps to Implement Concurrency in Rust
- Set up a new Rust project using Cargo:
language="language-bash"cargo new my_concurrent_app-a1b2c3-cd my_concurrent_app
- Add dependencies for async programming in
Cargo.toml:
language="language-toml"[dependencies]-a1b2c3-tokio = { version = "1", features = ["full"] }
- Write an asynchronous function:
language="language-rust"use tokio::time::{sleep, Duration};-a1b2c3--a1b2c3-async fn perform_task() {-a1b2c3- println!("Task started");-a1b2c3- sleep(Duration::from_secs(2)).await;-a1b2c3- println!("Task completed");-a1b2c3-}
- Create a main function to run the async tasks concurrently:
language="language-rust"#[tokio::main]-a1b2c3-async fn main() {-a1b2c3- let task1 = perform_task();-a1b2c3- let task2 = perform_task();-a1b2c3- tokio::join!(task1, task2);-a1b2c3-}
Steps to Implement Parallelism in Rust
- Set up a new Rust project using Cargo:
language="language-bash"cargo new my_parallel_app-a1b2c3-cd my_parallel_app
- Add dependencies for parallelism in
Cargo.toml:
language="language-toml"[dependencies]-a1b2c3-rayon = "1.5"
- Use Rayon to perform parallel computations:
language="language-rust"use rayon::prelude::*;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let numbers: Vec<i32> = (1..=10).collect();-a1b2c3- let sum: i32 = numbers.par_iter().sum();-a1b2c3- println!("Sum: {}", sum);-a1b2c3-}
By leveraging Rust's features, developers can effectively implement both concurrency and parallelism in Rust, leading to more efficient and safer applications. At Rapid Innovation, we specialize in harnessing these programming paradigms to help our clients achieve greater ROI through optimized software solutions. Partnering with us means you can expect improved performance, reduced time-to-market, and enhanced scalability for your applications. Let us guide you in navigating the complexities of Rust Blockchain development, ensuring your projects are executed efficiently and effectively.
1.2. Why Rust for Concurrent and Parallel Programming?
At Rapid Innovation, we recognize that Rust is increasingly acknowledged as a powerful language for concurrent and parallel programming due to several key features that can significantly enhance your development processes:
- Performance: Rust is designed for high performance, comparable to C and C++. It allows developers to write low-level code while maintaining high-level abstractions, making it suitable for performance-critical applications. This means that your applications can run faster and more efficiently, leading to a greater return on investment (ROI).
- Concurrency without Data Races: Rust's ownership model ensures that data races are caught at compile time. This means that if two threads try to access the same data simultaneously, the compiler will flag it as an error, preventing potential runtime crashes. By minimizing errors, we help you save time and resources, allowing you to focus on innovation. This is a key aspect of what makes rust concurrency so effective.
- Lightweight Threads: Rust's standard library provides lightweight threads, known as "green threads," which are managed by the Rust runtime. This allows for efficient context switching and better resource utilization, ensuring that your applications can handle more tasks simultaneously without compromising performance. This feature is essential for achieving concurrency in Rust.
- Ecosystem Support: The Rust ecosystem includes libraries like
Rayonfor data parallelism andTokiofor asynchronous programming, making it easier to implement concurrent and parallel solutions. Our team can leverage these tools to create tailored solutions that meet your specific needs, including those that require rust fearless concurrency. - Community and Documentation: Rust has a vibrant community and extensive documentation, which helps developers learn and implement concurrent programming techniques effectively. By partnering with us, you gain access to our expertise and resources, ensuring that your projects are executed smoothly and efficiently. This community support is invaluable for those exploring rust concurrent programming.
1.3. Rust's Memory Safety and Ownership Model
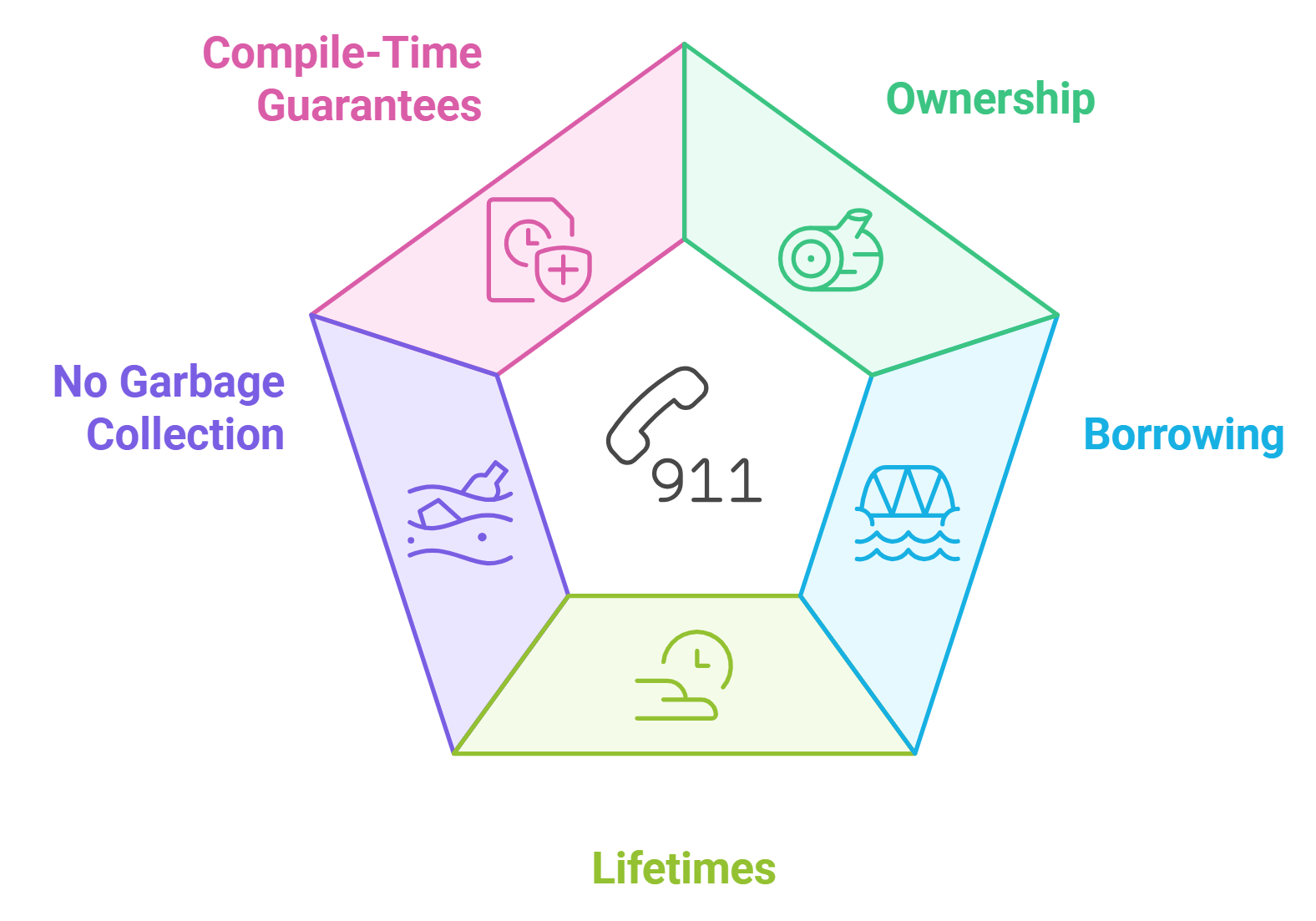
Rust's memory safety and ownership model are foundational to its approach to concurrent programming, providing several benefits that can enhance your project's success:
- Ownership: Every piece of data in Rust has a single owner, which is responsible for its memory. When the owner goes out of scope, the memory is automatically freed. This prevents memory leaks and dangling pointers, ensuring that your applications run reliably.
- Borrowing: Rust allows references to data without transferring ownership. Borrowing can be mutable or immutable, but Rust enforces rules that prevent data from being modified while it is borrowed immutably, ensuring thread safety. This leads to fewer bugs and a more stable product.
- Lifetimes: Rust uses lifetimes to track how long references are valid. This helps the compiler ensure that references do not outlive the data they point to, preventing use-after-free errors. By ensuring memory safety, we help you avoid costly downtime and maintenance.
- No Garbage Collection: Unlike languages that rely on garbage collection, Rust's ownership model eliminates the need for a garbage collector, leading to predictable performance and lower latency. This can result in a more responsive user experience for your applications.
- Compile-Time Guarantees: The ownership and borrowing rules are enforced at compile time, which means that many concurrency issues are resolved before the code even runs, leading to safer and more reliable concurrent applications. This proactive approach minimizes risks and enhances your project's overall success.
2. Basics of Rust for Concurrent Programming
To get started with concurrent programming in Rust, you need to understand some basic concepts and tools that we can help you implement effectively:
- Threads: Rust provides a simple way to create threads using the
std::threadmodule. You can spawn a new thread with thethread::spawnfunction, allowing your applications to perform multiple tasks simultaneously. - Mutexes: To safely share data between threads, Rust uses
Mutexfrom thestd::syncmodule. AMutexallows only one thread to access the data at a time, preventing data races. Our expertise ensures that your data remains secure and consistent. - Channels: Rust provides channels for communication between threads. The
std::sync::mpscmodule allows you to create channels to send messages between threads safely. This facilitates efficient inter-thread communication, enhancing your application's performance. - Example Code: Here’s a simple example demonstrating the use of threads and a mutex:
language="language-rust"use std::sync::{Arc, Mutex};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let counter = Arc::new(Mutex::new(0));-a1b2c3- let mut handles = vec![];-a1b2c3--a1b2c3- for _ in 0..10 {-a1b2c3- let counter = Arc::clone(&counter);-a1b2c3- let handle = thread::spawn(move || {-a1b2c3- let mut num = counter.lock().unwrap();-a1b2c3- *num += 1;-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3- }-a1b2c3--a1b2c3- for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3- }-a1b2c3--a1b2c3- println!("Result: {}", *counter.lock().unwrap());-a1b2c3-}
- Steps to Run the Code:
- Install Rust using
rustup. - Create a new Rust project with
cargo new my_project. - Replace the contents of
src/main.rswith the code above. - Run the project using
cargo run.
By leveraging Rust's features, our team at Rapid Innovation can help you write safe and efficient concurrent programs that take full advantage of modern multi-core processors, ultimately leading to greater ROI and success for your projects. Partner with us to unlock the full potential of your development initiatives.
2.1. Ownership and Borrowing
Ownership is a core concept in Rust that ensures memory safety without needing a garbage collector. Each value in Rust has a single owner, which is responsible for cleaning up the value when it goes out of scope. This ownership model prevents data races and ensures that memory is managed efficiently.
- Key principles of ownership:
- Each value has a single owner.
- When the owner goes out of scope, the value is dropped.
- Ownership can be transferred (moved) to another variable.
Borrowing allows references to a value without taking ownership. This is crucial for allowing multiple parts of a program to access data without duplicating it.
- Types of borrowing:
- Immutable borrowing: Multiple references can be created, but none can modify the value.
- Mutable borrowing: Only one mutable reference can exist at a time, preventing data races.
Example of ownership and borrowing:
language="language-rust"fn main() {-a1b2c3- let s1 = String::from("Hello");-a1b2c3- let s2 = &s1; // Immutable borrow-a1b2c3- println!("{}", s2); // Works fine-a1b2c3- // let s3 = &mut s1; // Error: cannot borrow `s1` as mutable because it is also borrowed as immutable-a1b2c3-}
2.2. Lifetimes
Lifetimes are a way of expressing the scope of references in Rust. They ensure that references are valid as long as they are used, preventing dangling references and ensuring memory safety.
- Key concepts of lifetimes:
- Every reference has a lifetime, which is the scope for which that reference is valid.
- The Rust compiler uses lifetimes to check that references do not outlive the data they point to.
Lifetimes are often annotated in function signatures to clarify how long references are valid. The Rust compiler can usually infer lifetimes, but explicit annotations may be necessary in complex scenarios.
Example of lifetimes:
language="language-rust"fn longest<'a>(s1: &'a str, s2: &'a str) -> &'a str {-a1b2c3- if s1.len() > s2.len() {-a1b2c3- s1-a1b2c3- } else {-a1b2c3- s2-a1b2c3- }-a1b2c3-}
In this example, the function longest takes two string slices with the same lifetime 'a and returns a reference with the same lifetime.
2.3. Smart Pointers (Box, Rc, Arc)
Smart pointers are data structures that provide more functionality than regular pointers. They manage memory automatically and help with ownership and borrowing.
- Box:
- A smart pointer that allocates memory on the heap.
- Provides ownership of the data it points to.
- Useful for large data structures or recursive types.
Example of Box:
language="language-rust"fn main() {-a1b2c3- let b = Box::new(5);-a1b2c3- println!("{}", b);-a1b2c3-}
- Rc (Reference Counted):
- A smart pointer that enables multiple ownership of data.
- Keeps track of the number of references to the data.
- When the last reference goes out of scope, the data is dropped.
Example of Rc:
language="language-rust"use std::rc::Rc;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let a = Rc::new(5);-a1b2c3- let b = Rc::clone(&a);-a1b2c3- println!("{}", b);-a1b2c3-}
- Arc (Atomic Reference Counted):
- Similar to Rc but thread-safe.
- Allows safe sharing of data across threads.
- Uses atomic operations to manage reference counts.
Example of Arc:
language="language-rust"use std::sync::Arc;-a1b2c3-use std::thread;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let a = Arc::new(5);-a1b2c3- let a_clone = Arc::clone(&a);-a1b2c3--a1b2c3- thread::spawn(move || {-a1b2c3- println!("{}", a_clone);-a1b2c3- }).join().unwrap();-a1b2c3-}
Smart pointers in Rust provide powerful tools for managing memory and ownership, making it easier to write safe and efficient code. The concepts of rust ownership and borrowing are fundamental to understanding how Rust achieves memory safety and concurrency without a garbage collector.
3. Threads in Rust
At Rapid Innovation, we understand that leveraging the right technology can significantly enhance your operational efficiency. Rust provides a powerful and safe way to handle concurrency through its rust threading model. Threads allow multiple tasks to run simultaneously, making efficient use of system resources. Rust's ownership model ensures that data races are avoided, promoting safe concurrent programming.

3.1. Creating and Joining Threads
Creating and managing threads in Rust is straightforward, thanks to the standard library's std::thread module. Here’s how you can create and join threads:
- Creating a Thread: Use the
thread::spawnfunction to create a new thread. This function takes a closure as an argument, which contains the code to be executed in the new thread. - Joining a Thread: After spawning a thread, you can call the
joinmethod on the thread handle to wait for the thread to finish execution. This ensures that the main thread does not exit before the spawned thread completes.
Example code to create and join threads:
language="language-rust"use std::thread;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let handle = thread::spawn(|| {-a1b2c3- for i in 1..5 {-a1b2c3- println!("Thread: {}", i);-a1b2c3- }-a1b2c3- });-a1b2c3--a1b2c3- // Main thread work-a1b2c3- for i in 1..3 {-a1b2c3- println!("Main: {}", i);-a1b2c3- }-a1b2c3--a1b2c3- // Wait for the thread to finish-a1b2c3- handle.join().unwrap();-a1b2c3-}
- Key Points:
- The
thread::spawnfunction returns aJoinHandle, which can be used to join the thread. - The
joinmethod blocks the calling thread until the thread represented by the handle terminates. - If the spawned thread panics, the
joinmethod will return an error.
- The
3.2. Sharing Data Between Threads
When working with threads, sharing data safely is crucial to avoid data races. Rust provides several mechanisms to share data between threads, primarily through the use of Arc (Atomic Reference Counted) and Mutex (Mutual Exclusion).
- Arc: This is a thread-safe reference-counting pointer that allows multiple threads to own the same data. It ensures that the data is deallocated only when all references are dropped.
- Mutex: This is a synchronization primitive that allows only one thread to access the data at a time. It provides a lock mechanism to ensure that data is accessed safely.
Example code to share data between threads using Arc and Mutex:
language="language-rust"use std::sync::{Arc, Mutex};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let counter = Arc::new(Mutex::new(0));-a1b2c3- let mut handles = vec![];-a1b2c3--a1b2c3- for _ in 0..10 {-a1b2c3- let counter = Arc::clone(&counter);-a1b2c3- let handle = thread::spawn(move || {-a1b2c3- let mut num = counter.lock().unwrap();-a1b2c3- *num += 1;-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3- }-a1b2c3--a1b2c3- for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3- }-a1b2c3--a1b2c3- println!("Result: {}", *counter.lock().unwrap());-a1b2c3-}
- Key Points:
- Use
Arcto share ownership of data across threads. - Use
Mutexto ensure that only one thread can access the data at a time. - Always handle the result of
lock()to avoid panics if the lock is poisoned.
- Use
By leveraging Rust's threading capabilities, developers can create efficient and safe concurrent applications. The combination of Arc and Mutex allows for safe data sharing, while the straightforward thread creation and joining process simplifies concurrent programming. At Rapid Innovation, we are committed to helping you harness these powerful features to achieve greater ROI and operational excellence. Partnering with us means you can expect enhanced productivity, reduced time-to-market, and a robust framework for your development needs.
3.3. Thread Safety and the Send Trait
Thread safety is a crucial concept in concurrent programming, ensuring that shared data is accessed and modified safely by multiple threads. In Rust, the Send trait plays a vital role in achieving thread safety.
- The
Sendtrait indicates that ownership of a type can be transferred across thread boundaries. - Types that implement
Sendcan be safely sent to another thread, allowing for concurrent execution without data races. - Most primitive types in Rust, such as integers and booleans, implement
Sendby default. - Complex types, like
Rc<T>, do not implementSendbecause they are not thread-safe. Instead,Arc<T>(atomic reference counting) is used for shared ownership across threads.
To ensure thread safety in your Rust applications, consider the following:
- Use
Arc<T>for shared ownership of data across threads. - Leverage synchronization primitives like
Mutex<T>orRwLock<T>to manage access to shared data. - Always check if a type implements
Sendwhen passing it to a thread.
In the context of 'rust thread safety', it is essential to understand how the Send trait contributes to the overall safety of concurrent programming in Rust. Additionally, 'thread safety in rust' is achieved through careful design and the use of appropriate types that adhere to the Send trait.
3.4. Thread Pools and Work Stealing
Thread pools are a powerful concurrency model that allows for efficient management of multiple threads. They help reduce the overhead of thread creation and destruction by reusing a fixed number of threads to execute tasks.
- A thread pool maintains a collection of worker threads that wait for tasks to execute.
- When a task is submitted, it is assigned to an available worker thread, which processes it and then returns to the pool.
- Work stealing is a technique used in thread pools to balance the workload among threads. If a worker thread finishes its tasks and becomes idle, it can "steal" tasks from other busy threads.
Benefits of using thread pools and work stealing include:
- Improved performance by reducing the overhead of thread management.
- Better resource utilization, as threads are reused rather than created and destroyed frequently.
- Enhanced responsiveness in applications, as tasks can be executed concurrently.
To implement a thread pool with work stealing in Rust, follow these steps:
- Use a library like
rayonortokiothat provides built-in support for thread pools and work stealing. - Define the tasks you want to execute concurrently.
- Submit tasks to the thread pool for execution.
Example code snippet using rayon:
language="language-rust"use rayon::prelude::*;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let data = vec![1, 2, 3, 4, 5];-a1b2c3--a1b2c3- let results: Vec<_> = data.par_iter()-a1b2c3- .map(|&x| x * 2)-a1b2c3- .collect();-a1b2c3--a1b2c3- println!("{:?}", results);-a1b2c3-}
4. Synchronization Primitives
Synchronization primitives are essential tools in concurrent programming, allowing threads to coordinate their actions and manage access to shared resources. In Rust, several synchronization primitives are available:
Mutex<T>: A mutual exclusion primitive that provides exclusive access to the data it wraps. Only one thread can access the data at a time, preventing data races.- To use a
Mutex, wrap your data in it and lock it when accessing:
language="language-rust"use std::sync::{Arc, Mutex};-a1b2c3--a1b2c3-let data = Arc::new(Mutex::new(0));-a1b2c3--a1b2c3-let data_clone = Arc::clone(&data);-a1b2c3-std::thread::spawn(move || {-a1b2c3- let mut num = data_clone.lock().unwrap();-a1b2c3- *num += 1;-a1b2c3-});
RwLock<T>: A read-write lock that allows multiple readers or one writer at a time. This is useful when read operations are more frequent than write operations.Condvar: A condition variable that allows threads to wait for certain conditions to be met before proceeding. It is often used in conjunction withMutex.
When using synchronization primitives, consider the following:
- Minimize the scope of locks to reduce contention.
- Avoid holding locks while performing long-running operations.
- Be cautious of deadlocks by ensuring a consistent locking order.
4.1. Mutex and RwLock
Mutex (Mutual Exclusion) and RwLock (Read-Write Lock) are synchronization primitives used in concurrent programming synchronization to manage access to shared resources.
- Mutex:
- A mutex allows only one thread to access a resource at a time.
- It is simple and effective for protecting shared data.
- When a thread locks a mutex, other threads attempting to lock it will block until the mutex is unlocked.
- RwLock:
- An RwLock allows multiple readers or a single writer at any given time.
- This is beneficial when read operations are more frequent than write operations.
- It improves performance by allowing concurrent reads while still ensuring exclusive access for writes.
Example of using Mutex in Rust:
language="language-rust"use std::sync::{Arc, Mutex};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-let counter = Arc::new(Mutex::new(0));-a1b2c3-let mut handles = vec![];-a1b2c3--a1b2c3-for _ in 0..10 {-a1b2c3- let counter = Arc::clone(&counter);-a1b2c3- let handle = thread::spawn(move || {-a1b2c3- let mut num = counter.lock().unwrap();-a1b2c3- *num += 1;-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3-}-a1b2c3--a1b2c3-for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3-}-a1b2c3--a1b2c3-println!("Result: {}", *counter.lock().unwrap());
Example of using RwLock in Rust:
language="language-rust"use std::sync::{Arc, RwLock};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-let data = Arc::new(RwLock::new(0));-a1b2c3-let mut handles = vec![];-a1b2c3--a1b2c3-for _ in 0..10 {-a1b2c3- let data = Arc::clone(&data);-a1b2c3- let handle = thread::spawn(move || {-a1b2c3- let mut num = data.write().unwrap();-a1b2c3- *num += 1;-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3-}-a1b2c3--a1b2c3-for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3-}-a1b2c3--a1b2c3-let read_num = data.read().unwrap();-a1b2c3-println!("Result: {}", *read_num);
4.2. Atomic Types
Atomic types are special data types that provide lock-free synchronization. They allow safe concurrent access to shared data without the need for mutexes.
- Characteristics of Atomic Types:
- Operations on atomic types are guaranteed to be atomic, meaning they complete in a single step relative to other threads.
- They are typically used for counters, flags, and other simple data types.
- Common Atomic Types:
AtomicBool: Represents a boolean value.AtomicIsizeandAtomicUsize: Represent signed and unsigned integers, respectively.AtomicPtr: Represents a pointer.
Example of using Atomic Types in Rust:
language="language-rust"use std::sync::atomic::{AtomicUsize, Ordering};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-let counter = AtomicUsize::new(0);-a1b2c3-let mut handles = vec![];-a1b2c3--a1b2c3-for _ in 0..10 {-a1b2c3- let handle = thread::spawn(|| {-a1b2c3- counter.fetch_add(1, Ordering::SeqCst);-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3-}-a1b2c3--a1b2c3-for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3-}-a1b2c3--a1b2c3-println!("Result: {}", counter.load(Ordering::SeqCst));
4.3. Barriers and Semaphores
Barriers and semaphores are synchronization mechanisms that help manage the execution of threads in concurrent programming synchronization.
- Barriers:
- A barrier allows multiple threads to wait until a certain condition is met before proceeding.
- It is useful for synchronizing phases of computation among threads.
- Semaphores:
- A semaphore is a signaling mechanism that controls access to a shared resource.
- It maintains a count that represents the number of available resources.
- Threads can acquire or release the semaphore, allowing for controlled access.
Example of using a Semaphore in Rust:
language="language-rust"use std::sync::{Arc, Semaphore};-a1b2c3-use std::thread;-a1b2c3--a1b2c3-let semaphore = Arc::new(Semaphore::new(2)); // Allow 2 concurrent threads-a1b2c3-let mut handles = vec![];-a1b2c3--a1b2c3-for _ in 0..5 {-a1b2c3- let semaphore = Arc::clone(&semaphore);-a1b2c3- let handle = thread::spawn(move || {-a1b2c3- let _permit = semaphore.acquire().unwrap();-a1b2c3- // Critical section-a1b2c3- });-a1b2c3- handles.push(handle);-a1b2c3-}-a1b2c3--a1b2c3-for handle in handles {-a1b2c3- handle.join().unwrap();-a1b2c3-}
These synchronization primitives are essential for ensuring data integrity and preventing race conditions in concurrent programming synchronization. By leveraging these tools, Rapid Innovation can help clients optimize their applications, ensuring efficient resource management and improved performance. Our expertise in AI and Blockchain development allows us to implement these advanced programming techniques, ultimately leading to greater ROI for our clients. When you partner with us, you can expect enhanced operational efficiency, reduced time-to-market, and a robust framework for your projects, all tailored to meet your specific business goals.
4.4. Condition Variables
Condition variables are synchronization primitives that enable threads to wait for certain conditions to be true before proceeding. They are particularly useful in scenarios where threads need to wait for resources to become available or for specific states to be reached.
- Purpose: Condition variables allow threads to sleep until a particular condition is met, which helps in avoiding busy-waiting and reduces CPU usage.
- Usage: Typically used in conjunction with mutexes to protect shared data. A thread will lock a mutex, check a condition, and if the condition is not met, it will wait on the condition variable.
- Signaling: When the condition changes (e.g., a resource becomes available), another thread can signal the condition variable, waking up one or more waiting threads.
Example of using condition variables in C++:
language="language-cpp"#include <iostream>-a1b2c3-#include <thread>-a1b2c3-#include <mutex>-a1b2c3-#include <condition_variable>-a1b2c3--a1b2c3-std::mutex mtx;-a1b2c3-std::condition_variable cv;-a1b2c3-bool ready = false;-a1b2c3--a1b2c3-void worker() {-a1b2c3- std::unique_lock<std::mutex> lock(mtx);-a1b2c3- cv.wait(lock, [] { return ready; });-a1b2c3- std::cout << "Worker thread proceeding\n";-a1b2c3-}-a1b2c3--a1b2c3-void signalWorker() {-a1b2c3- std::lock_guard<std::mutex> lock(mtx);-a1b2c3- ready = true;-a1b2c3- cv.notify_one();-a1b2c3-}-a1b2c3--a1b2c3-int main() {-a1b2c3- std::thread t(worker);-a1b2c3- std::this_thread::sleep_for(std::chrono::seconds(1));-a1b2c3- signalWorker();-a1b2c3- t.join();-a1b2c3- return 0;-a1b2c3-}
- Key Functions:
wait(): Blocks the thread until notified.notify_one(): Wakes up one waiting thread.notify_all(): Wakes up all waiting threads.
5. Message Passing
Message passing is a method of communication between threads or processes where data is sent as messages. This approach is often used in concurrent programming to avoid shared state and reduce the complexity of synchronization.
- Advantages:
- Decoupling: Threads or processes do not need to share memory, which reduces the risk of race conditions.
- Scalability: Easier to scale applications across multiple machines or processes.
- Simplicity: Simplifies the design of concurrent systems by using messages to communicate state changes.
- Types of Message Passing:
- Synchronous: The sender waits for the receiver to acknowledge receipt of the message.
- Asynchronous: The sender sends the message and continues without waiting for an acknowledgment.
5.1. Channels (mpsc)
Channels are a specific implementation of message passing, particularly in languages like Go and Rust. The term "mpsc" stands for "multiple producers, single consumer," which describes a channel that allows multiple threads to send messages to a single receiver.
- Characteristics:
- Thread Safety: Channels are designed to be safe for concurrent use, allowing multiple producers to send messages without additional synchronization.
- Buffering: Channels can be buffered or unbuffered. Buffered channels allow a certain number of messages to be sent without blocking, while unbuffered channels require the sender and receiver to synchronize.
- Implementation:
- In Rust, channels can be created using the
std::sync::mpscmodule.
- In Rust, channels can be created using the
Example of using channels in Rust:
language="language-rust"use std::sync::mpsc;-a1b2c3-use std::thread;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let (tx, rx) = mpsc::channel();-a1b2c3--a1b2c3- thread::spawn(move || {-a1b2c3- let val = String::from("Hello from thread");-a1b2c3- tx.send(val).unwrap();-a1b2c3- });-a1b2c3--a1b2c3- let received = rx.recv().unwrap();-a1b2c3- println!("Received: {}", received);-a1b2c3-}
- Key Functions:
send(): Sends a message through the channel.recv(): Receives a message from the channel, blocking if necessary.
By utilizing condition variables and message passing, developers can create efficient and safe concurrent applications that minimize the risks associated with shared state and synchronization.
5.2. Crossbeam Channels
Crossbeam is a Rust library that provides powerful concurrency tools, including channels for message passing between threads. Channels are essential for building concurrent applications, allowing threads to communicate safely and efficiently.
- Types of Channels: Crossbeam offers two main types of channels:
- Unbounded Channels: These channels can hold an unlimited number of messages. They are useful when you don't want to block the sender.
- Bounded Channels: These channels have a fixed capacity. If the channel is full, the sender will block until space is available.
- Creating a Channel:
- Use
crossbeam::channel::unbounded()for an unbounded channel. - Use
crossbeam::channel::bounded(size)for a bounded channel.
- Use
- Sending and Receiving Messages:
- Use the
send()method to send messages. - Use the
recv()method to receive messages.
- Use the
Example code snippet:
language="language-rust"use crossbeam::channel;-a1b2c3--a1b2c3-let (sender, receiver) = channel::unbounded();-a1b2c3--a1b2c3-std::thread::spawn(move || {-a1b2c3- sender.send("Hello, World!").unwrap();-a1b2c3-});-a1b2c3--a1b2c3-let message = receiver.recv().unwrap();-a1b2c3-println!("{}", message);
- Benefits of Crossbeam Channels:
- Performance: Crossbeam channels are designed for high performance and low latency.
- Safety: They ensure thread safety, preventing data races.
- Flexibility: They support both synchronous and asynchronous message passing.
5.3. Actor Model with Actix
The Actor Model is a conceptual model used for designing concurrent systems. Actix is a powerful actor framework for Rust that allows developers to build concurrent applications using the Actor Model.
- Key Concepts:
- Actors: Independent units of computation that encapsulate state and behavior. Each actor processes messages asynchronously.
- Messages: Actors communicate by sending messages to each other. Messages are immutable and can be of any type.
- Creating an Actor:
- Define a struct to represent the actor.
- Implement the
Actortrait for the struct.
Example code snippet:
language="language-rust"use actix::prelude::*;-a1b2c3--a1b2c3-struct MyActor;-a1b2c3--a1b2c3-impl Message for MyActor {-a1b2c3- type Result = String;-a1b2c3-}-a1b2c3--a1b2c3-impl Actor for MyActor {-a1b2c3- type Context = Context<Self>;-a1b2c3-}-a1b2c3--a1b2c3-impl Handler<MyActor> for MyActor {-a1b2c3- type Result = String;-a1b2c3--a1b2c3- fn handle(&mut self, _: MyActor, _: &mut Self::Context) -> Self::Result {-a1b2c3- "Hello from MyActor!".to_string()-a1b2c3- }-a1b2c3-}
- Benefits of Using Actix:
- Concurrency: Actix allows for high levels of concurrency, making it suitable for building scalable applications.
- Fault Tolerance: The actor model inherently supports fault tolerance, as actors can be restarted independently.
- Ease of Use: Actix provides a straightforward API for defining actors and handling messages.
6. Async Programming in Rust
Async programming in Rust allows developers to write non-blocking code, which is essential for building responsive applications, especially in I/O-bound scenarios.
- Key Features:
- Futures: The core abstraction for asynchronous programming in Rust. A future represents a value that may not be available yet.
- Async/Await Syntax: Rust provides
asyncandawaitkeywords to simplify writing asynchronous code.
- Creating an Async Function:
- Use the
async fnsyntax to define an asynchronous function. - Use
.awaitto wait for a future to resolve.
- Use the
Example code snippet:
language="language-rust"use tokio;-a1b2c3--a1b2c3-#[tokio::main]-a1b2c3-async fn main() {-a1b2c3- let result = async_function().await;-a1b2c3- println!("{}", result);-a1b2c3-}-a1b2c3--a1b2c3-async fn async_function() -> String {-a1b2c3- "Hello from async function!".to_string()-a1b2c3-}
- Benefits of Async Programming:
- Efficiency: Non-blocking I/O operations allow for better resource utilization.
- Scalability: Async code can handle many connections simultaneously, making it ideal for web servers and network applications.
- Improved Responsiveness: Applications remain responsive while waiting for I/O operations to complete.
At Rapid Innovation, we leverage these advanced programming paradigms, including Rust concurrency tools, to help our clients build robust, scalable, and efficient applications. By integrating cutting-edge technologies like Rust's concurrency tools and async programming, we ensure that our clients achieve greater ROI through enhanced performance and responsiveness in their software solutions. Partnering with us means you can expect not only technical excellence but also a commitment to delivering solutions that align with your business goals.
6.1. Futures and Async/Await Syntax
Futures in Rust represent a value that may not be immediately available but will be computed at some point in the future. The async/await syntax simplifies working with these futures, making asynchronous programming in Rust more intuitive.
- Futures:
- A future is an abstraction that allows you to work with values that are not yet available.
- It can be thought of as a placeholder for a value that will be computed later.
- Async/Await:
- The
asynckeyword is used to define an asynchronous function, which returns a future. - The
awaitkeyword is used to pause the execution of an async function until the future is resolved. - Example:
language="language-rust"async fn fetch_data() -> String {-a1b2c3- // Simulate a network request-a1b2c3- "Data fetched".to_string()-a1b2c3-}-a1b2c3--a1b2c3-async fn main() {-a1b2c3- let data = fetch_data().await;-a1b2c3- println!("{}", data);-a1b2c3-}
- Benefits:
- Improved readability and maintainability of asynchronous code.
- Allows writing asynchronous code that looks similar to synchronous code.
6.2. Tokio Runtime
Tokio is an asynchronous runtime for Rust that provides the necessary tools to write non-blocking applications. It is built on top of the futures library and is designed to work seamlessly with async/await syntax.
- Key Features:
- Event Loop: Tokio uses an event loop to manage asynchronous tasks efficiently.
- Task Scheduling: It schedules tasks to run concurrently, allowing for high throughput.
- Timers and I/O: Provides utilities for working with timers and asynchronous I/O operations.
- Setting Up Tokio:
- Add Tokio to your
Cargo.toml:
language="language-toml"[dependencies]-a1b2c3-tokio = { version = "1", features = ["full"] }
- Creating a Tokio Runtime:
language="language-rust"#[tokio::main]-a1b2c3-async fn main() {-a1b2c3- // Your async code here-a1b2c3-}
- Benefits:
- High performance due to its non-blocking nature.
- Extensive ecosystem with libraries for various asynchronous tasks.
6.3. Async I/O Operations
Async I/O operations allow for non-blocking input and output, enabling applications to handle multiple tasks simultaneously without waiting for each operation to complete.
- Key Concepts:
- Non-blocking I/O: Operations that do not block the execution of the program while waiting for data.
- Stream and Sink: Streams represent a series of values over time, while sinks are used to send values.
- Example of Async File Read:
language="language-rust"use tokio::fs::File;-a1b2c3-use tokio::io::{self, AsyncReadExt};-a1b2c3--a1b2c3-#[tokio::main]-a1b2c3-async fn main() -> io::Result<()> {-a1b2c3- let mut file = File::open("example.txt").await?;-a1b2c3- let mut contents = vec![];-a1b2c3- file.read_to_end(&mut contents).await?;-a1b2c3- println!("{:?}", contents);-a1b2c3- Ok(())-a1b2c3-}
- Benefits:
- Improved application responsiveness by allowing other tasks to run while waiting for I/O operations.
- Efficient resource utilization, especially in networked applications.
By leveraging futures, async/await syntax, and the Tokio runtime, developers can create highly efficient and responsive applications in Rust. At Rapid Innovation, we harness these advanced async programming techniques in Rust to deliver robust solutions that drive greater ROI for our clients. Partnering with us means you can expect enhanced performance, reduced time-to-market, and a significant competitive edge in your industry. Let us help you achieve your goals efficiently and effectively.
6.4. Error Handling in Async Code
Error handling in asynchronous code is crucial for maintaining the stability and reliability of applications. Unlike synchronous code, where errors can be caught in a straightforward manner, async code requires a more nuanced approach. Here are some key strategies for effective error handling in async programming:
- Use Try-Catch Blocks: Wrap your async calls in try-catch blocks to handle exceptions gracefully.
language="language-javascript"async function fetchData() {-a1b2c3- try {-a1b2c3- const response = await fetch('https://api.example.com/data');-a1b2c3- const data = await response.json();-a1b2c3- return data;-a1b2c3- } catch (error) {-a1b2c3- console.error('Error fetching data:', error);-a1b2c3- }-a1b2c3-}
- Promise Rejection Handling: Always handle promise rejections using
.catch()to avoid unhandled promise rejections.
language="language-javascript"fetchData()-a1b2c3- .then(data => console.log(data))-a1b2c3- .catch(error => console.error('Error:', error));
- Centralized Error Handling: Implement a centralized error handling mechanism to manage errors across your application. This can be done using middleware in frameworks like Express.js.
- Logging: Use logging libraries to capture error details for debugging purposes. This can help in identifying issues in production environments.
- User Feedback: Provide meaningful feedback to users when an error occurs. This can enhance user experience and help them understand what went wrong.
7. Parallel Programming Techniques
Parallel programming techniques allow developers to execute multiple computations simultaneously, improving performance and efficiency. Here are some common techniques:
- Thread-Based Parallelism: This involves using multiple threads to perform tasks concurrently. Each thread can run on a separate core, making it suitable for CPU-bound tasks.
- Process-Based Parallelism: This technique uses multiple processes to achieve parallelism. Each process has its own memory space, which can help avoid issues related to shared state.
- Asynchronous Programming: This allows tasks to run in the background while the main thread continues executing. It is particularly useful for I/O-bound tasks.
- Task Parallelism: This involves breaking down a task into smaller sub-tasks that can be executed in parallel. This is often used in data processing applications.
7.1. Data Parallelism
Data parallelism is a specific type of parallel programming that focuses on distributing data across multiple processors or cores. It is particularly effective for operations that can be performed independently on different pieces of data. Here are some key aspects:
- Vectorization: This technique involves applying the same operation to multiple data points simultaneously. Many programming languages and libraries support vectorized operations, which can significantly speed up computations.
- Map-Reduce: This programming model allows for processing large data sets with a distributed algorithm. The "Map" function processes data in parallel, while the "Reduce" function aggregates the results.
- GPU Computing: Graphics Processing Units (GPUs) are designed for parallel processing and can handle thousands of threads simultaneously. This makes them ideal for data parallelism in applications like machine learning and scientific computing.
- Libraries and Frameworks: Utilize libraries such as OpenMP, MPI, or TensorFlow for implementing data parallelism in your applications. These tools provide abstractions that simplify the development of parallel algorithms.
- Performance Considerations: When implementing data parallelism, consider factors such as data transfer overhead, load balancing, and memory access patterns to optimize performance.
By understanding and applying these error handling techniques and parallel programming strategies, developers can create more robust and efficient applications. At Rapid Innovation, we leverage these methodologies to ensure that our clients' applications are not only high-performing but also resilient to errors, ultimately leading to greater ROI and enhanced user satisfaction. Partnering with us means you can expect tailored solutions that drive efficiency and effectiveness in achieving your business goals.
7.2. Task Parallelism
Task parallelism is a programming model that allows multiple tasks to be executed simultaneously. This approach is particularly useful in scenarios where tasks are independent and can be performed concurrently, leading to improved performance and resource utilization.
- Key characteristics of task parallelism:
- Tasks can be executed in any order.
- Each task may have different execution times.
- Ideal for workloads that can be divided into smaller, independent units.
- Benefits of task parallelism:
- Improved performance by utilizing multiple CPU cores.
- Better resource management, as tasks can be distributed across available resources.
- Enhanced responsiveness in applications, especially in user interfaces.
- Common use cases:
- Web servers handling multiple requests.
- Data processing applications that can split workloads.
- Scientific simulations that can run independent calculations.
7.3. Rayon for Easy Parallelism
Rayon is a data parallelism library for Rust that simplifies the process of writing parallel code. It abstracts away the complexities of thread management, allowing developers to focus on the logic of their applications.
- Features of Rayon:
- Easy-to-use API that integrates seamlessly with Rust's iterator patterns.
- Automatic load balancing, distributing work evenly across threads.
- Safe concurrency, leveraging Rust's ownership model to prevent data races.
- Steps to use Rayon:
- Add Rayon to your project by including it in your
Cargo.toml:
language="language-toml"[dependencies]-a1b2c3-rayon = "1.5"
- Import Rayon in your Rust file:
language="language-rust"use rayon::prelude::*;
- Use parallel iterators to process collections:
language="language-rust"let numbers: Vec<i32> = (1..100).collect();-a1b2c3-let sum: i32 = numbers.par_iter().map(|&x| x * 2).sum();
- Advantages of using Rayon:
- Simplifies parallel programming, reducing boilerplate code.
- Automatically optimizes performance based on available hardware.
- Encourages a functional programming style, making code easier to read and maintain.
7.4. SIMD (Single Instruction, Multiple Data)
SIMD (Single Instruction, Multiple Data) is a parallel computing paradigm that allows a single instruction to process multiple data points simultaneously. This technique is particularly effective for tasks that involve large datasets, such as image processing or scientific computations.
- Key aspects of SIMD:
- Operates on vectors of data, applying the same operation to multiple elements.
- Utilizes specialized CPU instructions to enhance performance.
- Can significantly reduce the number of instructions executed, leading to faster processing times.
- Benefits of SIMD:
- Increased throughput for data-intensive applications.
- Reduced power consumption compared to executing multiple instructions sequentially.
- Improved cache utilization, as data is processed in larger chunks.
- Common SIMD implementations:
- Intel's SSE (Streaming SIMD Extensions) and AVX (Advanced Vector Extensions).
- ARM's NEON technology for mobile devices.
- Rust's
packed_simdcrate for SIMD operations in Rust. - Example of SIMD in Rust:
- Add the
packed_simdcrate to yourCargo.toml:
language="language-toml"[dependencies]-a1b2c3-packed_simd = "0.3"
- Use SIMD types for parallel operations:
language="language-rust"use packed_simd::f32x4;-a1b2c3--a1b2c3-let a = f32x4::from_slice_unaligned(&[1.0, 2.0, 3.0, 4.0]);-a1b2c3-let b = f32x4::from_slice_unaligned(&[5.0, 6.0, 7.0, 8.0]);-a1b2c3-let result = a + b; // SIMD addition
By leveraging task parallelism programming, libraries like Rayon, and SIMD techniques, developers can significantly enhance the performance of their applications, making them more efficient and responsive. At Rapid Innovation, we specialize in implementing these advanced programming models to help our clients achieve greater ROI through optimized performance and resource utilization. Partnering with us means you can expect improved application responsiveness, better resource management, and ultimately, a more effective path to achieving your business goals.
8. Concurrent Data Structures
At Rapid Innovation, we understand that concurrent data structures are crucial for enabling multiple threads to access and modify data simultaneously without causing inconsistencies or corrupting the data. These structures are essential in multi-threaded programming, where performance and data integrity are paramount. By leveraging our expertise in Rust cryptocurrency development, we can help you implement these advanced concurrent data structures to enhance your applications' efficiency and reliability.
8.1. Lock-free Data Structures
Lock-free data structures represent a significant advancement in concurrent programming. They allow threads to operate on shared data without using locks, minimizing thread contention and improving performance, especially in high-concurrency environments.
Benefits of Lock-free Data Structures:
- Increased Performance: By avoiding locks, lock-free structures reduce the overhead associated with thread management, leading to faster execution times.
- Improved Responsiveness: Threads can continue to make progress even if other threads are blocked, resulting in better responsiveness in applications, which is critical for user satisfaction.
- Avoidance of Deadlocks: The absence of locks eliminates the risk of deadlocks, ensuring smoother operation of your applications.
Common Lock-free Data Structures:
- Lock-free Stacks: Implemented using atomic operations to allow push and pop operations without locks.
- Lock-free Queues: Enable multiple threads to enqueue and dequeue items concurrently.
- Lock-free Lists: Allow for concurrent insertions and deletions without locks.
Implementation Steps for a Lock-free Stack:
- Use atomic pointers to represent the top of the stack.
- Implement push and pop operations using compare-and-swap (CAS) to ensure thread safety.
- Ensure that the stack maintains its integrity during concurrent operations.
Example Code for a Lock-free Stack:
language="language-cpp"class LockFreeStack {-a1b2c3-private:-a1b2c3- struct Node {-a1b2c3- int data;-a1b2c3- Node* next;-a1b2c3- };-a1b2c3- std::atomic<Node*> head;-a1b2c3--a1b2c3-public:-a1b2c3- LockFreeStack() : head(nullptr) {}-a1b2c3--a1b2c3- void push(int value) {-a1b2c3- Node* newNode = new Node{value, nullptr};-a1b2c3- Node* oldHead;-a1b2c3- do {-a1b2c3- oldHead = head.load();-a1b2c3- newNode->next = oldHead;-a1b2c3- } while (!head.compare_exchange_weak(oldHead, newNode));-a1b2c3- }-a1b2c3--a1b2c3- bool pop(int& value) {-a1b2c3- Node* oldHead;-a1b2c3- do {-a1b2c3- oldHead = head.load();-a1b2c3- if (!oldHead) return false; // Stack is empty-a1b2c3- } while (!head.compare_exchange_weak(oldHead, oldHead->next));-a1b2c3- value = oldHead->data;-a1b2c3- delete oldHead;-a1b2c3- return true;-a1b2c3- }-a1b2c3-};
8.2. Concurrent Hash Maps
Concurrent hash maps are specialized data structures that allow multiple threads to read and write data concurrently while maintaining data integrity. They are particularly useful in scenarios where frequent updates and lookups are required, making them ideal for applications that demand high performance.
Key Features of Concurrent Hash Maps:
- Segmented Locking: Many implementations use segmented locking, where the hash map is divided into segments, each protected by its own lock. This allows multiple threads to access different segments simultaneously, enhancing throughput.
- Lock-free Operations: Some advanced implementations provide lock-free operations for certain read and write actions, further enhancing performance.
- Dynamic Resizing: Concurrent hash maps can dynamically resize themselves to accommodate more entries without significant performance degradation, ensuring scalability.
Implementation Steps for a Concurrent Hash Map:
- Divide the hash map into multiple segments.
- Use locks for each segment to allow concurrent access.
- Implement methods for insertion, deletion, and lookup that respect the locking mechanism.
Example Code for a Simple Concurrent Hash Map:
language="language-cpp"#include <mutex>-a1b2c3-#include <vector>-a1b2c3-#include <list>-a1b2c3-#include <string>-a1b2c3--a1b2c3-class ConcurrentHashMap {-a1b2c3-private:-a1b2c3- static const int numBuckets = 10;-a1b2c3- std::vector<std::list<std::pair<std::string, int>>> table;-a1b2c3- std::vector<std::mutex> locks;-a1b2c3--a1b2c3-public:-a1b2c3- ConcurrentHashMap() : table(numBuckets), locks(numBuckets) {}-a1b2c3--a1b2c3- void insert(const std::string& key, int value) {-a1b2c3- int index = std::hash<std::string>{}(key) % numBuckets;-a1b2c3- std::lock_guard<std::mutex> guard(locks[index]);-a1b2c3- table[index].emplace_back(key, value);-a1b2c3- }-a1b2c3--a1b2c3- bool find(const std::string& key, int& value) {-a1b2c3- int index = std::hash<std::string>{}(key) % numBuckets;-a1b2c3- std::lock_guard<std::mutex> guard(locks[index]);-a1b2c3- for (const auto& pair : table[index]) {-a1b2c3- if (pair.first == key) {-a1b2c3- value = pair.second;-a1b2c3- return true;-a1b2c3- }-a1b2c3- }-a1b2c3- return false;-a1b2c3- }-a1b2c3-};
In conclusion, concurrent data structures, particularly lock-free data structures and concurrent hash maps, are vital for efficient multi-threaded programming. They provide mechanisms to ensure data integrity while allowing high levels of concurrency, making them essential in modern software development. By partnering with Rapid Innovation, you can leverage our expertise in java concurrent data structures to implement these advanced structures, ultimately achieving greater ROI and enhancing the performance of your applications. Let us help you navigate the complexities of multi-threaded programming and unlock the full potential of your projects.
8.3. Concurrent Queues and Stacks
Concurrent queues and stacks are data structures designed to handle multiple threads accessing them simultaneously without causing data corruption or inconsistency. They are essential in multi-threaded programming, where threads may need to share data efficiently.
Key Characteristics:
- Thread Safety: These structures are designed to be safe for concurrent access, meaning multiple threads can read and write without causing race conditions.
- Lock-Free Operations: Many concurrent queues and stacks implement lock-free algorithms, allowing threads to operate without traditional locking mechanisms, which can lead to performance bottlenecks.
Types of Concurrent Queues:
- Blocking Queues: These queues block the calling thread when trying to dequeue from an empty queue or enqueue to a full queue. They are useful in producer-consumer scenarios.
- Non-Blocking Queues: These allow threads to attempt to enqueue or dequeue without blocking, often using atomic operations to ensure thread safety.
Implementation Steps:
- Choose a suitable concurrent data structure based on your application needs (e.g.,
ConcurrentLinkedQueuein Java). - Use atomic operations (like compare-and-swap) to manage state changes.
- Ensure proper handling of edge cases, such as empty queues or stacks.
Example Code for a Concurrent Queue in Java:
language="language-java"import java.util.concurrent.ConcurrentLinkedQueue;-a1b2c3--a1b2c3-public class ConcurrentQueueExample {-a1b2c3- public static void main(String[] args) {-a1b2c3- ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<>();-a1b2c3--a1b2c3- // Adding elements-a1b2c3- queue.offer(1);-a1b2c3- queue.offer(2);-a1b2c3--a1b2c3- // Removing elements-a1b2c3- Integer element = queue.poll();-a1b2c3- System.out.println("Removed: " + element);-a1b2c3- }-a1b2c3-}
8.4. Read-Copy-Update (RCU)
Read-Copy-Update (RCU) is a synchronization mechanism that allows multiple threads to read shared data concurrently while updates are made in a way that does not interfere with ongoing reads. This is particularly useful in scenarios where reads are more frequent than writes.
Key Features:
- Read Optimization: RCU allows readers to access data without locking, which significantly improves performance in read-heavy applications.
- Deferred Updates: Updates are made to a copy of the data, and once the update is complete, the new version is made visible to readers.
Implementation Steps:
- Create a data structure that supports RCU.
- When a thread wants to read, it accesses the current version of the data.
- For updates, create a new version of the data, update it, and then switch the pointer to the new version.
- Use a mechanism to ensure that no readers are accessing the old version before it is freed.
Example Code for RCU in C:
language="language-c"#include <stdio.h>-a1b2c3-#include <stdlib.h>-a1b2c3-#include <pthread.h>-a1b2c3--a1b2c3-typedef struct Node {-a1b2c3- int data;-a1b2c3- struct Node* next;-a1b2c3-} Node;-a1b2c3--a1b2c3-Node* head = NULL;-a1b2c3--a1b2c3-void rcu_read_lock() {-a1b2c3- // Implementation of read lock-a1b2c3-}-a1b2c3--a1b2c3-void rcu_read_unlock() {-a1b2c3- // Implementation of read unlock-a1b2c3-}-a1b2c3--a1b2c3-void update_data(int new_data) {-a1b2c3- Node* new_node = malloc(sizeof(Node));-a1b2c3- new_node->data = new_data;-a1b2c3- new_node->next = head;-a1b2c3- head = new_node;-a1b2c3-}-a1b2c3--a1b2c3-void read_data() {-a1b2c3- rcu_read_lock();-a1b2c3- Node* current = head;-a1b2c3- while (current) {-a1b2c3- printf("%d\n", current->data);-a1b2c3- current = current->next;-a1b2c3- }-a1b2c3- rcu_read_unlock();-a1b2c3-}
9. Advanced Concurrency Patterns
Advanced concurrency patterns extend basic concurrency mechanisms to solve more complex problems in multi-threaded environments. These patterns help manage shared resources, coordinate tasks, and improve performance.
Common Patterns:
- Fork-Join: This pattern divides a task into subtasks that can be processed in parallel and then combines the results.
- Pipeline: In this pattern, data flows through a series of processing stages, with each stage potentially running in parallel.
- Actor Model: This model encapsulates state and behavior in "actors" that communicate through message passing, avoiding shared state issues.
Implementation Steps:
- Identify the concurrency pattern that best fits your problem.
- Design the architecture to support the chosen pattern.
- Implement synchronization mechanisms as needed to ensure data integrity.
Example Code for Fork-Join in Java:
language="language-java"import java.util.concurrent.RecursiveTask;-a1b2c3-import java.util.concurrent.ForkJoinPool;-a1b2c3--a1b2c3-public class ForkJoinExample extends RecursiveTask<Integer> {-a1b2c3- private final int start;-a1b2c3- private final int end;-a1b2c3--a1b2c3- public ForkJoinExample(int start, int end) {-a1b2c3- this.start = start;-a1b2c3- this.end = end;-a1b2c3- }-a1b2c3--a1b2c3- @Override-a1b2c3- protected Integer compute() {-a1b2c3- if (end - start <= 10) {-a1b2c3- return computeDirectly();-a1b2c3- }-a1b2c3- int mid = (start + end) / 2;-a1b2c3- ForkJoinExample leftTask = new ForkJoinExample(start, mid);-a1b2c3- ForkJoinExample rightTask = new ForkJoinExample(mid, end);-a1b2c3- leftTask.fork();-a1b2c3- return rightTask.compute() + leftTask.join();-a1b2c3- }-a1b2c3--a1b2c3- private Integer computeDirectly() {-a1b2c3- // Direct computation logic-a1b2c3- return end - start; // Example logic-a1b2c3- }-a1b2c3--a1b2c3- public static void main(String[] args) {-a1b2c3- ForkJoinPool pool = new ForkJoinPool();-a1b2c3- ForkJoinExample task = new ForkJoinExample(0, 100);-a1b2c3- int result = pool.invoke(task);-a1b2c3- System.out.println("Result: " + result);-a1b2c3- }-a1b2c3-}
At Rapid Innovation, we understand the complexities of multi-threaded programming and the importance of efficient data handling. By leveraging our expertise in concurrent queues and stacks and advanced concurrency patterns, we can help you optimize your applications for better performance and reliability. Partnering with us means you can expect enhanced scalability, reduced latency, and ultimately, a greater return on investment as we tailor solutions to meet your specific needs. Let us guide you in achieving your goals effectively and efficiently.
9.1. Dining Philosophers Problem
The Dining Philosophers Problem is a classic synchronization problem in computer science that illustrates the challenges of resource sharing among multiple processes. It involves five philosophers sitting around a table, where each philosopher alternates between thinking and eating. To eat, a philosopher needs two forks, which are shared with their neighbors.
Key concepts:
- Deadlock: A situation where philosophers hold one fork and wait indefinitely for the other.
- Starvation: A scenario where a philosopher is perpetually denied access to both forks.
- Concurrency: Multiple philosophers trying to eat simultaneously.
To solve the Dining Philosophers Problem, several strategies can be employed:
- Resource Hierarchy: Assign a strict order to the forks, ensuring that philosophers pick up the lower-numbered fork first.
- Chandy/Misra Solution: Introduce a token system where a philosopher must request permission to pick up forks.
- Asymmetric Solution: Make one philosopher pick up the left fork first and the other the right fork, reducing the chances of deadlock.
Example code for a simple solution using semaphores:
language="language-python"import threading-a1b2c3-import time-a1b2c3--a1b2c3-class Philosopher(threading.Thread):-a1b2c3- def __init__(self, name, left_fork, right_fork):-a1b2c3- threading.Thread.__init__(self)-a1b2c3- self.name = name-a1b2c3- self.left_fork = left_fork-a1b2c3- self.right_fork = right_fork-a1b2c3--a1b2c3- def run(self):-a1b2c3- while True:-a1b2c3- self.think()-a1b2c3- self.eat()-a1b2c3--a1b2c3- def think(self):-a1b2c3- print(f"{self.name} is thinking.")-a1b2c3- time.sleep(1)-a1b2c3--a1b2c3- def eat(self):-a1b2c3- with self.left_fork:-a1b2c3- with self.right_fork:-a1b2c3- print(f"{self.name} is eating.")-a1b2c3- time.sleep(1)-a1b2c3--a1b2c3-forks = [threading.Lock() for _ in range(5)]-a1b2c3-philosophers = [Philosopher(f"Philosopher {i}", forks[i], forks[(i + 1) % 5]) for i in range(5)]-a1b2c3--a1b2c3-for philosopher in philosophers:-a1b2c3- philosopher.start()
9.2. Readers-Writers Problem
The Readers-Writers Problem addresses the situation where multiple processes need to read and write shared data. The challenge lies in ensuring that readers can access the data simultaneously while writers have exclusive access.
Key concepts:
- Readers: Can read the data concurrently.
- Writers: Require exclusive access to modify the data.
- Priority: Deciding whether to prioritize readers or writers can affect performance.
To solve the Readers-Writers Problem, various strategies can be implemented:
- First Readers-Writers Solution: Allow multiple readers but block writers until all readers finish.
- Second Readers-Writers Solution: Prioritize writers, allowing them to access the data as soon as they request it.
- Read-Write Locks: Use specialized locks that allow multiple readers or a single writer.
Example code using read-write locks:
language="language-python"import threading-a1b2c3--a1b2c3-class ReadWriteLock:-a1b2c3- def __init__(self):-a1b2c3- self.readers = 0-a1b2c3- self.lock = threading.Lock()-a1b2c3- self.write_lock = threading.Lock()-a1b2c3--a1b2c3- def acquire_read(self):-a1b2c3- with self.lock:-a1b2c3- self.readers += 1-a1b2c3- if self.readers == 1:-a1b2c3- self.write_lock.acquire()-a1b2c3--a1b2c3- def release_read(self):-a1b2c3- with self.lock:-a1b2c3- self.readers -= 1-a1b2c3- if self.readers == 0:-a1b2c3- self.write_lock.release()-a1b2c3--a1b2c3- def acquire_write(self):-a1b2c3- self.write_lock.acquire()-a1b2c3--a1b2c3- def release_write(self):-a1b2c3- self.write_lock.release()-a1b2c3--a1b2c3-rw_lock = ReadWriteLock()-a1b2c3--a1b2c3-def reader():-a1b2c3- rw_lock.acquire_read()-a1b2c3- print("Reading data.")-a1b2c3- rw_lock.release_read()-a1b2c3--a1b2c3-def writer():-a1b2c3- rw_lock.acquire_write()-a1b2c3- print("Writing data.")-a1b2c3- rw_lock.release_write()
9.3. Producer-Consumer Pattern
The Producer-Consumer Pattern is a classic synchronization problem where producers generate data and place it into a buffer, while consumers retrieve and process that data. The challenge is to ensure that the buffer does not overflow (when producers produce too quickly) or underflow (when consumers consume too quickly).
Key concepts:
- Buffer: A shared resource that holds data produced by producers.
- Synchronization: Ensuring that producers and consumers operate without conflicts.
To implement the Producer-Consumer Pattern, you can use semaphores or condition variables:
- Bounded Buffer: Use a fixed-size buffer to limit the number of items.
- Semaphores: Use semaphores to signal when the buffer is full or empty.
Example code using a bounded buffer:
language="language-python"import threading-a1b2c3-import time-a1b2c3-import random-a1b2c3--a1b2c3-buffer = []-a1b2c3-buffer_size = 5-a1b2c3-buffer_lock = threading.Lock()-a1b2c3-empty = threading.Semaphore(buffer_size)-a1b2c3-full = threading.Semaphore(0)-a1b2c3--a1b2c3-def producer():-a1b2c3- while True:-a1b2c3- item = random.randint(1, 100)-a1b2c3- empty.acquire()-a1b2c3- buffer_lock.acquire()-a1b2c3- buffer.append(item)-a1b2c3- print(f"Produced {item}.")-a1b2c3- buffer_lock.release()-a1b2c3- full.release()-a1b2c3- time.sleep(random.random())-a1b2c3--a1b2c3-def consumer():-a1b2c3- while True:-a1b2c3- full.acquire()-a1b2c3- buffer_lock.acquire()-a1b2c3- item = buffer.pop(0)-a1b2c3- print(f"Consumed {item}.")-a1b2c3- buffer_lock.release()-a1b2c3- empty.release()-a1b2c3- time.sleep(random.random())-a1b2c3--a1b2c3-threading.Thread(target=producer).start()-a1b2c3-threading.Thread(target=consumer).start()
In the context of synchronization issues, one might encounter problems such as 'outlook sync issue', 'outlook sync problems', or 'outlook synchronization issues' when dealing with shared resources. These issues can be analogous to the challenges faced in the Dining Philosophers Problem, where resource contention can lead to deadlock or starvation. Similarly, in the Readers-Writers Problem, one might experience 'outlook folder sync issues' if multiple processes are trying to access shared data simultaneously, leading to synchronization problems. In the Producer-Consumer Pattern, if the buffer is not managed correctly, it could result in 'ms outlook sync issues' or 'outlook 365 sync issues', reflecting the need for proper synchronization mechanisms to avoid overflow or underflow situations.
9.4. Implementing a Thread-Safe Singleton
A Singleton is a design pattern that restricts the instantiation of a class to one single instance. In multi-threaded applications, ensuring that this instance is created in a thread-safe manner is crucial to avoid issues like race conditions. Here are some common approaches to implement a thread-safe Singleton:
- Eager Initialization: The instance is created at the time of class loading. This is simple but can lead to resource wastage if the instance is never used.
language="language-java"public class Singleton {-a1b2c3- private static final Singleton instance = new Singleton();-a1b2c3--a1b2c3- private Singleton() {}-a1b2c3--a1b2c3- public static Singleton getInstance() {-a1b2c3- return instance;-a1b2c3- }-a1b2c3-}
- Lazy Initialization with Synchronization: The instance is created only when it is needed, but synchronized access is required to ensure thread safety. This is a common approach in thread safe singleton c# implementations.
language="language-java"public class Singleton {-a1b2c3- private static Singleton instance;-a1b2c3--a1b2c3- private Singleton() {}-a1b2c3--a1b2c3- public static synchronized Singleton getInstance() {-a1b2c3- if (instance == null) {-a1b2c3- instance = new Singleton();-a1b2c3- }-a1b2c3- return instance;-a1b2c3- }-a1b2c3-}
- Double-Checked Locking: This approach reduces the overhead of acquiring a lock by first checking if the instance is null without synchronization. This method is often used in thread safe singleton c++ implementations.
language="language-java"public class Singleton {-a1b2c3- private static volatile Singleton instance;-a1b2c3--a1b2c3- private Singleton() {}-a1b2c3--a1b2c3- public static Singleton getInstance() {-a1b2c3- if (instance == null) {-a1b2c3- synchronized (Singleton.class) {-a1b2c3- if (instance == null) {-a1b2c3- instance = new Singleton();-a1b2c3- }-a1b2c3- }-a1b2c3- }-a1b2c3- return instance;-a1b2c3- }-a1b2c3-}
- Bill Pugh Singleton Design: This method uses a static inner helper class to hold the Singleton instance, which is only loaded when it is referenced. This is a widely accepted pattern in threadsafe singleton implementations.
language="language-java"public class Singleton {-a1b2c3- private Singleton() {}-a1b2c3--a1b2c3- private static class SingletonHelper {-a1b2c3- private static final Singleton INSTANCE = new Singleton();-a1b2c3- }-a1b2c3--a1b2c3- public static Singleton getInstance() {-a1b2c3- return SingletonHelper.INSTANCE;-a1b2c3- }-a1b2c3-}
10. Performance Optimization and Profiling
Performance optimization is essential in software development to ensure that applications run efficiently and effectively. Profiling helps identify bottlenecks and areas for improvement. Here are some strategies for performance optimization:
- Code Optimization: Refactor code to eliminate unnecessary computations and improve algorithm efficiency.
- Memory Management: Use memory efficiently by avoiding memory leaks and unnecessary object creation.
- Concurrency: Utilize multi-threading to improve performance, especially in I/O-bound applications. This is particularly relevant when implementing a threadsafe singleton.
- Caching: Implement caching mechanisms to store frequently accessed data, reducing the need for repeated calculations or database queries.
- Database Optimization: Optimize database queries and use indexing to speed up data retrieval.
- Profiling Tools: Use profiling tools like JProfiler, VisualVM, or YourKit to analyze application performance and identify bottlenecks.
10.1. Benchmarking Concurrent Code
Benchmarking concurrent code is crucial to understand its performance under various conditions. Here are steps to effectively benchmark concurrent code:
- Define Metrics: Determine what metrics are important (e.g., response time, throughput).
- Choose a Benchmarking Framework: Use frameworks like JMH (Java Microbenchmark Harness) for Java applications.
- Set Up Test Scenarios: Create scenarios that simulate real-world usage patterns.
- Run Benchmarks: Execute the benchmarks multiple times to gather reliable data.
- Analyze Results: Review the results to identify performance bottlenecks and areas for improvement.
- Iterate: Make necessary code optimizations and re-run benchmarks to measure improvements.
By following these guidelines, developers can ensure that their applications are not only functional but also optimized for performance in a concurrent environment.
At Rapid Innovation, we understand the importance of these principles in delivering high-quality software solutions. Our expertise in AI and Blockchain development allows us to implement these best practices effectively, ensuring that your applications are robust, efficient, and scalable. By partnering with us, you can expect greater ROI through optimized performance, reduced operational costs, and enhanced user satisfaction. Let us help you achieve your goals efficiently and effectively.
10.2. Identifying and Resolving Bottlenecks
Bottlenecks in a system can significantly hinder performance and efficiency. Identifying and resolving these bottlenecks is crucial for optimizing application performance, and at Rapid Innovation, we specialize in helping our clients achieve this.
- Monitor Performance Metrics: We utilize advanced tools like Application Performance Management (APM) to track response times, CPU usage, memory consumption, and I/O operations, ensuring that your application runs smoothly.
- Analyze Logs: Our team reviews application logs to identify slow queries, errors, or unusual patterns that may indicate a bottleneck, allowing us to proactively address issues before they escalate.
- Profile the Application: We employ profiling tools to analyze code execution and identify functions or methods that consume excessive resources, enabling targeted optimizations.
- Load Testing: By simulating high traffic, we observe how your system behaves under stress and pinpoint areas that may fail to scale, ensuring that your application can handle increased demand.
- Database Optimization: Our experts examine database queries for inefficiencies, such as missing indexes or poorly structured queries, to enhance performance.
- Code Review: We conduct regular code reviews to identify inefficient algorithms or data structures that may slow down performance, ensuring your codebase remains optimized.
Resolving bottlenecks often involves:
- Refactoring Code: We optimize algorithms and data structures to improve efficiency, leading to faster application performance.
- Scaling Resources: Our team can increase server capacity or distribute load across multiple servers, ensuring your application can handle growth.
- Caching Strategies: We implement caching mechanisms to reduce load on databases and improve response times, resulting in a more responsive user experience.
10.3. Cache-Friendly Concurrent Algorithms
Cache-friendly concurrent algorithms are designed to optimize the use of CPU caches, which can significantly enhance performance in multi-threaded environments. At Rapid Innovation, we leverage these techniques to maximize efficiency for our clients.
- Data Locality: We structure data to maximize spatial and temporal locality, ensuring that frequently accessed data is stored close together in memory.
- Minimize False Sharing: Our solutions avoid situations where multiple threads modify variables that reside on the same cache line, leading to unnecessary cache invalidation.
- Use Lock-Free Data Structures: We implement data structures that allow multiple threads to operate without locks, reducing contention and improving throughput.
- Batch Processing: Our approach includes processing data in batches to minimize cache misses and improve cache utilization.
- Thread Affinity: We bind threads to specific CPU cores to take advantage of cache locality, reducing the overhead of cache misses.
Example of a cache-friendly algorithm:
language="language-python"def cache_friendly_sum(array):-a1b2c3- total = 0-a1b2c3- for i in range(len(array)):-a1b2c3- total += array[i]-a1b2c3- return total
- Use of Arrays: We prefer arrays over linked lists due to their contiguous memory allocation, which is more cache-friendly.
- Parallel Processing: Our strategies involve dividing the array into chunks and processing them in parallel, ensuring that each thread works on a separate cache line.
10.4. Scalability Analysis
Scalability analysis is essential for understanding how a system can handle increased loads and how it can be improved to accommodate growth. Rapid Innovation provides comprehensive scalability analysis to ensure your systems are future-ready.
- Vertical Scaling: We assess the potential for upgrading existing hardware (CPU, RAM) to improve performance.
- Horizontal Scaling: Our team evaluates the ability to add more machines to distribute the load effectively, ensuring your application can grow seamlessly.
- Load Balancing: We implement load balancers to distribute incoming traffic evenly across servers, preventing any single server from becoming a bottleneck.
- Microservices Architecture: We consider breaking down monolithic applications into microservices to allow independent scaling of components, enhancing flexibility and performance.
- Performance Testing: Our rigorous stress tests determine the maximum load your system can handle before performance degrades, providing valuable insights for optimization.
Key metrics to analyze include:
- Throughput: We measure the number of transactions processed in a given time frame to ensure your application meets business demands.
- Latency: Our monitoring of the time taken to process requests under varying loads helps identify potential performance issues.
- Resource Utilization: We track CPU, memory, and network usage to identify potential scaling issues, ensuring your infrastructure is optimized.
By conducting a thorough scalability analysis, organizations can ensure their systems are prepared for future growth and can maintain performance under increased demand. Partnering with Rapid Innovation means you can expect greater ROI through enhanced performance, efficiency, and scalability of your applications, including application performance optimization and network performance optimization. Let us help you achieve your goals effectively and efficiently through our application performance optimization services and app performance optimization strategies. Debugging concurrent programs is a critical aspect of software development, especially as applications become more complex and rely on multi-threading and parallel processing. At Rapid Innovation, we understand the challenges that come with these complexities and are here to provide expert concurrent programming solutions that help you achieve your goals efficiently and effectively. This section will cover race condition detection and deadlock prevention and detection, showcasing how our services can enhance your development process.
11.1. Race Condition Detection
Race conditions occur when two or more threads access shared data and try to change it at the same time. The final outcome depends on the timing of their execution, which can lead to unpredictable behavior and bugs that are difficult to reproduce. Our team at Rapid Innovation employs a variety of techniques to help you detect and resolve race conditions, ensuring a smoother development process and greater ROI.
To detect race conditions, developers can use several techniques:
- Static Analysis Tools: These tools analyze the code without executing it to find potential race conditions. Examples include:
- ThreadSanitizer
- FindBugs
- Coverity
- Dynamic Analysis Tools: These tools monitor the program during execution to identify race conditions. They can provide real-time feedback and help pinpoint the exact location of the issue. Examples include:
- Helgrind
- Intel Inspector
- Code Reviews: Regular code reviews can help identify potential race conditions by having multiple eyes on the code. Look for:
- Shared variables
- Unsynchronized access to shared resources
- Testing: Implementing stress tests and concurrency tests can help reveal race conditions. Use:
- Randomized testing to increase the likelihood of encountering race conditions.
- Tools like JUnit or NUnit for unit testing in multi-threaded environments.
- Logging: Adding detailed logging can help trace the execution flow and identify where race conditions occur. Consider:
- Logging thread IDs
- Timestamps for operations on shared resources
By leveraging these techniques, Rapid Innovation ensures that your applications are robust and reliable, ultimately leading to a higher return on investment.
11.2. Deadlock Prevention and Detection
Deadlocks occur when two or more threads are blocked forever, each waiting for the other to release a resource. Preventing and detecting deadlocks is essential for maintaining application performance. Our expertise in this area allows us to implement effective strategies that keep your applications running smoothly.
To prevent deadlocks, consider the following strategies:
- Resource Ordering: Always acquire resources in a predefined order. This reduces the chances of circular wait conditions. For example:
- If Thread A needs Resource 1 and Resource 2, always acquire Resource 1 first.
- Timeouts: Implement timeouts when trying to acquire resources. If a thread cannot acquire a resource within a specified time, it should release any resources it holds and retry later.
- Lock Hierarchies: Establish a hierarchy for locks and ensure that threads acquire locks in a consistent order. This prevents circular wait conditions.
- Avoid Nested Locks: Minimize the use of nested locks, as they increase the complexity and likelihood of deadlocks.
To detect deadlocks, you can use:
- Deadlock Detection Algorithms: Implement algorithms that periodically check for deadlocks in the system. Common algorithms include:
- Wait-for Graph
- Resource Allocation Graph
- Monitoring Tools: Use monitoring tools that can detect deadlocks in real-time. Examples include:
- VisualVM
- JConsole
- Logging and Alerts: Implement logging to capture thread states and resource allocation. Set up alerts to notify developers when a deadlock is detected.
By employing these techniques for race condition detection and deadlock prevention and detection, Rapid Innovation can significantly improve the reliability and performance of your concurrent programming solutions. Partnering with us means you can expect enhanced application stability, reduced development time, and ultimately, a greater return on your investment. Let us help you navigate the complexities of software development with our expert solutions.
11.3. Using LLDB and GDB for Concurrent Debugging
At Rapid Innovation, we understand that debugging multi-threaded applications can be a complex task. That's why we leverage powerful concurrent debugging tools like LLDB and GDB to help our clients efficiently identify and resolve issues in their software. These tools allow developers to inspect and control the execution of programs, making it easier to pinpoint problems in concurrent systems.
LLDB:
- LLDB is the default debugger for the LLVM project and is designed to be highly extensible.
- It provides a command-line interface and can be integrated with IDEs like Xcode.
- Key features for concurrent debugging include:
- Thread control: You can switch between threads to inspect their state.
- Breakpoints: Set breakpoints on specific threads or conditions.
- Watchpoints: Monitor variables for changes across threads.
GDB:
- GDB is the GNU Project debugger and supports various programming languages.
- It is widely used in Linux environments and offers robust features for concurrent debugging.
- Key features include:
- Thread management: GDB allows you to list, select, and control threads.
- Conditional breakpoints: Set breakpoints that only trigger under specific conditions.
- Backtrace: View the call stack of all threads to identify where issues occur.
Steps to Use LLDB for Concurrent Debugging:
- Compile your program with debugging symbols (e.g.,
-gflag). - Launch LLDB with your executable:
language="language-bash"lldb ./your_program
- Set breakpoints on specific threads:
language="language-bash"breakpoint set --name your_function
- Run the program:
language="language-bash"run
- Switch between threads:
language="language-bash"thread select <thread_id>
- Inspect variables:
language="language-bash"frame variable
Steps to Use GDB for Concurrent Debugging:
- Compile your program with debugging symbols.
- Start GDB with your executable:
language="language-bash"gdb ./your_program
- List threads:
language="language-bash"info threads
- Select a thread:
language="language-bash"thread <thread_id>
- Set a conditional breakpoint:
language="language-bash"break your_function if condition
- Run the program:
language="language-bash"run
11.4. Logging and Tracing in Concurrent Systems
At Rapid Innovation, we recognize that logging and tracing are essential techniques for monitoring and diagnosing issues in concurrent systems. These practices provide valuable insights into application behavior, especially when multiple threads or processes are involved.
Logging:
- Logging involves recording events that occur during the execution of a program.
- It helps in tracking the flow of execution and identifying errors.
- Best practices for logging in concurrent systems include:
- Use thread-safe logging libraries to avoid race conditions.
- Include timestamps and thread identifiers in log messages.
- Log at different levels (e.g., INFO, DEBUG, ERROR) to filter messages based on severity.
Tracing:
- Tracing provides a more detailed view of the execution flow, capturing the sequence of events.
- It is particularly useful for performance analysis and debugging complex interactions.
- Techniques for effective tracing include:
- Use tracing frameworks to instrument your code.
- Capture context information to correlate events across threads.
- Analyze trace data to identify bottlenecks and optimize performance.
Steps for Implementing Logging:
- Choose a logging library suitable for your application.
- Configure the logger to handle concurrent writes.
- Add logging statements in critical sections of your code:
language="language-python"logger.info("Thread %s started processing", thread_id)
Steps for Implementing Tracing:
- Select a tracing framework suitable for your application.
- Instrument your code to create spans for significant operations:
language="language-python"with tracer.start_span("operation_name") as span:-a1b2c3- # Perform operation
- Collect and analyze trace data to improve system performance.
12. Real-World Applications and Case Studies
Real-world applications of concurrent debugging, logging, and tracing can be seen in various industries, including finance, gaming, and web services. For instance, companies like Netflix and Uber utilize these techniques to ensure their services remain reliable and performant under heavy loads. By implementing robust logging and tracing, they can quickly identify and resolve issues, leading to improved user experiences and system stability.
At Rapid Innovation, we are committed to helping our clients achieve greater ROI through effective debugging and monitoring strategies. By partnering with us, you can expect enhanced system reliability, faster issue resolution, and ultimately, a more efficient development process. Let us help you navigate the complexities of concurrent systems and drive your business forward.
12.1. Building a Concurrent Web Server
At Rapid Innovation, we understand that a concurrent web server is crucial for businesses aiming to provide a seamless user experience, especially during high traffic periods. Our expertise in developing such systems ensures that multiple clients can connect and interact with your server simultaneously, enhancing responsiveness and efficiency.
- Choose a programming language: We can guide you in selecting the most suitable language for your needs, with popular choices including Python, Node.js, Java, and Go.
- Select a concurrency model: We help you evaluate options such as:
- Multi-threading
- Asynchronous I/O
- Event-driven architecture
- Set up the server: Our team will utilize libraries or frameworks that support concurrency (e.g., Flask for Python, Express for Node.js) to implement a robust HTTP server that listens for incoming requests.
- Handle requests concurrently: We can implement strategies for multi-threading by creating a new thread for each incoming request or using asynchronous I/O with callbacks or promises to handle requests without blocking.
- Test the server: Our experts will employ tools like Apache Benchmark or JMeter to simulate multiple clients and measure performance, ensuring your concurrent web server can handle the expected load.
- Optimize performance: We will implement caching strategies to reduce load times and utilize load balancers to distribute traffic across multiple server instances, maximizing efficiency.
12.2. Implementing a Parallel Image Processing Pipeline
In today's fast-paced digital landscape, a parallel image processing pipeline is essential for businesses that require rapid image manipulation. At Rapid Innovation, we specialize in creating systems that allow for the simultaneous processing of multiple images, significantly speeding up tasks such as filtering, resizing, or format conversion.
- Choose a programming language and libraries: We can assist you in selecting the right tools, such as Python with libraries like OpenCV or PIL, or frameworks like TensorFlow for more complex tasks.
- Set up the processing environment: Our team will ensure that you have the necessary libraries and dependencies installed, and that your multi-core processor is optimized for parallel processing.
- Design the pipeline: We will help you define the sequence of processing steps (e.g., load image, apply filters, save output) and use a queue to manage incoming images, distributing them to worker threads or processes.
- Implement parallel processing: Our experts will utilize threading or multiprocessing libraries to create efficient worker threads/processes, ensuring each worker takes an image from the queue, processes it, and saves the result.
- Monitor and optimize: We will track processing times and resource usage to identify bottlenecks, adjusting the number of workers based on available CPU cores and workload to maximize throughput.
12.3. Creating a Distributed Key-Value Store
For businesses looking to scale their data storage solutions, a distributed key-value store is an ideal choice. At Rapid Innovation, we have the expertise to design and implement systems that allow data to be stored across multiple nodes, providing both scalability and fault tolerance.
- Choose a technology stack: We will help you select the best options for your needs, including Apache Cassandra, Redis, or Amazon DynamoDB.
- Design the architecture: Our team will assist you in deciding on the number of nodes and their roles (e.g., master/slave, peer-to-peer) and defining how data will be partitioned and replicated across nodes.
- Set up the environment: We will ensure that the chosen key-value store is installed on each node and that network settings are configured for seamless communication.
- Implement data storage and retrieval: Our experts will utilize the provided APIs to store and retrieve key-value pairs, implementing consistency models (e.g., eventual consistency, strong consistency) based on your application needs.
- Monitor and maintain: We will employ monitoring tools to track the performance and health of the nodes, implementing backup and recovery strategies to protect against data loss.
By partnering with Rapid Innovation, you can confidently build a concurrent web server, implement a parallel image processing pipeline, and create a distributed key-value store, all tailored to meet your specific performance and scalability requirements. Our commitment to delivering efficient and effective solutions ensures that you achieve greater ROI and stay ahead in your industry.
12.4. Developing a Multi-threaded Game Engine
At Rapid Innovation, we recognize that creating a multithreaded game engine development is essential for modern games, as it allows for better performance and responsiveness. A multithreaded engine can handle various tasks simultaneously, such as rendering graphics, processing input, and managing game logic, ultimately leading to a more engaging user experience.
Key components of a multithreaded game engine include:
- Game Loop: The core of the engine that updates game state and renders graphics. It can be divided into multiple threads for different tasks, ensuring that the game runs smoothly.
- Thread Management: Efficiently managing threads is crucial. We recommend using thread pools to minimize the overhead of creating and destroying threads, which can significantly enhance performance.
- Synchronization: Ensuring that shared resources are accessed safely is vital. Utilizing mutexes, semaphores, or other synchronization primitives can prevent race conditions and maintain stability.
- Task Scheduling: Implementing a task scheduler to distribute workloads across threads can help balance CPU usage and improve overall performance.
- Asynchronous Loading: Loading assets (textures, sounds, etc.) in the background is essential to avoid stalling the main game loop, allowing for a seamless gaming experience.
- Profiling and Optimization: Regularly profiling the engine to identify bottlenecks is crucial. Optimizing critical sections of code can lead to significant performance improvements.
- Cross-Platform Compatibility: Ensuring that the engine works on various platforms by using platform-agnostic libraries and APIs is key to reaching a broader audience.
13. Best Practices and Design Patterns
When developing a multithreaded game engine, adhering to best practices and design patterns can significantly enhance code quality and maintainability.
- Use of Design Patterns: Implementing design patterns like Singleton, Observer, and Component can help organize code effectively, making it easier to manage and scale.
- Separation of Concerns: Keeping different aspects of the game engine (graphics, physics, input) modular simplifies management and testing, leading to a more robust product.
- Error Handling: Implementing robust error handling to manage exceptions ensures that the engine remains stable, which is critical for user satisfaction.
- Documentation: Maintaining clear documentation for the codebase helps new developers understand the architecture and design choices, facilitating smoother onboarding.
- Testing: Regularly testing the engine for performance and stability is essential. Utilizing unit tests and integration tests can catch issues early, reducing long-term costs.
- Version Control: Using version control systems (like Git) to manage changes and collaborate with other developers enhances team efficiency and project organization.
- Continuous Integration: Setting up a CI/CD pipeline to automate testing and deployment processes can streamline development and improve product quality.
13.1. Choosing Between Threads, Async, and Parallelism
When developing a multithreaded game engine, it's essential to choose the right concurrency model. Each approach has its advantages and disadvantages.
- Threads:
- Pros: Fine-grained control over execution, suitable for CPU-bound tasks.
- Cons: Complexity in managing thread lifecycle and synchronization.
- Asynchronous Programming:
- Pros: Simplifies code for I/O-bound tasks, non-blocking operations.
- Cons: Can lead to callback hell and harder debugging.
- Parallelism:
- Pros: Efficiently utilizes multi-core processors, ideal for data parallel tasks.
- Cons: Requires careful design to avoid data races and ensure thread safety.
When to use each approach:
- Use threads for tasks that require real-time processing, such as physics calculations or rendering.
- Use asynchronous programming for tasks that involve waiting for I/O operations, like loading assets.
- Use parallelism for tasks that can be broken down into smaller, independent units of work, such as processing large datasets.
By understanding these concepts and implementing best practices, developers can create a robust and efficient multithreaded game engine that enhances the gaming experience. At Rapid Innovation, we are committed to helping our clients achieve their goals efficiently and effectively, ensuring a greater return on investment through our expertise in AI and Blockchain development. Partnering with us means you can expect improved performance, reduced development time, and a product that stands out in the competitive gaming market.
13.2. Error Handling in Concurrent Systems
At Rapid Innovation, we understand that error handling in concurrent systems is crucial due to the complexity introduced by multiple threads or processes running simultaneously. Errors can arise from race conditions, deadlocks, or resource contention, making it essential to implement robust error handling strategies to ensure system reliability and performance.
- Identify potential errors: We help clients understand the types of errors that can occur in concurrent systems, such as:
- Race conditions
- Deadlocks
- Resource starvation
- Use try-catch blocks: Our development team implements try-catch mechanisms to handle exceptions gracefully. This allows the system to recover from errors without crashing, ensuring a seamless user experience.
- Logging: We maintain detailed logs of errors to facilitate debugging. Our logging includes:
- Timestamp
- Thread ID
- Error message
- Graceful degradation: We design systems to continue functioning at a reduced capacity in case of errors. This can involve:
- Fallback mechanisms
- Alternative resource allocation
- Testing for errors: Our rigorous testing protocols ensure that the system is regularly tested under various conditions to identify potential error scenarios. We utilize tools like:
- Stress testing
- Load testing
- Use of monitoring tools: We implement monitoring solutions to detect and alert on errors in real-time, enabling proactive error management and minimizing downtime.
13.3. Testing Concurrent Code
Testing concurrent code is inherently more challenging than testing sequential code due to the non-deterministic nature of concurrent execution. At Rapid Innovation, we employ effective testing strategies to ensure the reliability of concurrent systems.
- Unit testing: Our team writes unit tests for individual components, ensuring they function correctly in isolation. We utilize frameworks like:
- JUnit for Java
- NUnit for .NET
- Integration testing: We test how different components interact in a concurrent environment, focusing on:
- Shared resources
- Synchronization mechanisms
- Concurrency testing tools: We utilize specialized tools designed for testing concurrent applications, such as:
- ThreadSanitizer
- Helgrind
- Simulate race conditions: Our testing includes creating scenarios that intentionally introduce race conditions to test the system's robustness. This can be done by:
- Running tests with varying thread counts
- Introducing delays or random sleeps
- Stress testing: We subject the system to high loads to identify performance bottlenecks and potential failures, monitoring:
- Response times
- Resource utilization
- Code reviews: Our thorough code reviews focus on concurrency issues, ensuring:
- Proper use of locks
- Identification of potential deadlocks
13.4. Documentation and Maintainability
Documentation and maintainability are vital for the long-term success of concurrent systems. At Rapid Innovation, we prioritize clear documentation and maintainability to ensure that systems can evolve over time.
- Code comments: Our developers write clear and concise comments in the code to explain complex logic, especially around concurrency mechanisms.
- Design documentation: We create comprehensive design documents that outline:
- System architecture
- Thread interactions
- Error handling strategies
- API documentation: We provide detailed API documentation for any public interfaces, including:
- Input and output specifications
- Thread safety guarantees
- Version control: We utilize version control systems (e.g., Git) to track changes and maintain a history of the codebase, aiding in:
- Collaboration
- Rollback capabilities
- Refactoring: Our team regularly refactors code to improve readability and maintainability, focusing on:
- Reducing complexity
- Enhancing modularity
- Automated testing: We implement automated tests to ensure that changes do not introduce new errors, including:
- Unit tests
- Integration tests
- Continuous integration: We use CI/CD pipelines to automate testing and deployment processes, ensuring that the codebase remains stable and maintainable over time.
By partnering with Rapid Innovation, clients can expect enhanced system reliability, reduced downtime, and greater ROI through our comprehensive development and consulting solutions. Our expertise in AI and Blockchain technologies positions us as a valuable ally in achieving your business goals efficiently and effectively.
14. Rust Ecosystem for Concurrency and Parallelism
At Rapid Innovation, we understand that modern applications require robust solutions for concurrency and parallelism. Rust is designed with these principles in mind, providing developers with tools to write safe and efficient concurrent code. The language's ownership model and type system help prevent data races, making it a strong choice for rust concurrency and concurrent programming.
14.1. Popular Crates for Concurrent Programming
Rust's ecosystem includes several popular crates that facilitate concurrency in Rust. Here are some of the most notable ones:
- Tokio:
- An asynchronous runtime for Rust, enabling developers to write non-blocking applications.
- Ideal for building network applications, it provides a rich set of features, including timers, I/O, and task scheduling.
- async-std:
- A library that provides an asynchronous version of the standard library.
- It allows developers to write asynchronous code using familiar APIs, making it easier to transition from synchronous to asynchronous programming.
- Rayon:
- A data parallelism library that simplifies parallel processing in Rust.
- It allows developers to easily convert sequential iterators into parallel iterators, enabling efficient data processing across multiple threads.
- Crossbeam:
- A crate that provides advanced concurrency tools, such as scoped threads and channels.
- It enhances the standard library's concurrency features, allowing for more complex concurrent programming patterns.
- Mio:
- A low-level, event-driven I/O library for building high-performance network applications.
- It provides a non-blocking API for handling I/O operations, making it suitable for building scalable servers.
- std::thread:
- The standard library's built-in support for creating and managing threads.
- It allows developers to spawn threads and manage their execution, providing a straightforward way to achieve concurrency.
14.2. Integrating with C and C++ Concurrent Code
Integrating Rust with existing C and C++ code can be beneficial for leveraging existing libraries or systems. Rust provides Foreign Function Interface (FFI) capabilities that allow seamless interaction with C and C++ code, including rust fearless concurrency and concurrent programming constructs.
- Using Rust's FFI:
- Define Rust functions that can be called from C/C++.
- Use
extern "C"to specify the calling convention.
- Creating a C-compatible library:
- Write Rust code and compile it as a shared library.
- Use
cargo build --releaseto generate the library.
- Example of a simple Rust function:
language="language-rust"#[no_mangle]-a1b2c3-pub extern "C" fn rust_function() {-a1b2c3- // Rust code that can be called from C/C++-a1b2c3-}
- Calling Rust from C:
- Include the Rust header file in your C/C++ code.
- Link against the compiled Rust library.
- Handling concurrency:
- Use Rust's concurrency features (like threads or async) within the Rust code.
- Ensure proper synchronization when sharing data between Rust and C/C++.
- Example of a C function calling Rust:
language="language-c"#include "rust_lib.h"-a1b2c3--a1b2c3-int main() {-a1b2c3- rust_function(); // Call the Rust function-a1b2c3- return 0;-a1b2c3-}
By leveraging Rust's concurrency features alongside C and C++ code, developers can create robust applications that benefit from both languages' strengths. This integration allows for efficient resource management and improved performance in rust concurrent programming scenarios.
At Rapid Innovation, we are committed to helping our clients harness the power of Rust and its ecosystem to achieve greater ROI. By partnering with us, you can expect enhanced application performance, reduced development time, and a significant competitive edge in your industry. Let us guide you through the complexities of modern software development, ensuring that your projects are executed efficiently and effectively.
14.3. Rust in Distributed Systems
At Rapid Innovation, we recognize that Rust is increasingly being adopted in distributed systems due to its unique features that enhance safety and performance. The language's emphasis on memory safety without a garbage collector makes it particularly suitable for building reliable and efficient distributed applications.
- Memory Safety: Rust's ownership model ensures that data races and memory leaks are minimized, which is crucial in distributed systems where multiple components interact concurrently. By leveraging Rust, our clients can significantly reduce the risk of costly errors and downtime.
- Concurrency: Rust's concurrency model allows developers to write safe concurrent code, making it easier to manage multiple threads and processes without the risk of data corruption. This capability enables our clients to build scalable applications that can handle increased loads without compromising performance.
- Performance: Rust's zero-cost abstractions mean that developers can write high-level code without sacrificing performance, which is essential for distributed systems that require low latency and high throughput. Our expertise in Rust allows us to optimize applications for maximum efficiency, leading to greater ROI for our clients.
Rust is being used in various distributed systems projects, such as:
- Tokio: An asynchronous runtime for Rust that enables building fast and reliable network applications. Our team can help clients implement Tokio to enhance their application's responsiveness and scalability.
- Actix: A powerful actor framework for Rust that simplifies the development of concurrent applications. We can guide clients in utilizing Actix to streamline their development processes and improve application performance.
- Rust-based microservices: Many organizations are adopting Rust for building microservices due to its performance and safety features. Our consulting services can assist clients in transitioning to Rust-based microservices, ensuring a smooth and efficient implementation.
14.4. Future Trends in Rust Concurrency
As Rust continues to evolve, several trends are emerging in the realm of concurrency that will shape its future:
- Increased Adoption of Async/Await: The async/await syntax is becoming more prevalent, allowing developers to write asynchronous code that is easier to read and maintain. This trend will likely lead to more libraries and frameworks supporting asynchronous programming, which we can help clients navigate.
- Improved Tooling: The Rust community is actively working on enhancing tooling for concurrency, including better debuggers and profilers that can help developers identify and resolve concurrency issues more effectively. Our firm stays updated on these advancements to provide clients with the best tools for their projects.
- Integration with Other Languages: As Rust gains popularity, there will be more efforts to integrate Rust with other programming languages, allowing developers to leverage Rust's concurrency features in existing codebases. We can assist clients in integrating Rust into their current systems, maximizing their investment in technology.
To implement concurrency in Rust, developers can follow these steps:
- Set up a Rust project: Use Cargo to create a new Rust project.
- Add dependencies: Include libraries like Tokio or async-std in your
Cargo.tomlfile. - Write asynchronous functions: Use the
async fnsyntax to define asynchronous functions. - Use
.await: Call asynchronous functions with the.awaitkeyword to yield control until the function completes. - Run the async runtime: Use the Tokio or async-std runtime to execute your asynchronous code.
language="language-rust"// Example of an asynchronous function in Rust-a1b2c3--a1b2c3-use tokio;-a1b2c3--a1b2c3-#[tokio::main]-a1b2c3-async fn main() {-a1b2c3- let result = async_function().await;-a1b2c3- println!("Result: {}", result);-a1b2c3-}-a1b2c3--a1b2c3-async fn async_function() -> i32 {-a1b2c3- // Simulate some asynchronous work-a1b2c3- 42-a1b2c3-}
15. Conclusion and Next Steps
As Rust continues to gain traction in the development of distributed systems and concurrent applications, developers should consider exploring its features and capabilities. The language's focus on safety, performance, and concurrency makes it an excellent choice for building robust applications.
Next steps for developers interested in Rust include:
- Learning Rust: Familiarize yourself with Rust's syntax and concepts through online resources and documentation.
- Experimenting with Libraries: Explore libraries like Tokio and Actix to understand how they can be used to build concurrent applications.
- Contributing to the Community: Engage with the Rust community by contributing to open-source projects or participating in forums and discussions.
At Rapid Innovation, we are committed to helping our clients achieve their goals efficiently and effectively. By partnering with us, you can expect enhanced performance, reduced risks, and a greater return on investment in your technology initiatives. Let us guide you through the complexities of Rust for distributed systems and distributed computing to unlock your project's full potential.
15.1. Recap of Key Concepts
In the realm of concurrent programming in Rust, several key concepts are essential for understanding how to effectively manage multiple threads and ensure safe data access. Here’s a recap of those concepts:
- Ownership and Borrowing: Rust’s ownership model ensures memory safety without a garbage collector. Understanding how ownership and borrowing work is crucial for managing data across threads.
- Data Races: A data race occurs when two or more threads access shared data simultaneously, and at least one thread modifies the data. Rust prevents data races at compile time through its strict borrowing rules.
- Mutexes and Locks: Mutexes (mutual exclusions) are used to protect shared data. When a thread wants to access shared data, it must first acquire a lock on the mutex. This ensures that only one thread can access the data at a time.
- Channels: Rust provides channels for message passing between threads. This allows threads to communicate safely without sharing memory, adhering to the principle of ownership.
- Async Programming: Rust also supports asynchronous programming, allowing for non-blocking operations. This is particularly useful for I/O-bound tasks where waiting for operations to complete can be inefficient.
15.2. Continuing Your Concurrent Rust Journey
As you delve deeper into concurrency in Rust, consider the following steps to enhance your skills and knowledge:
- Explore the Standard Library: Familiarize yourself with Rust’s standard library, particularly the
std::thread,std::sync, andstd::sync::mpscmodules. These provide essential tools for thread management and synchronization. - Practice with Examples: Implement small projects that utilize concurrency. For instance, create a multi-threaded web scraper or a concurrent file processor. This hands-on experience will solidify your understanding of rust concurrency.
- Learn about Crates: Explore popular crates like
tokiofor asynchronous programming andrayonfor data parallelism. These libraries can simplify complex concurrent tasks and improve performance. - Read Documentation and Books: Resources like "The Rust Programming Language" and "Programming Rust" provide in-depth knowledge about concurrency in Rust. The official Rust documentation is also a valuable resource.
- Join the Community: Engage with the Rust community through forums, Discord channels, or local meetups. Sharing experiences and challenges can provide insights and foster learning.
15.3. Contributing to the Rust Concurrency Ecosystem
Contributing to the Rust concurrency ecosystem can be a rewarding experience. Here are ways to get involved:
- Open Source Contributions: Look for open-source projects that focus on concurrent programming in Rust. Contributing code, documentation, or bug fixes can help improve these projects and enhance your skills.
- Write Articles or Tutorials: Share your knowledge by writing articles or creating tutorials on rust fearless concurrency topics. This not only helps others but also reinforces your understanding.
- Participate in Discussions: Join discussions on platforms like GitHub, Reddit, or the Rust Users Forum. Engaging in conversations about concurrency challenges and solutions can lead to new insights.
- Attend Conferences and Meetups: Participate in Rust conferences or local meetups. These events often feature talks on rust concurrent programming and provide networking opportunities with other Rustaceans.
- Create Your Own Projects: Develop your own libraries or tools that address specific concurrency challenges. Sharing your work on platforms like GitHub can contribute to the community and showcase your skills.
By focusing on these areas, you can deepen your understanding of concurrent programming in Rust and contribute meaningfully to the ecosystem.
At Rapid Innovation, we leverage these principles of rust programming to deliver robust, efficient, and scalable solutions for our clients. Our expertise in AI and Blockchain development ensures that your projects are not only technically sound but also aligned with your business goals, ultimately leading to greater ROI. Partnering with us means you can expect enhanced productivity, reduced time-to-market, and innovative solutions tailored to your needs. Let us help you navigate the complexities of technology and achieve your objectives effectively.













