





1. What are Spark Data Structures?
Apache Spark is a powerful open-source distributed computing system that provides various data structures to handle large-scale data processing. Spark data structures are designed to facilitate efficient data manipulation and analysis. The primary data structures in Spark include Resilient Distributed Datasets (RDDs), DataFrames, and Datasets. Each of these structures has unique characteristics and use cases, making them suitable for different types of data processing tasks.
- RDDs are the fundamental data structure in Spark, representing an immutable distributed collection of objects. They allow for low-level transformations and actions, providing fine-grained control over data processing.
- DataFrames are a higher-level abstraction built on top of RDDs, resembling tables in a relational database. They provide a more user-friendly API and support various optimizations, making them suitable for structured data.
- Datasets combine the benefits of RDDs and DataFrames, offering type safety and the ability to work with both structured and unstructured data.
1.1. What's the Difference Between RDDs, DataFrames, and Datasets?
Understanding the differences between RDDs, DataFrames, and Datasets is crucial for selecting the right data structure for your Spark applications.
- RDDs (Resilient Distributed Datasets) are immutable and distributed collections of objects. They provide low-level transformations and actions but lack built-in optimization features, making them suitable for unstructured data and complex data processing tasks.
- DataFrames are distributed collections of data organized into named columns. They are similar to tables in relational databases, allowing for SQL-like queries. DataFrames support optimizations through Catalyst query optimization and the Tungsten execution engine, making them ideal for structured data and data analysis tasks.
- Datasets are a combination of RDDs and DataFrames, providing the benefits of both. They are type-safe, allowing compile-time type checking, and support both structured and unstructured data, making them suitable for applications requiring both performance and type safety.
1.2. Benefits of Converting RDD to Structured Formats
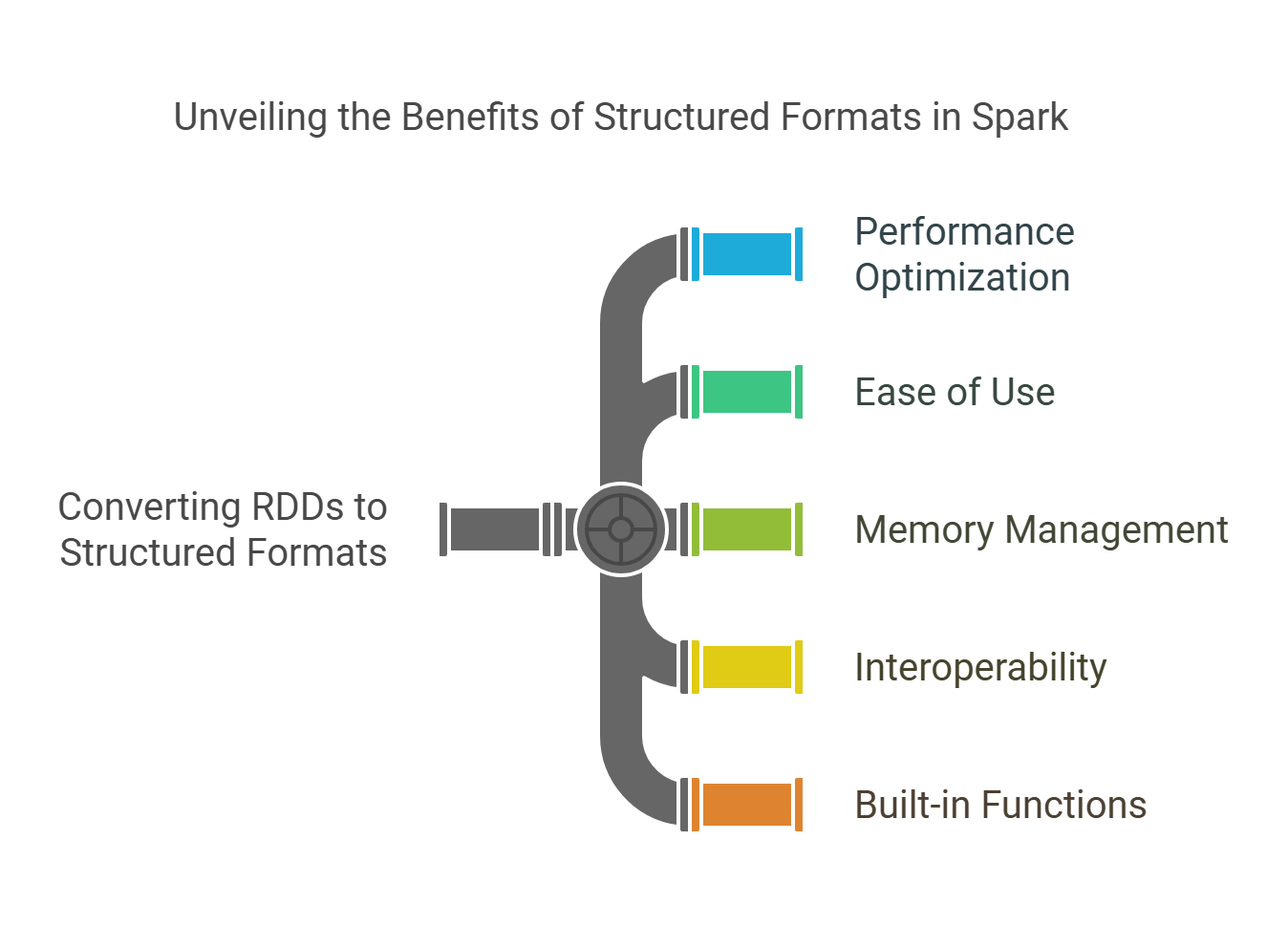
Converting RDDs to structured formats like DataFrames or Datasets can significantly enhance performance and ease of use. Here are some key benefits:
- Performance Optimization: DataFrames and Datasets leverage Spark's Catalyst optimizer, which can optimize query execution plans, leading to faster processing times.
- Ease of Use: DataFrames provide a more intuitive API, allowing users to perform complex data manipulations with less code compared to RDDs.
- Memory Management: Structured formats use Tungsten's off-heap memory management, which can lead to better memory utilization and reduced garbage collection overhead.
- Interoperability: DataFrames and Datasets can easily integrate with various data sources, including Hive, Avro, Parquet, and JSON, making data ingestion and processing more straightforward.
- Built-in Functions: DataFrames and Datasets come with a rich set of built-in functions for data manipulation, making it easier to perform operations like filtering, aggregation, and joining.
To convert RDDs to DataFrames or Datasets, follow these steps:
- Import necessary libraries:
language="language-python"from pyspark.sql import SparkSession
- Create a Spark session:
language="language-python"spark = SparkSession.builder.appName("RDD to DataFrame").getOrCreate()
- Create an RDD:
language="language-python"rdd = spark.sparkContext.parallelize([(1, "Alice"), (2, "Bob"), (3, "Cathy")])
- Convert RDD to DataFrame:
language="language-python"df = rdd.toDF(["id", "name"])
- Show the DataFrame:
language="language-python"df.show()
By understanding Spark data structures and their differences, you can make informed decisions on how to best utilize them for your data processing needs. At Rapid Innovation, we leverage these data structures, including pyspark data structures and rdd data structure, to help our clients optimize their data processing workflows, ensuring they achieve greater ROI through efficient data management and analysis. Our expertise in AI and Blockchain further enhances our ability to provide tailored solutions that align with your business goals. Additionally, we utilize tools like spark streaming dataframe and pyspark streaming dataframe for real-time data processing, and we can integrate with various data sources such as Kafka for streaming data ingestion.
1.3. How Does RDD Conversion Impact Business Performance?
Converting Resilient Distributed Datasets (RDDs) to DataFrames can significantly enhance business performance in various ways. DataFrames provide a higher-level abstraction over RDDs, allowing for more efficient data processing and analysis. Here are some key impacts:
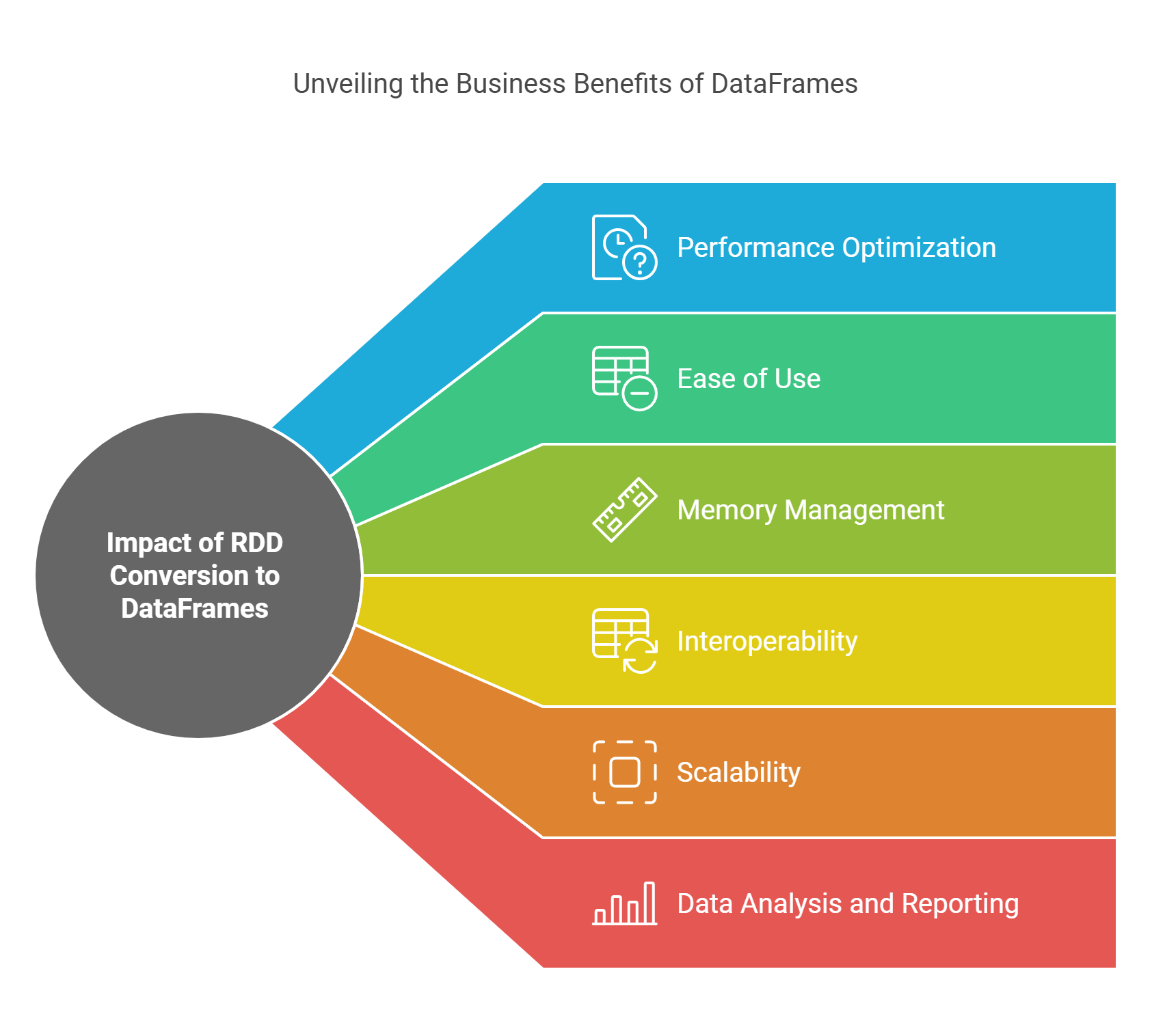
- Performance Optimization: DataFrames leverage Catalyst, Spark's query optimizer, which optimizes execution plans. This can lead to faster query execution compared to RDDs, which require manual optimization. By utilizing this optimization, Rapid Innovation can help clients achieve quicker insights, ultimately leading to better decision-making and increased ROI.
- Ease of Use: DataFrames come with a rich set of APIs and built-in functions that simplify data manipulation. This reduces the complexity of code, making it easier for data scientists and analysts to work with large datasets. Rapid Innovation's expertise in DataFrame operations can empower teams to focus on deriving value from data rather than getting bogged down in technical details.
- Memory Management: DataFrames use Tungsten, Spark's memory management and execution engine, which optimizes memory usage and speeds up processing. This can lead to reduced costs associated with cloud computing resources. By implementing DataFrames, Rapid Innovation can assist clients in optimizing their resource allocation, thereby enhancing cost efficiency.
- Interoperability: DataFrames can easily integrate with various data sources, including SQL databases, JSON, and Parquet files. This flexibility allows businesses to consolidate data from multiple sources for comprehensive analysis. Rapid Innovation can facilitate seamless integration, enabling clients to leverage their existing data infrastructure effectively.
- Scalability: As businesses grow, so do their data needs. DataFrames can handle larger datasets more efficiently than RDDs, making them suitable for scaling operations without a significant drop in performance. Rapid Innovation's solutions can ensure that clients are well-prepared to scale their data operations in line with business growth.
- Data Analysis and Reporting: With DataFrames, businesses can perform complex analytics and generate reports more efficiently. This can lead to quicker decision-making and improved business strategies. Rapid Innovation can provide tailored analytics solutions that help clients extract actionable insights from their data, driving better business outcomes.
2. How to Convert Spark RDD to DataFrame?
Converting an RDD to a DataFrame in Apache Spark is a straightforward process. The conversion allows you to take advantage of the optimizations and functionalities that DataFrames offer. Here’s how to do it:
- Import Required Libraries: Ensure you have the necessary Spark libraries imported in your environment.
- Create a Spark Session: You need an active Spark session to perform the conversion.
- Create an RDD: If you don’t already have an RDD, create one from a data source.
- Define a Schema: Specify the schema for the DataFrame, which defines the structure of the data.
- Convert RDD to DataFrame: Use the createDataFrame method to perform the conversion.
Here’s a code snippet to illustrate the conversion process:
language="language-python"from pyspark.sql import SparkSession-a1b2c3-from pyspark.sql.types import StructType, StructField, StringType, IntegerType-a1b2c3--a1b2c3-# Create a Spark session-a1b2c3-spark = SparkSession.builder.appName("RDD to DataFrame").getOrCreate()-a1b2c3--a1b2c3-# Create an RDD-a1b2c3-data = [("Alice", 1), ("Bob", 2), ("Cathy", 3)]-a1b2c3-rdd = spark.sparkContext.parallelize(data)-a1b2c3--a1b2c3-# Define a schema-a1b2c3-schema = StructType([-a1b2c3- StructField("Name", StringType(), True),-a1b2c3- StructField("Id", IntegerType(), True)-a1b2c3-])-a1b2c3--a1b2c3-# Convert RDD to DataFrame-a1b2c3-df = spark.createDataFrame(rdd, schema)-a1b2c3--a1b2c3-# Show the DataFrame-a1b2c3-df.show()
2.1. Step-by-Step Guide to Using createDataFrame
Using the createDataFrame method is essential for converting RDDs to DataFrames. Here’s a step-by-step guide:
- Step 1: Initialize Spark Session
Create a Spark session to interact with Spark. - Step 2: Create RDD
Use sparkContext.parallelize() to create an RDD from a list or other data sources. - Step 3: Define Schema
Use StructType and StructField to define the schema for your DataFrame. - Step 4: Call createDataFrame
Use the createDataFrame method, passing the RDD and schema as arguments. - Step 5: Display DataFrame
Use the show() method to display the contents of the DataFrame.
By following these steps, businesses can efficiently convert RDDs to DataFrames, unlocking the full potential of Spark for data processing and analysis. Rapid Innovation stands ready to assist clients in this transformation, ensuring they maximize their data's value and drive business success.
2.2. Schema Definition and Type Mapping
In Apache Spark, schema definition and type mapping are crucial for ensuring that data is processed correctly. A schema defines the structure of a DataFrame, including the names and types of its columns. This is particularly important when working with structured data, as it allows Spark to optimize query execution and memory usage.
- Defining a Schema: You can define a schema using the
StructTypeandStructFieldclasses. This allows you to specify the data types for each column explicitly.
language="language-python"from pyspark.sql.types import StructType, StructField, StringType, IntegerType-a1b2c3--a1b2c3-schema = StructType([-a1b2c3- StructField("name", StringType(), True),-a1b2c3- StructField("age", IntegerType(), True),-a1b2c3- StructField("city", StringType(), True)-a1b2c3-])
- Type Mapping: Spark supports various data types, including primitive types (e.g.,
IntegerType,StringType) and complex types (e.g.,ArrayType,MapType). When loading data, Spark automatically infers the schema, but you can also specify it manually for better control. - DataFrame Creation: Once the schema is defined, you can create a DataFrame by loading data from various sources like CSV, JSON, or Parquet.
language="language-python"df = spark.read.schema(schema).json("path/to/data.json")
This approach ensures that the data adheres to the defined schema, preventing issues during processing.
2.3. Handling Complex Data Types and Nested Structures
Handling complex data types and nested structures in Spark is essential for working with real-world data, which often includes arrays, maps, and nested JSON objects. Spark provides robust support for these data types, allowing for efficient querying and manipulation.
- Complex Data Types: Spark supports several complex data types, including:
- ArrayType: Represents an array of elements.
- MapType: Represents a key-value pair.
- StructType: Represents a structured record.
- Defining Nested Structures: You can define nested structures using
StructTypewithin anotherStructType. This is useful for representing hierarchical data.
language="language-python"from pyspark.sql.types import ArrayType-a1b2c3--a1b2c3-nested_schema = StructType([-a1b2c3- StructField("name", StringType(), True),-a1b2c3- StructField("age", IntegerType(), True),-a1b2c3- StructField("addresses", ArrayType(StructType([-a1b2c3- StructField("city", StringType(), True),-a1b2c3- StructField("zip", StringType(), True)-a1b2c3- ]), True))-a1b2c3-])
- Querying Nested Data: You can access nested fields using dot notation. For example, to select the city from the addresses array:
language="language-python"df.select("name", "addresses.city").show()
This capability allows for flexible data manipulation and analysis, making Spark a powerful tool for big data processing.
3. How to Transform Spark RDD to Dataset?
Transforming a Spark RDD (Resilient Distributed Dataset) to a Dataset is a common operation when you want to leverage the benefits of Spark's Catalyst optimizer and type safety. Datasets provide a more structured approach compared to RDDs.
- Creating a Case Class: In Scala, you can define a case class that represents the schema of your data.
language="language-scala"case class Person(name: String, age: Int)
- Converting RDD to Dataset: Use the
toDS()method to convert an RDD to a Dataset. Ensure that you have an implicit encoder for the case class.
language="language-scala"import spark.implicits._-a1b2c3--a1b2c3-val rdd = spark.sparkContext.parallelize(Seq(Person("Alice", 30), Person("Bob", 25)))-a1b2c3-val ds = rdd.toDS()
- Using DataFrame API: If you are working with Python, you can convert an RDD to a DataFrame first and then to a Dataset.
language="language-python"from pyspark.sql import Row-a1b2c3--a1b2c3-rdd = spark.sparkContext.parallelize([Row(name="Alice", age=30), Row(name="Bob", age=25)])-a1b2c3-df = rdd.toDF()
This transformation allows you to take advantage of Spark's optimization features, making your data processing tasks more efficient.
At Rapid Innovation, we leverage these capabilities to help our clients optimize their data processing workflows, ensuring they achieve greater ROI through efficient data management and analysis. By implementing structured schemas and handling complex data types effectively, we enable businesses to extract valuable insights from their data, driving informed decision-making and strategic growth. For more information on how we can assist you, check out our adaptive AI development services.
3.1. Type-Safe Dataset Creation from RDD
Creating a type-safe dataset from a Resilient Distributed Dataset (RDD) is a fundamental aspect of working with Apache Spark. This process allows developers to leverage the benefits of typesafe dataset creation, which enhances code safety and readability.
- RDDs are untyped, meaning they can hold any type of data, which can lead to runtime errors.
- Datasets, on the other hand, are strongly typed, allowing for compile-time type checking.
- To create a type-safe dataset from an RDD, you can use the
toDS()method after importing the necessary implicits.
Steps to create a type-safe dataset from RDD:
- Import the required Spark session and implicits:
language="language-scala"import org.apache.spark.sql.SparkSession-a1b2c3- import spark.implicits._
- Define a case class that represents the schema of your data:
language="language-scala"case class Person(name: String, age: Int)
- Create an RDD with the data:
language="language-scala"val rdd = spark.sparkContext.parallelize(Seq(("Alice", 25), ("Bob", 30)))
- Convert the RDD to a Dataset using the case class:
language="language-scala"val ds = rdd.map { case (name, age) => Person(name, age) }.toDS()
This approach ensures that the dataset is type-safe, allowing for better error handling and code maintenance. At Rapid Innovation, we emphasize the importance of type safety in data processing, which can significantly reduce debugging time and enhance the overall efficiency of your data-driven applications.
3.2. Custom Encoder Implementation
In Spark, encoders are used to convert between JVM objects and Spark's internal binary format. Custom encoders can be implemented to optimize performance and ensure type safety when working with complex data types.
- Spark provides built-in encoders for common types, but custom encoders are necessary for user-defined types.
- Implementing a custom encoder involves defining how to serialize and deserialize your data.
Steps to implement a custom encoder:
- Import the necessary libraries:
language="language-scala"import org.apache.spark.sql.Encoders-a1b2c3- import org.apache.spark.sql.expressions.UserDefinedEncoder
- Define your case class:
language="language-scala"case class Employee(name: String, salary: Double)
- Create a custom encoder:
language="language-scala"implicit val employeeEncoder: Encoder[Employee] = Encoders.kryo[Employee]
- Use the custom encoder when creating a dataset:
language="language-scala"val employeeDS = Seq(Employee("John", 50000.0), Employee("Jane", 60000.0)).toDS()
By implementing a custom encoder, you can ensure that your data is efficiently serialized and deserialized, improving performance in distributed computing environments. Rapid Innovation leverages custom encoders to enhance data processing speeds, ultimately leading to greater ROI for our clients.
3.3. Preserving Data Types During Conversion
When converting between RDDs and Datasets, it is crucial to preserve data types to avoid unexpected behavior and runtime errors. This is particularly important when dealing with complex data structures.
- Spark's Dataset API provides mechanisms to maintain data types during conversions.
- Using case classes helps in preserving the schema and data types.
Steps to preserve data types during conversion:
- Define a case class that represents the data structure:
language="language-scala"case class Product(id: Int, name: String, price: Double)
- Create an RDD with the data:
language="language-scala"val productRDD = spark.sparkContext.parallelize(Seq((1, "Laptop", 999.99), (2, "Phone", 499.99)))
- Convert the RDD to a Dataset while ensuring data types are preserved:
language="language-scala"val productDS = productRDD.map { case (id, name, price) => Product(id, name, price) }.toDS()
- Verify the schema to ensure data types are intact:
language="language-scala"productDS.printSchema()
By following these steps, you can ensure that data types are preserved during conversions, leading to more robust and error-free applications in Spark. At Rapid Innovation, we understand that maintaining data integrity is essential for achieving business goals, and we provide tailored solutions to help our clients navigate these complexities effectively.
4. Performance Optimization Techniques
4.1. Caching and Persistence Strategies
Caching is a crucial performance optimization technique that helps reduce latency and improve application responsiveness. By storing frequently accessed data in a temporary storage area, caching minimizes the need to repeatedly fetch data from slower storage systems. Here are some effective caching strategies:
- In-Memory Caching: Utilize in-memory data stores like Redis or Memcached to cache data. This allows for rapid access and significantly reduces response times, enabling businesses to deliver faster services to their customers.
- HTTP Caching: Implement HTTP caching headers (e.g.,
Cache-Control,ETag) to instruct browsers and intermediate proxies to cache responses. This reduces server load and speeds up content delivery, which is essential for maintaining user engagement. - Database Query Caching: Use query caching mechanisms provided by databases (like MySQL's query cache) to store the results of expensive queries. This can drastically reduce database load and improve performance, leading to a more efficient use of resources.
- Content Delivery Networks (CDNs): Leverage CDNs to cache static assets (images, CSS, JavaScript) closer to users. This reduces latency and improves load times for global users, enhancing the overall user experience.
- Application-Level Caching: Implement caching at the application level using frameworks that support caching strategies, such as Spring Cache for Java applications or Django's caching framework. This can lead to significant performance improvements in application responsiveness.
Persistence strategies are equally important for ensuring data integrity and availability. Here are some best practices:
- Database Indexing: Create indexes on frequently queried columns to speed up data retrieval. Proper indexing can improve query performance significantly, allowing businesses to access critical data more quickly.
- Data Partitioning: Split large datasets into smaller, manageable partitions. This can enhance performance by allowing parallel processing and reducing the amount of data scanned during queries, which is particularly beneficial for large-scale applications.
- Asynchronous Data Processing: Use message queues (like RabbitMQ or Kafka) to handle data processing asynchronously. This allows your application to remain responsive while processing large volumes of data in the background, ensuring that user interactions are not hindered.
4.2. Memory Management Best Practices
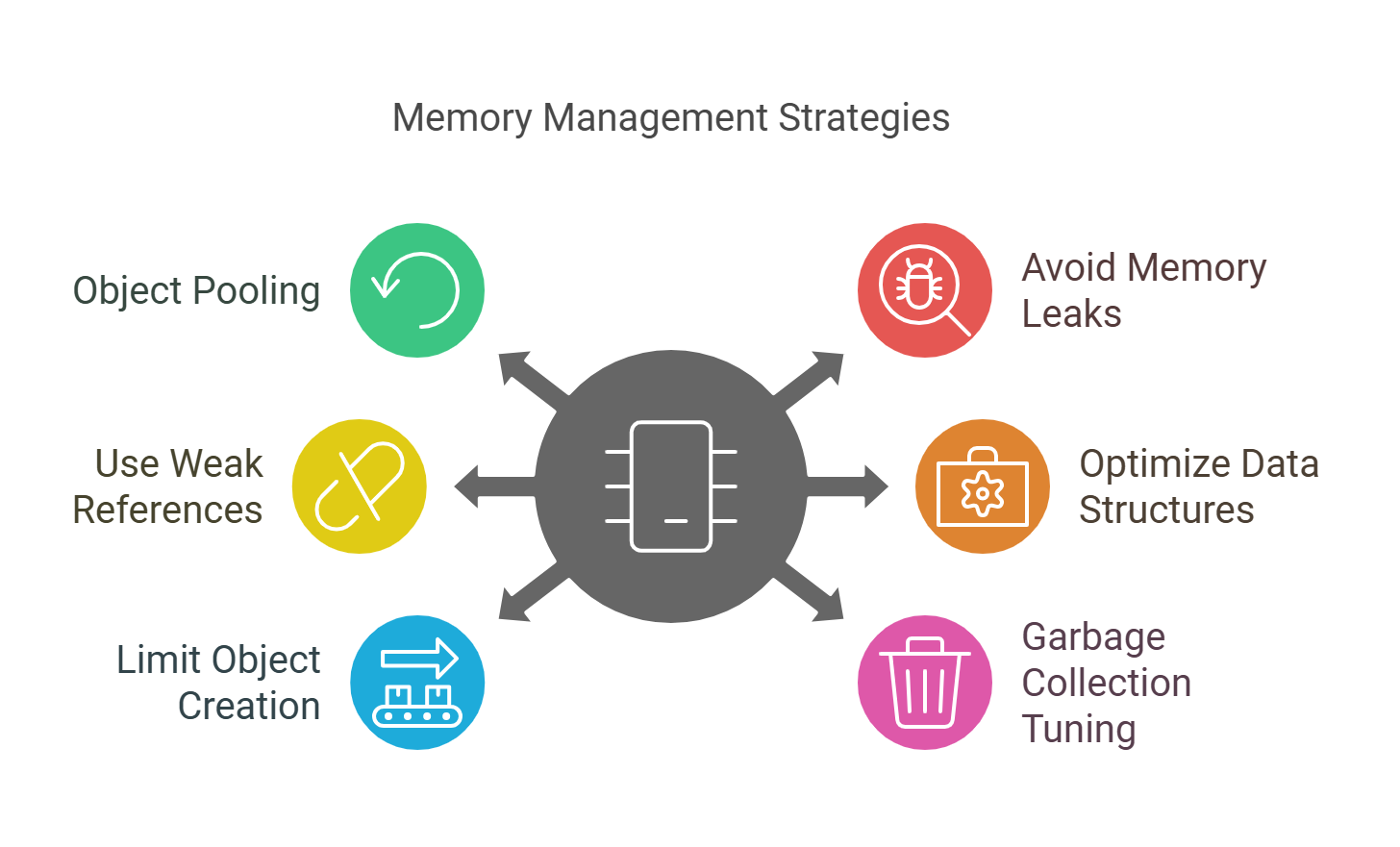
Effective memory management is essential for optimizing application performance and preventing memory leaks. Here are some best practices to consider:
- Object Pooling: Reuse objects instead of creating new instances. This reduces the overhead of memory allocation and garbage collection, leading to better performance and resource utilization.
- Avoid Memory Leaks: Regularly monitor and profile your application to identify and fix memory leaks. Tools like VisualVM or memory profilers can help detect objects that are not being released, ensuring that your application runs smoothly.
- Use Weak References: In languages like Java, consider using weak references for objects that can be recreated. This allows the garbage collector to reclaim memory when needed, optimizing memory usage.
- Optimize Data Structures: Choose the right data structures based on your use case. For example, use arrays for fixed-size collections and linked lists for dynamic collections to optimize memory usage, which can lead to improved application performance.
- Limit Object Creation: Minimize the creation of temporary objects within loops or frequently called methods. Instead, consider reusing existing objects or using primitive types where applicable to enhance efficiency.
- Garbage Collection Tuning: If using a language with garbage collection, tune the garbage collector settings based on your application's memory usage patterns. This can help reduce pause times and improve overall performance.
By implementing these caching and persistence strategies, along with effective memory management practices, Rapid Innovation can help clients significantly enhance the performance of their applications. This, in turn, leads to greater efficiency and a higher return on investment (ROI) for their business initiatives. Techniques such as website performance optimization, web performance optimization, and javascript performance optimization can be integrated into these strategies to further enhance application performance. Additionally, for specific frameworks, react performance optimization and performance optimization in react can be applied to ensure optimal user experiences.
4.3. Query Optimization with Catalyst Optimizer
The Catalyst Optimizer is a powerful component of Apache Spark's SQL engine that enhances query performance through advanced optimization techniques. It plays a crucial role in transforming logical query plans into optimized physical query plans, ensuring efficient execution. The Catalyst optimizer in Spark is essential for achieving high performance in data processing tasks.
- Rule-Based Optimization: Catalyst employs a set of rules to optimize queries, which can include predicate pushdown, constant folding, and projection pruning. By applying these rules, Catalyst can reduce the amount of data processed, leading to faster query execution. This is particularly evident in the catalyst optimization in Spark, where these techniques are applied to improve performance.
- Cost-Based Optimization: Catalyst also incorporates cost-based optimization, which evaluates different execution plans based on their estimated costs. This allows the optimizer to choose the most efficient plan, taking into account factors like data size and distribution. The spark catalyst optimizer is designed to make these evaluations effectively.
- Logical and Physical Plan Generation: The optimization process involves generating a logical plan from the initial query, applying various optimization rules, and then converting it into a physical plan. This multi-step approach ensures that the final execution plan is both efficient and effective. The catalyst optimizer in Spark SQL plays a significant role in this transformation.
- Extensibility: One of the key features of the Catalyst Optimizer is its extensibility. Developers can define custom optimization rules to cater to specific use cases, allowing for tailored performance improvements. This is particularly useful for those looking to implement the catalyst optimizer in PySpark for specialized applications.
- Integration with DataFrames and Datasets: Catalyst works seamlessly with Spark's DataFrames and Datasets APIs, enabling users to write high-level queries while benefiting from the underlying optimization capabilities. The catalyst optimizer in Spark DataFrame allows for efficient data manipulation and querying.
5. Real-World Use Cases and Examples
The Catalyst Optimizer is widely used in various industries to enhance data processing and analytics. Here are some real-world use cases:
- E-commerce Analytics: Companies like Amazon utilize Spark's Catalyst Optimizer to analyze customer behavior and optimize product recommendations. By processing large datasets efficiently, they can deliver personalized experiences to users. The spark SQL optimizer is crucial in these scenarios.
- Financial Services: Banks and financial institutions leverage the Catalyst Optimizer for real-time fraud detection. By optimizing queries that analyze transaction patterns, they can quickly identify suspicious activities and mitigate risks. The spark catalyst optimizer example can be seen in action in these applications.
- Healthcare Data Processing: In the healthcare sector, organizations use Spark to analyze patient data for better treatment outcomes. The Catalyst Optimizer helps in processing large volumes of data from various sources, enabling timely insights for healthcare providers. The catalyst optimizer in Spark SQL is particularly beneficial for these use cases.
5.1. How to Build ETL Pipelines with RDD Conversion?
Building ETL (Extract, Transform, Load) pipelines using RDD (Resilient Distributed Dataset) conversion in Spark can be an effective way to handle large-scale data processing. Here’s how to do it:
- Extract Data: Start by extracting data from various sources such as databases, CSV files, or APIs. Use Spark's
textFileorreadmethods to load the data into RDDs.
language="language-python"from pyspark import SparkContext-a1b2c3--a1b2c3-sc = SparkContext("local", "ETL Pipeline")-a1b2c3-data = sc.textFile("path/to/data.csv")
- Transform Data: Apply transformations to clean and prepare the data. This can include filtering, mapping, and reducing operations.
language="language-python"# Example transformation-a1b2c3-cleaned_data = data.filter(lambda line: len(line) > 0) # Remove empty lines-a1b2c3-transformed_data = cleaned_data.map(lambda line: line.split(","))
- Load Data: Finally, load the transformed data into a target system, such as a database or a data warehouse. Use the
saveAsTextFileorsaveAsTablemethods to store the data.
language="language-python"transformed_data.saveAsTextFile("path/to/output")
- Schedule and Monitor: Use tools like Apache Airflow or Apache NiFi to schedule and monitor your ETL jobs, ensuring they run efficiently and reliably.
By leveraging the Catalyst Optimizer and RDD conversion, organizations can build robust ETL pipelines that handle large datasets effectively, leading to improved data insights and decision-making. At Rapid Innovation, we specialize in implementing these advanced data processing techniques to help our clients achieve greater ROI through optimized data workflows and analytics solutions, including the use of the tungsten optimizer in Spark for enhanced performance and a comprehensive understanding of deep learning.
5.2. Machine Learning Data Preparation
Data preparation is a critical step in the machine learning pipeline. It involves cleaning, transforming, and organizing data to ensure that it is suitable for training machine learning models. Proper data preparation can significantly enhance model performance and accuracy, ultimately leading to greater ROI for businesses.
- Data Cleaning: This involves removing duplicates and irrelevant features, handling missing values through imputation or removal, and normalizing or standardizing data to ensure uniformity. By ensuring high-quality data, Rapid Innovation helps clients avoid costly errors in model predictions. This is particularly important in data preparation for machine learning, where the quality of the dataset can directly impact model outcomes.
- Feature Engineering: Create new features from existing data to improve model performance. Techniques like one-hot encoding for categorical variables can be used, and numerical features should be scaled to a common range. This tailored approach allows clients to leverage their unique datasets effectively, enhancing the predictive power of their models. Data preparation techniques in machine learning often include feature engineering as a key component.
- Data Splitting: Divide the dataset into training, validation, and test sets, using a common split ratio, such as 70% training, 15% validation, and 15% testing. This structured approach ensures that models are robust and generalizable, reducing the risk of overfitting and improving long-term performance. Proper data preparation steps for machine learning are essential to ensure that the model can generalize well to unseen data.
- Data Augmentation: For image data, apply transformations like rotation, flipping, and scaling to increase dataset size. For text data, use techniques like synonym replacement or back-translation. Rapid Innovation employs these techniques to help clients maximize the utility of their data, leading to more accurate models. Data preparation for deep learning often involves extensive data augmentation to improve model robustness.
- Data Transformation: Apply techniques like PCA (Principal Component Analysis) to reduce dimensionality and use log transformation for skewed data distributions. This optimization process not only improves model efficiency but also enhances interpretability, allowing clients to derive actionable insights from their data. Data preparation algorithms can be utilized to automate some of these transformation processes, making them more efficient.
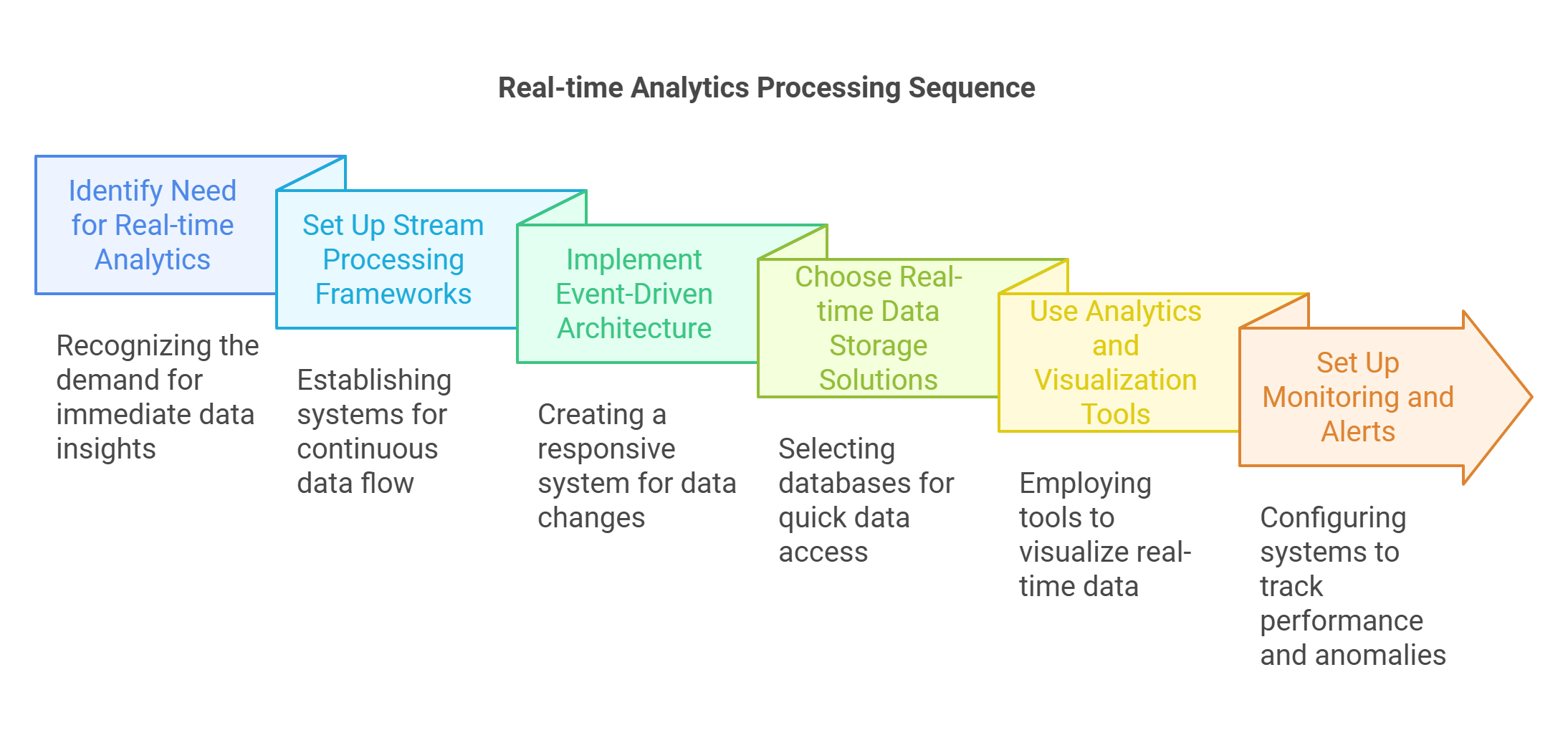
5.3. Real-time Analytics Processing
Real-time analytics processing enables organizations to analyze data as it is generated, providing immediate insights and facilitating timely decision-making. This is particularly important in industries like finance, healthcare, and e-commerce, where Rapid Innovation can help clients stay ahead of the competition.
- Stream Processing Frameworks: Utilize frameworks like Apache Kafka, Apache Flink, or Apache Spark Streaming for real-time data ingestion and processing. Set up data pipelines to handle continuous data streams, ensuring that clients can act on insights as they emerge.
- Event-Driven Architecture: Implement an event-driven architecture to respond to data changes in real-time and use message brokers to manage communication between services. This architecture allows for greater flexibility and responsiveness, enabling clients to adapt quickly to market changes.
- Real-time Data Storage: Choose appropriate storage solutions like NoSQL databases (e.g., MongoDB, Cassandra) for fast read/write operations. Consider in-memory databases (e.g., Redis) for ultra-fast data access. Rapid Innovation's expertise in selecting the right storage solutions ensures that clients can efficiently manage their data.
- Analytics and Visualization: Use tools like Grafana or Tableau for real-time data visualization and implement dashboards that update automatically as new data arrives. This capability empowers clients to make informed decisions based on the latest data insights.
- Monitoring and Alerts: Set up monitoring systems to track data processing performance and configure alerts for anomalies or performance degradation. By proactively managing data systems, Rapid Innovation helps clients maintain optimal performance and minimize downtime.
6. Troubleshooting and Best Practices
Troubleshooting in machine learning and real-time analytics is essential for maintaining system performance and reliability. Following best practices can help mitigate common issues, ensuring that clients achieve their business goals efficiently.
- Data Quality Checks: Regularly validate data quality to ensure accuracy and consistency. Implement automated checks to identify anomalies in data, which helps clients maintain high standards in their data-driven initiatives.
- Model Evaluation: Continuously evaluate model performance using metrics like accuracy, precision, recall, and F1 score. Use cross-validation techniques to ensure robustness. This ongoing evaluation process allows clients to refine their models and maximize ROI.
- Version Control: Use version control systems (e.g., Git) for tracking changes in code and data, and maintain a clear history of model versions and datasets. This practice enhances collaboration and transparency within teams, leading to more effective project management.
- Documentation: Document data preparation steps, model parameters, and processing pipelines. Ensure that all team members have access to up-to-date documentation, which fosters knowledge sharing and continuity in projects.
- Scalability Considerations: Design systems to scale horizontally to handle increased data loads and optimize algorithms and data structures for performance. Rapid Innovation's scalable solutions ensure that clients can grow their operations without compromising performance.
- Regular Updates: Keep libraries and frameworks up to date to leverage improvements and security patches. Regularly retrain models with new data to maintain accuracy. This commitment to continuous improvement helps clients stay competitive in their respective markets.
By following these guidelines, organizations can enhance their machine learning and real-time analytics capabilities, leading to better insights and decision-making. Rapid Innovation is dedicated to helping clients navigate these complexities, ensuring they achieve their business objectives effectively and efficiently.
6.1. Common Conversion Errors and Solutions
Data conversion is a critical process in data management, but it often comes with its own set of challenges. Here are some common conversion errors and their solutions:
- Data Type Mismatches: This occurs when the data type in the source system does not match the target system. For example, a string in the source may need to be converted to an integer in the target.
Solution: Implement data type validation rules during the conversion process to ensure compatibility. - Loss of Precision: Numeric data can lose precision when converting from one format to another, especially with floating-point numbers.
Solution: Use appropriate data types that can handle the required precision, such as decimal types for financial data. - Encoding Issues: Character encoding mismatches can lead to data corruption, especially with special characters.
Solution: Standardize character encoding (e.g., UTF-8) across systems before conversion. - Null Value Handling: Null values may not be handled correctly, leading to data integrity issues.
Solution: Define clear rules for how null values should be treated during the conversion process. - Data Truncation: Data may be truncated if the target field is smaller than the source field.
Solution: Ensure that target fields are adequately sized to accommodate the incoming data. - Data Conversion Errors: These errors can occur during the transformation of data from one format to another, leading to inaccuracies or loss of information.
Solution: Implement thorough testing and validation processes to catch and correct data conversion errors before they impact the system.
6.2. Data Quality Validation Methods
Ensuring data quality is essential for reliable data analysis and decision-making. Here are some effective data quality validation methods:
- Data Profiling: Analyze the data to understand its structure, content, and relationships. This helps identify anomalies and inconsistencies.
Tools: Use tools like Talend or Informatica for data profiling. - Validation Rules: Establish rules that data must meet to be considered valid. This can include format checks, range checks, and consistency checks.
Example: Ensure that email addresses follow a standard format (e.g., user@domain.com). - Automated Testing: Implement automated testing frameworks to regularly check data quality. This can include unit tests for data transformations.
Tools: Use frameworks like Apache JMeter or Selenium for automated testing. - Data Cleansing: Regularly clean the data to remove duplicates, correct errors, and fill in missing values.
Techniques: Use deduplication algorithms and imputation methods for missing data. - User Feedback: Incorporate user feedback mechanisms to identify data quality issues that may not be caught by automated methods.
Implementation: Create a feedback loop where users can report data issues directly.
6.3. Performance Monitoring and Tuning
Performance monitoring and tuning are crucial for maintaining the efficiency of data systems. Here are some strategies to consider:
- Monitoring Tools: Utilize monitoring tools to track system performance metrics such as response time, throughput, and resource utilization.
Examples: Tools like Grafana or Prometheus can provide real-time insights. - Query Optimization: Regularly review and optimize database queries to improve performance. This can include indexing, query rewriting, and analyzing execution plans.
Steps:- Identify slow-running queries.
- Analyze execution plans to find bottlenecks.
- Implement indexing strategies.
- Load Testing: Conduct load testing to understand how the system performs under various conditions. This helps identify potential performance issues before they affect users.
Tools: Use tools like Apache JMeter or LoadRunner for load testing. - Resource Allocation: Ensure that resources (CPU, memory, storage) are allocated efficiently based on usage patterns.
Strategy: Implement auto-scaling solutions to adjust resources dynamically based on demand. - Regular Maintenance: Schedule regular maintenance tasks such as database re-indexing and cleanup to ensure optimal performance.
Frequency: Set a maintenance schedule based on system usage and performance metrics.
By addressing common conversion errors, including data conversion errors, implementing robust data quality validation methods, and continuously monitoring and tuning performance, organizations can ensure the integrity and efficiency of their data systems. At Rapid Innovation, we leverage our expertise in AI and Blockchain to enhance these processes, ensuring that our clients achieve greater ROI through optimized data management solutions.
7. Enterprise Integration Patterns
Enterprise Integration Patterns (EIPs) are design patterns that provide solutions to common integration problems in enterprise systems. They help in creating scalable, maintainable, and efficient integration solutions. EIPs are particularly useful in environments where multiple systems need to communicate and share data seamlessly. This includes various approaches such as enterprise application integration patterns and enterprise messaging patterns.
7.1. Integration with Data Lakes and Warehouses
Integrating with data lakes and data warehouses is crucial for organizations looking to leverage big data analytics. Data lakes store vast amounts of raw data in its native format, while data warehouses store structured data optimized for analysis. The integration of these two systems can enhance data accessibility and analytics capabilities, aligning with enterprise integration design patterns.
Key considerations for integration include:
- Data Ingestion: Use tools like Apache Kafka or AWS Glue to ingest data from various sources into the data lake.
- Data Transformation: Implement ETL (Extract, Transform, Load) processes to convert raw data into a structured format suitable for analysis in data warehouses.
- Data Governance: Establish data governance policies to ensure data quality, security, and compliance.
- Real-time Processing: Utilize stream processing frameworks like Apache Flink or Apache Spark Streaming for real-time data integration.
- Data Access: Use APIs or SQL-based access methods to allow users to query data from both data lakes and warehouses.
An example of a data integration workflow is as follows:
language="language-plaintext"1. Identify data sources (e.g., databases, IoT devices).-a1b2c3-2. Use Apache Kafka to stream data into the data lake.-a1b2c3-3. Apply transformations using Apache Spark.-a1b2c3-4. Load transformed data into the data warehouse (e.g., Amazon Redshift).-a1b2c3-5. Enable BI tools to access data for reporting and analytics.
The integration of data lakes and warehouses can lead to improved decision-making and insights. According to a report, organizations that effectively integrate their data can achieve a 5-10% increase in revenue.
7.2. Microservices Architecture Implementation
Microservices architecture is an approach to software development where applications are built as a collection of loosely coupled services. Each service is independently deployable and can communicate with others through APIs. This architecture enhances scalability, flexibility, and maintainability, reflecting the principles of enterprise integration patterns.
Key steps for implementing microservices architecture include:
- Service Identification: Break down the application into smaller, manageable services based on business capabilities.
- API Design: Define clear APIs for each service to facilitate communication. Use REST or gRPC for efficient data exchange.
- Containerization: Use Docker to containerize services, ensuring consistency across development and production environments.
- Orchestration: Implement orchestration tools like Kubernetes to manage service deployment, scaling, and networking.
- Monitoring and Logging: Use tools like Prometheus and ELK Stack for monitoring service performance and logging errors.
An example of a microservices deployment workflow is as follows:
language="language-plaintext"1. Identify business capabilities (e.g., user management, order processing).-a1b2c3-2. Develop each capability as a separate microservice.-a1b2c3-3. Containerize each service using Docker.-a1b2c3-4. Deploy services to a Kubernetes cluster.-a1b2c3-5. Monitor services using Prometheus and visualize with Grafana.
Microservices architecture allows for continuous delivery and deployment, enabling teams to release updates more frequently. According to a study, organizations adopting microservices can achieve a 20-30% reduction in time-to-market.
In conclusion, both integration with data lakes and warehouses and the implementation of microservices architecture are essential components of modern enterprise integration strategies. They enable organizations to harness the power of data and improve operational efficiency. At Rapid Innovation, we specialize in implementing these enterprise integration patterns, including Apache Camel EIP and enterprise integration patterns examples, ensuring that our clients achieve greater ROI through enhanced data accessibility and streamlined operations.
7.3. Cloud Platform Deployment Strategies
Cloud platform deployment strategies, including aws deployment strategies and cloud deployment strategies, are essential for ensuring that applications are scalable, reliable, and cost-effective. Different strategies can be employed based on the specific needs of the organization and the nature of the application. Here are some common deployment strategies:
- Lift and Shift: This strategy involves moving applications from on-premises to the cloud without significant changes. It is quick and allows for immediate benefits of cloud infrastructure, enabling organizations to reduce operational costs and improve resource utilization.
- Replatforming: This approach involves making some optimizations to the application while migrating it to the cloud. It may include changing the database or using cloud-native services to enhance performance, which can lead to improved efficiency and reduced latency.
- Refactoring: This strategy requires a more in-depth redesign of the application to take full advantage of cloud capabilities. It often involves breaking down monolithic applications into microservices, allowing for greater flexibility, scalability, and faster deployment cycles. This is particularly relevant in openshift deployment strategies.
- Hybrid Deployment: This strategy combines on-premises and cloud resources, allowing organizations to maintain sensitive data on-premises while leveraging the cloud for scalability and flexibility. This approach can optimize costs while ensuring compliance with data regulations.
- Multi-Cloud Strategy: This involves using multiple cloud service providers to avoid vendor lock-in and enhance redundancy. It allows organizations to choose the best services from different providers, ensuring optimal performance and cost-effectiveness.
- Continuous Deployment: This strategy automates the deployment process, allowing for frequent updates and improvements to applications. It enhances agility and responsiveness to market changes, enabling organizations to stay competitive. This is a key aspect of deployment strategies in aws.
8. Future-Proofing Your Implementation
Future-proofing your implementation is crucial in a rapidly evolving technological landscape. It ensures that your systems remain relevant and can adapt to new requirements. Here are some strategies to consider:
- Modular Architecture: Design your applications with a modular architecture to facilitate easy updates and integration of new technologies. This approach allows for independent scaling and maintenance of different components, which can lead to reduced downtime and increased innovation.
- Cloud-Native Technologies: Embrace cloud-native technologies such as containers and microservices. These technologies enhance flexibility and scalability, making it easier to adapt to changing business needs and improving overall system resilience.
- Regular Training and Development: Invest in continuous training for your team to keep them updated on the latest technologies and best practices. This ensures that your organization can leverage new tools and methodologies effectively, ultimately driving greater ROI.
- Monitoring and Analytics: Implement robust monitoring and analytics tools to gain insights into application performance and user behavior. This data can inform future enhancements and optimizations, leading to improved user satisfaction and operational efficiency.
- API-First Approach: Adopt an API-first approach to ensure that your applications can easily integrate with other systems and services. This flexibility is essential for adapting to new business requirements and fostering innovation.
8.1. Guide to Upgrading Spark Versions
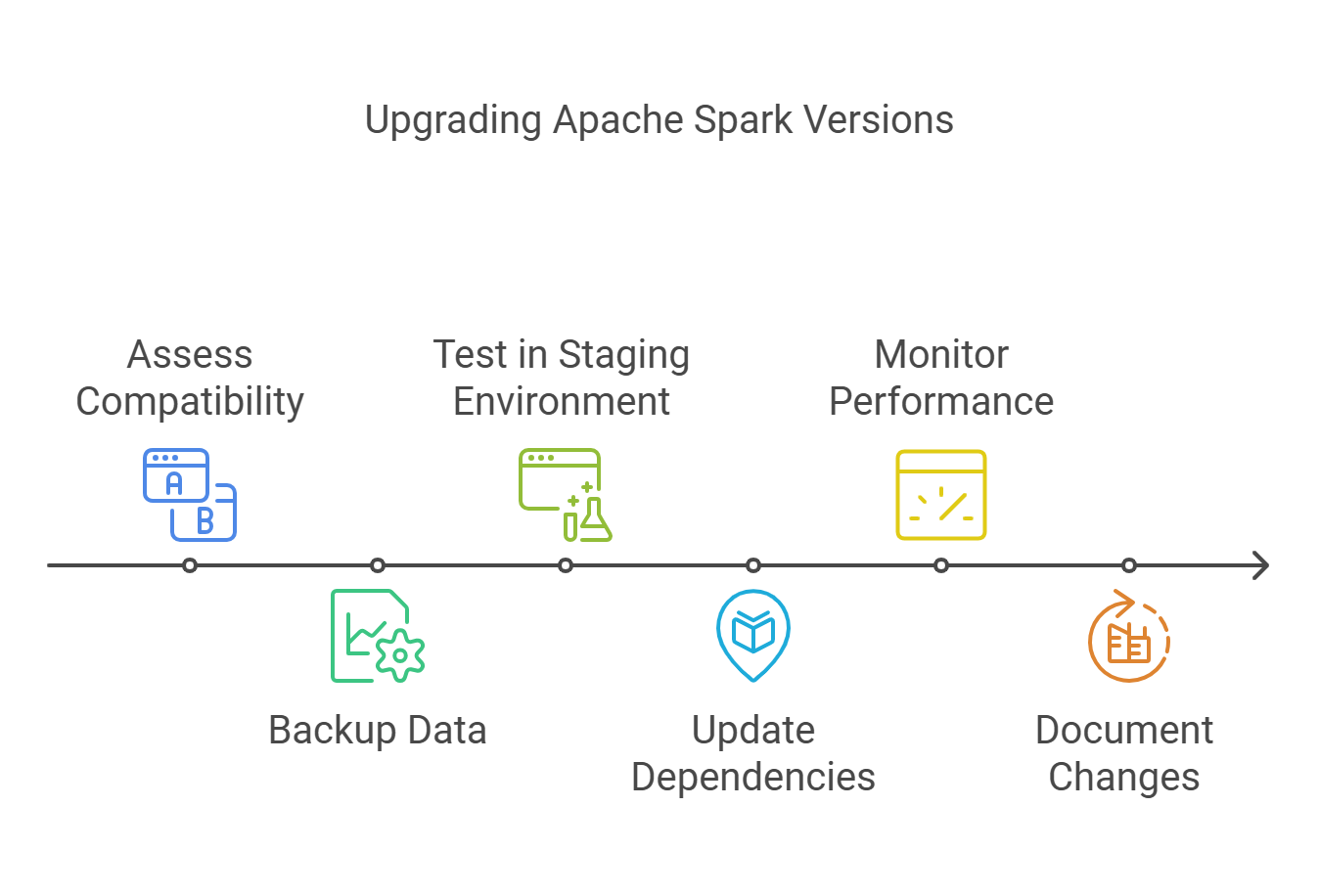
Upgrading Apache Spark versions is essential for leveraging new features, performance improvements, and security enhancements. Here’s a guide to ensure a smooth upgrade process:
- Assess Compatibility: Before upgrading, check the compatibility of your existing applications with the new Spark version. Review the release notes for breaking changes and deprecated features to avoid disruptions.
- Backup Data: Always back up your data and configurations before initiating the upgrade. This ensures that you can revert to the previous version if necessary, safeguarding your business continuity.
- Test in a Staging Environment: Set up a staging environment that mirrors your production setup. Test the new Spark version with your applications to identify any issues before going live, minimizing risks associated with the upgrade.
- Update Dependencies: Ensure that all dependencies, including libraries and connectors, are compatible with the new Spark version. Update them as necessary to maintain optimal performance.
- Monitor Performance: After upgrading, closely monitor the performance of your applications. Look for any anomalies or performance regressions that may arise from the upgrade, allowing for timely adjustments.
- Document Changes: Keep detailed documentation of the upgrade process, including any changes made to configurations or code. This will be helpful for future upgrades and troubleshooting, ensuring a smoother transition.
By following these strategies and guidelines, organizations can effectively deploy applications on cloud platforms, including aws fargate deployment strategy and aws rolling deployment, future-proof their implementations, and manage upgrades to Apache Spark efficiently. Rapid Innovation is here to assist you in navigating these strategies, ensuring that your business achieves greater ROI through optimized cloud solutions and advanced technologies.
8.2. Scalability and Maintenance Considerations
Scalability and maintenance are critical factors in the design and implementation of any data processing system, especially when dealing with large datasets. Here are some key considerations:
- Horizontal vs. Vertical Scaling: Horizontal scaling involves adding more machines to handle increased load, while vertical scaling means upgrading existing machines. For big data applications, horizontal scaling is often preferred due to its cost-effectiveness and flexibility, particularly in the context of data processing scalability.
- Load Balancing: Implementing load balancers can help distribute workloads evenly across servers, ensuring no single server becomes a bottleneck. This is essential for maintaining performance as data volume grows.
- Data Partitioning: Partitioning data can improve performance and manageability. By dividing datasets into smaller, more manageable pieces, systems can process data in parallel, enhancing speed and efficiency.
- Monitoring and Logging: Regular monitoring of system performance and logging errors can help identify potential issues before they escalate. Tools like Prometheus and Grafana can be used for real-time monitoring.
- Automated Maintenance: Automating routine maintenance tasks, such as backups and updates, can reduce downtime and ensure that systems remain operational. Tools like Ansible or Puppet can facilitate this process.
- Documentation and Training: Keeping thorough documentation and providing training for team members can ensure that everyone understands the system architecture and maintenance procedures, which is vital for long-term sustainability.
8.3. Emerging Trends and Technologies
The landscape of data processing is constantly evolving, with new trends and technologies emerging regularly. Here are some noteworthy developments:
- Serverless Computing: Serverless architectures allow developers to build and run applications without managing servers. This can lead to reduced operational costs and increased scalability.
- Artificial Intelligence and Machine Learning: Integrating AI and ML into data processing pipelines can enhance data analysis capabilities, enabling predictive analytics and real-time decision-making. Rapid Innovation specializes in leveraging these technologies to help clients optimize their data strategies, resulting in improved operational efficiency and ROI.
- Data Lakes: Data lakes are becoming increasingly popular for storing vast amounts of unstructured data. They allow organizations to store data in its raw form, making it easier to analyze and derive insights.
- Real-time Data Processing: Technologies like Apache Kafka and Apache Flink are enabling real-time data processing, allowing businesses to react to data as it arrives, which is crucial for applications like fraud detection and customer engagement.
- Edge Computing: With the rise of IoT devices, edge computing is gaining traction. It allows data processing to occur closer to the data source, reducing latency and bandwidth usage.
- Data Privacy and Security: As data regulations become stricter, technologies that enhance data privacy and security, such as encryption and anonymization, are increasingly important.
9. What's the Business Value of RDD Conversion?
RDD (Resilient Distributed Dataset) conversion offers significant business value, particularly in the context of big data processing. Here are some key benefits:
- Improved Performance: RDDs are designed for in-memory processing, which can significantly speed up data operations compared to traditional disk-based systems.
- Fault Tolerance: RDDs provide built-in fault tolerance, allowing systems to recover quickly from failures without losing data, which is crucial for maintaining business continuity.
- Ease of Use: The abstraction provided by RDDs simplifies the programming model, making it easier for data engineers and analysts to work with large datasets without deep technical expertise.
- Cost Efficiency: By optimizing resource usage and reducing processing time, RDD conversion can lead to lower operational costs, allowing businesses to allocate resources more effectively.
- Scalability: RDDs can easily scale across clusters, accommodating growing data volumes without significant reconfiguration, which is essential for businesses anticipating growth and enhancing data processing scalability.
- Enhanced Analytics: The ability to perform complex transformations and actions on large datasets enables businesses to derive deeper insights, leading to better decision-making and strategic planning. Rapid Innovation is committed to helping clients harness the power of RDD conversion to achieve these benefits, ultimately driving greater ROI and business success.
9.1. Cost-Benefit Analysis of Data Structure Conversion
A cost-benefit analysis (CBA) is essential when considering the conversion of data structures. This process helps organizations evaluate the financial implications and potential returns of such a conversion.
- Identify Costs:
- Initial investment in new technology or tools.
- Training costs for staff to adapt to new data structures.
- Ongoing maintenance and support costs.
- Estimate Benefits:
- Improved data retrieval speeds, leading to enhanced productivity.
- Reduction in storage costs due to more efficient data structures.
- Increased scalability, allowing for future growth without significant additional costs.
- Calculate ROI:
- Use the formula:
ROI = (Net Benefits / Costs) x 100. - A positive ROI indicates that the benefits outweigh the costs, making the conversion worthwhile.
- Use the formula:
- Consider Intangible Benefits:
- Enhanced user satisfaction due to faster access to information.
- Improved decision-making capabilities from better data organization.
Conducting a thorough CBA ensures that organizations make informed decisions regarding data structure conversion, aligning with their strategic goals. At Rapid Innovation, we leverage our expertise in AI and Blockchain to guide clients through this analysis, ensuring they maximize their investment and achieve greater ROI.
9.2. Performance Metrics and KPIs
Performance metrics and Key Performance Indicators (KPIs) are critical for assessing the effectiveness of data structure conversions. These metrics provide insights into how well the new data structures are performing compared to the old ones.
- Data Retrieval Time:
- Measure the time taken to access and retrieve data before and after conversion.
- Storage Efficiency:
- Analyze the amount of storage space used by the new data structure versus the old one.
- Error Rate:
- Track the frequency of errors or data corruption incidents post-conversion.
- User Satisfaction:
- Conduct surveys to gauge user experience and satisfaction with the new data structure.
- Scalability Metrics:
- Evaluate how well the new structure accommodates increased data loads without performance degradation.
- Cost Savings:
- Monitor reductions in operational costs associated with data management and storage.
By establishing clear performance metrics and KPIs, organizations can effectively measure the success of their data structure conversion and make necessary adjustments. Rapid Innovation assists clients in defining these metrics, ensuring that they can track their progress and optimize their operations.
9.3. Business Impact Case Studies
While specific case studies may not be included here, they can provide valuable insights into the real-world implications of data structure conversion.
- Case Study Example:
- A retail company that transitioned from a traditional relational database to a NoSQL database experienced a 50% reduction in data retrieval times, leading to improved customer service and increased sales.
- Industry-Specific Impacts:
- In the healthcare sector, a hospital that converted its patient data management system saw a significant decrease in patient wait times due to faster access to medical records.
- Long-Term Benefits:
- Companies that have successfully implemented data structure conversions often report enhanced agility in responding to market changes, improved data analytics capabilities, and better compliance with regulatory requirements.
These case studies highlight the tangible benefits and strategic advantages that can be gained from investing in data structure conversion, reinforcing the importance of a well-planned approach. At Rapid Innovation, we are committed to helping our clients navigate these transformations, ensuring they realize the full potential of their data strategies.
10. Conclusion and Next Steps
In any project or initiative, reaching the conclusion is just the beginning of the next phase. It is essential to have a clear understanding of the next steps to ensure successful implementation and resource allocation. This section will provide a comprehensive overview of the project implementation checklist, the gad checklist for project management and implementation, and resource planning guidelines to facilitate a smooth transition into the next stages.
10.1. Implementation Checklist
An implementation checklist is a vital tool that helps ensure all necessary steps are taken before, during, and after the execution of a project. It serves as a roadmap to guide teams through the process, minimizing the risk of oversight. Here are key components to include in your implementation checklist:
- Define project objectives and goals clearly.
- Identify stakeholders and their roles.
- Develop a detailed project timeline with milestones.
- Allocate resources, including budget, personnel, and technology.
- Create a communication plan to keep all stakeholders informed.
- Establish risk management strategies to address potential challenges.
- Conduct training sessions for team members on new processes or tools.
- Monitor progress regularly and adjust plans as necessary.
- Gather feedback from stakeholders to improve future implementations.
- Document lessons learned for future reference.
By following this checklist, including the project post implementation review checklist, teams can ensure that they are well-prepared for the implementation phase, leading to a higher likelihood of success.
10.2. Resource Planning Guidelines
Effective resource planning is crucial for the successful execution of any project. It involves identifying, allocating, and managing resources efficiently to meet project goals. Here are some guidelines to consider when planning resources:
- Assess resource availability: Evaluate the current resources, including personnel, technology, and budget, to determine what is available for the project.
- Prioritize resource allocation: Identify which resources are critical to the project's success and allocate them accordingly.
- Create a resource management plan: Develop a plan that outlines how resources will be utilized, monitored, and adjusted throughout the project lifecycle.
- Implement a tracking system: Use project management tools to track resource usage and availability in real-time, allowing for quick adjustments as needed.
- Foster collaboration: Encourage teamwork and communication among team members to optimize resource utilization and address any issues promptly.
- Review and adjust regularly: Periodically review resource allocation and make adjustments based on project progress and changing needs.
By adhering to these resource planning guidelines, including the scrum implementation checklist, organizations can maximize their efficiency and effectiveness, ensuring that projects are completed on time and within budget.
In conclusion, having a well-defined implementation checklist and robust resource planning guidelines is essential for the success of any project. By following these steps, teams can navigate the complexities of project execution and achieve their desired outcomes. At Rapid Innovation, we are committed to guiding our clients through these processes, leveraging our expertise in AI and Blockchain to enhance project outcomes and drive greater ROI.
10.3. Additional Learning Resources
In the ever-evolving landscape of technology and education, additional learning resources can significantly enhance your understanding and skills. Here are some valuable resources that can help you expand your knowledge base, particularly in the domains of learning resources for AI and Blockchain, where Rapid Innovation excels in providing development and consulting solutions.
Online Courses
- Coursera: Offers a wide range of courses from top universities and organizations, including programming, data science, and specialized AI and Blockchain courses that can help you leverage these technologies for business growth.
- edX: Similar to Coursera, edX provides access to high-quality courses from institutions like MIT and Harvard, including topics on machine learning and decentralized applications, which are crucial for modern business strategies.
- Udemy: A platform with a vast selection of courses on various topics, often at affordable prices, including practical courses on AI implementation and Blockchain development.
E-books and Online Libraries
- Project Gutenberg: A digital library offering over 60,000 free eBooks, including classic literature and historical texts that can provide context for the evolution of technology.
- Google Books: A vast repository of books and magazines, allowing you to preview and read a wide range of materials, including those focused on AI ethics and Blockchain technology.
- Open Library: An initiative of the Internet Archive, Open Library provides access to millions of books, including many that are out of print, which can be valuable for historical insights into technological advancements.
YouTube Channels
- Khan Academy: Offers instructional videos on a variety of subjects, including math and science, which are foundational for understanding AI algorithms.
- TED-Ed: Features educational videos that cover a wide range of topics, often presented by experts in their fields, including discussions on the impact of AI and Blockchain on society.
- CrashCourse: Provides engaging and informative videos on subjects like history, science, and technology, which can help contextualize the importance of AI and Blockchain in today's world.
Podcasts
- The EdSurge Podcast: Discusses the intersection of technology, education, and the future of learning, including how AI can transform educational practices.
- The Learning Leader Show: Features interviews with leaders in various fields, focusing on their learning experiences and insights, including the role of innovative technologies like AI and Blockchain in leadership.
- The Art of Charm: Offers tips on personal development, communication, and social skills, which are essential for effectively implementing AI and Blockchain solutions in business.
Blogs and Websites
- Edutopia: A comprehensive resource for educators, featuring articles, videos, and resources on innovative teaching practices, including the integration of AI in education.
- MindShift: Explores the future of learning, covering topics like technology in education and social-emotional learning, relevant for understanding the implications of AI in educational settings.
- Learning Mind: Focuses on psychology, personal development, and learning strategies, which can be beneficial for understanding user behavior in AI applications.
Forums and Online Communities
- Reddit: Subreddits like r/learnprogramming and r/education provide platforms for discussion and resource sharing, including insights on AI and Blockchain projects.
- Stack Overflow: A community for programmers to ask questions and share knowledge about coding and software development, including specific queries related to AI algorithms and Blockchain protocols.
- Quora: A question-and-answer platform where you can find insights from experts on various topics, including the latest trends in AI and Blockchain technology.
Coding and Development Resources
- Codecademy: An interactive platform that teaches coding through hands-on projects and exercises, including courses on AI programming languages like Python.
- freeCodeCamp: Offers a comprehensive curriculum for learning web development, including HTML, CSS, and JavaScript, which are essential for building Blockchain applications.
- GitHub: A platform for version control and collaboration, where you can find open-source projects and contribute to them, including those focused on AI and Blockchain technologies.
Educational Apps
- Duolingo: A language-learning app that makes learning new languages fun and engaging, which can be useful for understanding programming languages used in AI and Blockchain.
- Khan Academy Kids: An educational app for young children, offering interactive lessons in various subjects, including foundational concepts in technology.
- Quizlet: A study tool that allows users to create flashcards and quizzes for effective learning, which can be tailored to AI and Blockchain terminology.
Local Libraries and Community Centers
- Public Libraries: Often provide free access to books, eBooks, and educational programs, including workshops on emerging technologies like AI and Blockchain.
- Community Colleges: Many offer affordable courses and workshops for skill development, including specialized training in AI and Blockchain.
- Meetup Groups: Local gatherings focused on specific interests, providing opportunities for networking and learning, particularly in the fields of AI and Blockchain.
By utilizing these additional learning resources, you can enhance your knowledge and skills in various fields, particularly in learning resources for AI and Blockchain. Whether you prefer online courses, podcasts, or community engagement, there are countless options available to support your learning journey and help you achieve your business goals efficiently and effectively with the expertise of Rapid Innovation.













