





1. Introduction to Computer Vision in Robotics
Computer vision is a transformative field of artificial intelligence that empowers machines to interpret and understand visual information from the world around them. In the realm of robotics, computer vision is essential for enabling robots to perceive their environment, make informed decisions, and perform tasks autonomously. By integrating computer vision into robotics, we enhance the capabilities of robots, making them more efficient and effective across a wide range of applications, including computer vision applications in robotics.
1.1. Definition and Importance
- Computer vision refers to the ability of machines to process and analyze visual data, such as images and videos.
- It involves techniques that allow robots to extract meaningful information from visual inputs, enabling them to understand their surroundings.
Importance in robotics includes:
- Autonomous Navigation: Robots can navigate complex environments by recognizing obstacles and determining paths, significantly reducing the need for human intervention.
- Object Recognition: Robots can identify and classify objects, which is essential for tasks like sorting, picking, and manipulation, thereby increasing operational efficiency. This is particularly relevant in the context of object recognition in robotics.
- Human-Robot Interaction: Enhanced understanding of human gestures and expressions allows for more intuitive interactions, fostering better collaboration between humans and machines.
- Quality Control: In manufacturing, robots can inspect products for defects using visual data, ensuring higher quality standards and reducing waste.
- Surveillance and Monitoring: Robots equipped with vision systems can monitor environments for security or safety purposes, providing real-time insights and alerts.
1.2. Historical Overview
- The roots of computer vision can be traced back to the 1960s when researchers began exploring ways for machines to interpret images.
- Early developments included:
- 1960s-1970s: Initial algorithms for edge detection and shape recognition were created, laying the groundwork for future advancements.
- 1980s: The introduction of more sophisticated techniques, such as feature extraction and pattern recognition, allowed for improved image analysis.
- 1990s: The advent of machine learning techniques, particularly neural networks, began to revolutionize the field, enabling more complex visual tasks.
- The 21st century saw significant advancements due to:
- Increased Computational Power: The rise of powerful GPUs allowed for real-time image processing and analysis, making it feasible to deploy computer vision in practical applications, including ros computer vision.
- Big Data: The availability of large datasets for training machine learning models improved the accuracy of computer vision systems, leading to more reliable outcomes.
- Deep Learning: Techniques such as convolutional neural networks (CNNs) became prominent, leading to breakthroughs in object detection and image classification.
- Today, computer vision is integral to robotics, with applications in various sectors, including healthcare, agriculture, and autonomous vehicles, highlighting the application of computer vision in robotics.
At Rapid Innovation, we leverage our expertise in AI and blockchain to help clients harness the power of computer vision in robotics. By partnering with us, clients can expect greater ROI through enhanced operational efficiency, reduced costs, and improved product quality. Our tailored solutions ensure that your organization can navigate the complexities of modern technology with confidence and achieve your goals effectively and efficiently, including advancements in computer vision and robotics.
1.3. Applications in Robotics
Robotics is a rapidly evolving field that integrates various technologies, including artificial intelligence, machine learning, and computer vision. The applications of robotics are vast and diverse, impacting numerous industries.

- Industrial Automation: Robots are widely used in manufacturing for tasks such as assembly, robotic welding, and painting. They enhance productivity and precision while reducing human error, leading to significant cost savings and increased output for businesses. Industrial robots, including kuka industrial robots, play a crucial role in this sector.
- Medical Robotics: Surgical robots assist surgeons in performing complex procedures with greater accuracy. They also enable minimally invasive surgeries, leading to quicker recovery times for patients, which can result in lower healthcare costs and improved patient satisfaction.
- Service Robots: These robots are designed to assist humans in everyday tasks. Examples include vacuum cleaning robots, lawn-mowing robots, and robots used in hospitality for serving food and drinks. By automating routine tasks, businesses can improve efficiency and allow staff to focus on higher-value activities.
- Exploration and Surveillance: Robots are deployed in hazardous environments, such as deep-sea exploration or space missions, where human presence is limited. Drones are also used for surveillance and monitoring in various sectors, providing valuable data while minimizing risk to human operators.
- Agricultural Robotics: Robots are increasingly used in agriculture for planting, harvesting, and monitoring crops. Agricultural robots help optimize resource use and improve yield, enabling farmers to achieve greater productivity and sustainability.
- Autonomous Vehicles: Self-driving cars utilize robotics to navigate and make decisions in real-time, relying on sensors and algorithms to interpret their surroundings. This technology has the potential to revolutionize transportation, reduce accidents, and improve traffic efficiency.
- Robotic Manufacturing: The integration of robotics in manufacturing processes, including robotic laser welding and machine tending robots, enhances efficiency and precision. Collaborative robotics, such as pick & place robots, allow for safe human-robot interaction in industrial settings.
2. Fundamentals of Computer Vision
Computer vision is a field of artificial intelligence that enables machines to interpret and understand visual information from the world. It involves the extraction of meaningful information from images and videos.
- Image Processing: This is the initial step in computer vision, where raw images are enhanced and transformed to make them suitable for analysis. Techniques include filtering, edge detection, and noise reduction, which are essential for accurate data interpretation.
- Feature Extraction: Identifying key features in an image, such as edges, corners, and textures, is crucial for understanding the content. These features serve as the basis for further analysis and recognition tasks, enhancing the system's ability to make informed decisions.
- Object Recognition: This involves identifying and classifying objects within an image. Machine learning algorithms, particularly deep learning, have significantly improved the accuracy of object recognition systems, enabling applications in security, retail, and more.
- Image Segmentation: This process divides an image into segments or regions to simplify its analysis. It helps in isolating objects or areas of interest for further processing, which is vital in applications like medical imaging and autonomous navigation.
- 3D Reconstruction: Computer vision can also be used to create three-dimensional models from two-dimensional images. This is essential in applications like virtual reality and robotics, providing immersive experiences and enhancing robotic interactions with the environment.
2.1. Image Formation and Representation
Image formation is the process by which a visual image is created from light reflected off objects. Understanding this process is fundamental to computer vision.
- Light and Optics: Images are formed when light rays pass through a lens and converge on a sensor. The quality of the image depends on factors like lens type, aperture size, and exposure time, which are critical for achieving high-quality visual data.
- Pixel Representation: Digital images are composed of pixels, which are the smallest units of a digital image. Each pixel represents a specific color and intensity, contributing to the overall image, and understanding this is key for effective image processing.
- Color Models: Different color models, such as RGB (Red, Green, Blue) and CMYK (Cyan, Magenta, Yellow, Black), are used to represent colors in images. Each model has its applications depending on the context, influencing how images are processed and displayed.
- Image Resolution: This refers to the amount of detail an image holds, typically measured in pixels per inch (PPI). Higher resolution images contain more detail but require more storage space, impacting the efficiency of data handling and processing.
- Image Formats: Various formats exist for storing images, including JPEG, PNG, and TIFF. Each format has its advantages and disadvantages regarding quality, compression, and compatibility, which are important considerations for developers and businesses alike.
Understanding these fundamentals is crucial for developing effective computer vision systems that can interpret and analyze visual data accurately. By partnering with Rapid Innovation, clients can leverage our expertise in robotics and computer vision to achieve greater ROI through innovative solutions tailored to their specific needs.
2.2. Image Processing Techniques
Image processing techniques are essential for enhancing and analyzing images, enabling businesses to derive valuable insights and improve decision-making. These techniques can be broadly categorized into two types: spatial domain techniques and frequency domain techniques.
- Spatial Domain Techniques:
- Involve direct manipulation of pixel values.
- Common methods include:
- Image Enhancement: Improves visual appearance using techniques like histogram equalization and contrast stretching, which can significantly enhance the quality of images used in marketing materials or product presentations. Techniques such as unsharp masking can also be employed for better clarity.
- Filtering: Removes noise or enhances features using filters such as Gaussian, median, and Laplacian filters, ensuring that images are clear and professional for client-facing applications.
- Morphological Operations: Processes images based on their shapes, using operations like dilation and erosion, which can be particularly useful in industrial applications for quality control.
- Frequency Domain Techniques:
- Involve transforming images into the frequency domain for analysis.
- Common methods include:
- Fourier Transform: Converts spatial data into frequency data, allowing for filtering and compression, which can optimize storage and transmission of large datasets.
- Wavelet Transform: Provides multi-resolution analysis, useful for image compression and denoising, ensuring that critical details are preserved while reducing file sizes.
- Applications:
- Medical imaging for diagnosis, enhancing the accuracy of healthcare solutions, particularly in medical image segmentation.
- Remote sensing for land use analysis, aiding in environmental monitoring and urban planning.
- Industrial inspection for quality control, ensuring products meet the highest standards.
2.3. Feature Detection and Extraction
Feature detection and extraction are critical steps in image analysis, enabling the identification of significant patterns and structures within images, which can lead to improved operational efficiencies and insights.
- Feature Detection:
- Involves identifying key points or regions in an image that are distinctive and can be used for further analysis.
- Common methods include:
- Corner Detection: Identifies points where edges meet, using algorithms like Harris and Shi-Tomasi, which can enhance object recognition capabilities in various applications.
- Edge Detection: Detects boundaries within images using techniques such as Canny and Sobel operators, crucial for applications in security and surveillance.
- Blob Detection: Identifies regions in an image that differ in properties, using methods like Laplacian of Gaussian (LoG) and Difference of Gaussian (DoG), which can be applied in medical imaging for tumor detection.
- Feature Extraction:
- Involves converting detected features into a format suitable for analysis or classification.
- Common methods include:
- Descriptors: Create numerical representations of features, such as SIFT (Scale-Invariant Feature Transform) and SURF (Speeded-Up Robust Features), enhancing the accuracy of machine learning models.
- Shape Descriptors: Analyze the shape of objects using techniques like Fourier descriptors and contour-based methods, which can improve the performance of automated systems.
- Applications:
- Object recognition in computer vision, leading to enhanced user experiences in various applications.
- Image matching for augmented reality, providing immersive experiences for users.
- Scene understanding in autonomous vehicles, contributing to safer navigation and operation.
2.4. Image Segmentation
Image segmentation is the process of partitioning an image into meaningful segments or regions, making it easier to analyze and interpret, ultimately driving better business decisions.
- Techniques:
- Thresholding: Separates objects from the background based on pixel intensity. Simple methods include global and adaptive thresholding, which can streamline data processing in various applications.
- Clustering: Groups pixels into clusters based on similarity. K-means and Mean Shift are popular clustering algorithms, useful for market segmentation and targeted marketing strategies. K-means clustering in image segmentation is particularly effective for this purpose.
- Edge-Based Segmentation: Utilizes edge detection to identify boundaries between different regions. Techniques include the Canny edge detector and active contours (snakes), enhancing the clarity of images used in presentations.
- Region-Based Segmentation: Groups neighboring pixels with similar properties. Methods include region growing and region splitting and merging, which can improve the accuracy of image analysis.
- Advanced Methods:
- Graph-Based Segmentation: Models the image as a graph and partitions it based on connectivity and similarity, providing a robust framework for complex image analysis tasks.
- Deep Learning Approaches: Utilizes convolutional neural networks (CNNs) for semantic segmentation, allowing for pixel-wise classification, which can significantly enhance the performance of AI-driven applications.
- Applications:
- Medical imaging for tumor detection, improving diagnostic accuracy and patient outcomes.
- Object detection in surveillance systems, enhancing security measures.
- Image editing and manipulation in graphic design, allowing for creative and impactful visual content.
By partnering with Rapid Innovation, clients can leverage these advanced image processing techniques, including image preprocessing in Python and image fusion, to achieve greater ROI, streamline operations, and enhance their product offerings. Our expertise in AI and blockchain development ensures that we deliver tailored solutions that meet the unique needs of each client, driving efficiency and effectiveness in their projects.
3. 3D Vision and Depth Perception
3D vision and depth perception are crucial for understanding the spatial relationships between objects in our environment. These capabilities allow us to navigate, interact, and make decisions based on the three-dimensional layout of the world around us.
- 3D vision refers to the ability to perceive the world in three dimensions, which is essential for tasks such as driving, playing sports, and even simple activities like reaching for an object.
- Depth perception is the visual ability to perceive the distance of objects and their spatial relationships, which is vital for accurate movement and interaction.
3.1. Stereo Vision
Stereo vision is a key mechanism through which humans and many animals achieve depth perception. It relies on the slightly different views of the world that each eye receives.
- Each eye is positioned about 6-7 centimeters apart, providing two distinct perspectives of the same scene.
- The brain processes these two images to create a single three-dimensional perception, allowing us to judge distances accurately.
- This process is known as binocular disparity, where the differences between the images from each eye are analyzed to determine depth.
Key aspects of stereo vision include:
- Binocular Cues: The brain uses the disparity between the images from each eye to gauge how far away an object is. The greater the disparity, the closer the object is perceived to be.
- Monocular Cues: Even with one eye, depth perception can still occur through cues such as size, texture gradient, and motion parallax. For example, objects that are closer appear larger and more detailed than those that are farther away.
- Applications: Stereo vision is widely used in various fields, including robotics, virtual reality, and computer vision, to create more immersive and accurate representations of environments.
3.2. Structured Light
Structured light is a technique used to capture 3D information about an object or scene by projecting a known pattern of light onto it. This method is particularly useful in applications such as 3D scanning and computer vision.
- The basic principle involves projecting a series of light patterns (often stripes or grids) onto the object. The way these patterns deform when they hit the surface provides information about the object's shape and depth.
- A camera captures the deformed patterns, and software analyzes the images to reconstruct the 3D geometry of the object.
Key features of structured light include:
- High Accuracy: This method can achieve high levels of precision in depth measurement, making it suitable for applications requiring detailed 3D models.
- Speed: Structured light systems can capture 3D data quickly, which is beneficial in industrial settings where time efficiency is crucial.
- Versatility: It can be used on various surfaces and materials, including those that are difficult to scan with other methods, such as shiny or transparent objects.
Applications of structured light technology include:
- 3D Scanning: Used in manufacturing, cultural heritage preservation, and medical imaging to create accurate 3D models of objects.
- Robotics: Helps robots understand their environment and navigate effectively by providing depth information.
- Augmented Reality: Enhances user experiences by accurately mapping the physical world and overlaying digital information.
In summary, both stereo vision and structured light are essential components of 3D vision and depth perception, each contributing uniquely to our understanding of spatial relationships in the world. By leveraging these technologies, Rapid Innovation can help clients enhance their projects, improve efficiency, and achieve greater ROI through innovative solutions tailored to their specific needs. Partnering with us means gaining access to cutting-edge expertise that can transform your 3D vision and depth perception into reality.
3.3. Time-of-Flight Cameras
Time-of-Flight (ToF) cameras are advanced imaging devices that measure the time it takes for light to travel from the camera to an object and back. This technology is widely used in various applications, including robotics, augmented reality, and automotive systems.
- How ToF Cameras Work:
- Emit a light signal (usually infrared) towards the scene.
- Measure the time it takes for the light to reflect back to the sensor.
- Calculate the distance to each point in the scene based on the speed of light.
- Key Features:
- Depth Sensing: Provides accurate depth information, allowing for 3D mapping of environments.
- Real-time Processing: Capable of processing data quickly, making it suitable for dynamic environments.
- Compact Design: Often smaller and lighter than traditional 3D imaging systems.
- Applications:
- Gesture Recognition: Used in gaming and smart devices for user interaction.
- Robotics: Helps robots navigate and understand their surroundings.
- Security: Enhances surveillance systems by providing depth information.
- Advantages:
- High Precision: Offers accurate distance measurements.
- Low Light Performance: Functions well in various lighting conditions.
- Cost-Effective: Generally more affordable than other 3D imaging technologies.
Time-of-Flight cameras, including 3D ToF cameras and ToF depth cameras, are essential in creating detailed 3D models of environments. The technology is also referred to as time of flight camera sensor, which emphasizes its capability to measure distances accurately. The compact design of these devices, such as the 3D camera ToF and the 3D ToF camera sensor, makes them suitable for various applications, including depth camera ToF systems that enhance user interaction and security measures.
3.4. LIDAR Technology
LIDAR (Light Detection and Ranging) is a remote sensing method that uses laser light to measure distances to the Earth. It is widely used in various fields, including geography, forestry, and autonomous vehicles.
- How LIDAR Works:
- Emits laser pulses towards a target.
- Measures the time it takes for the pulse to return to the sensor.
- Creates a detailed 3D map of the environment based on the distance measurements.
- Key Features:
- High Resolution: Capable of capturing fine details in the environment.
- Wide Range: Can measure distances over several kilometers.
- 360-Degree Scanning: Some systems can capture data in all directions.
- Applications:
- Autonomous Vehicles: Used for navigation and obstacle detection.
- Environmental Monitoring: Helps in mapping forests, wetlands, and urban areas.
- Archaeology: Assists in discovering and mapping ancient structures.
- Advantages:
- Accuracy: Provides precise measurements, essential for mapping and modeling.
- Versatility: Applicable in various industries and research fields.
- Speed: Can collect large amounts of data quickly.
4. Object Detection and Recognition
Object detection and recognition are critical components of computer vision, enabling machines to identify and classify objects within images or video streams. This technology has numerous applications across different sectors.
- How Object Detection Works:
- Image Acquisition: Captures images or video frames.
- Feature Extraction: Analyzes the image to identify key features.
- Classification: Uses algorithms to classify detected objects.
- Key Techniques:
- Machine Learning: Employs algorithms that learn from data to improve detection accuracy.
- Deep Learning: Utilizes neural networks for more complex recognition tasks.
- Traditional Methods: Includes techniques like Haar cascades and HOG (Histogram of Oriented Gradients).
- Applications:
- Surveillance: Enhances security systems by identifying suspicious activities.
- Retail: Used in inventory management and customer behavior analysis.
- Autonomous Systems: Essential for navigation and obstacle avoidance in drones and robots.
- Advantages:
- Automation: Reduces the need for manual monitoring and analysis.
- Real-time Processing: Enables immediate responses in dynamic environments.
- Scalability: Can be applied to various scales, from small devices to large systems.
At Rapid Innovation, we leverage these advanced technologies to help our clients achieve their goals efficiently and effectively. By integrating ToF cameras, including the 3D time of flight camera and ToF sensor camera, LIDAR, and object detection systems into your projects, we can enhance operational efficiency, improve accuracy, and ultimately drive greater ROI. Partnering with us means you can expect tailored solutions that not only meet your specific needs but also provide significant cost savings and competitive advantages in your industry.
4.1. Traditional Approaches
Traditional approaches to data analysis and problem-solving have been foundational in various fields, including statistics, operations research, and computer science. These methods often rely on established mathematical models and algorithms.
- Statistical Methods:
- Use of descriptive statistics to summarize data, including example descriptive statistics and sample descriptive statistics.
- Inferential statistics to make predictions or generalizations about a population based on sample data, often contrasting descriptive v inferential statistics.
- Rule-based Systems:
- Systems that use predefined rules to make decisions.
- Often employed in expert systems for diagnosis or troubleshooting.
- Linear Regression:
- A method for modeling the relationship between a dependent variable and one or more independent variables.
- Assumes a linear relationship, making it simple but sometimes limited in capturing complex patterns.
- Decision Trees:
- A flowchart-like structure that uses branching methods to illustrate every possible outcome of a decision.
- Easy to interpret but can be prone to overfitting.
- Limitations:
- Often struggle with high-dimensional data.
- May not capture complex relationships effectively.
- Require extensive feature engineering and domain knowledge.
4.2. Machine Learning-based Methods
Machine learning (ML) has revolutionized data analysis by enabling systems to learn from data and improve over time without being explicitly programmed. ML methods can be categorized into supervised, unsupervised, and reinforcement learning.
- Supervised Learning:
- Involves training a model on labeled data.
- Common algorithms include:
- Support Vector Machines (SVM)
- Random Forests
- Gradient Boosting Machines (GBM)
- Unsupervised Learning:
- Deals with unlabeled data to find hidden patterns.
- Techniques include:
- Clustering (e.g., K-means, Hierarchical clustering)
- Dimensionality Reduction (e.g., PCA, t-SNE)
- Reinforcement Learning:
- Focuses on training agents to make decisions by rewarding desired actions.
- Applications include robotics, gaming, and autonomous systems.
- Advantages:
- Can handle large datasets and high-dimensional spaces.
- Capable of discovering complex patterns without explicit programming.
- Often requires less domain knowledge compared to traditional methods.
- Limitations:
- Requires substantial amounts of data for training.
- Can be computationally intensive.
- Risk of overfitting if not properly managed.
4.3. Deep Learning and Convolutional Neural Networks
Deep learning is a subset of machine learning that uses neural networks with many layers (deep networks) to model complex patterns in data. Convolutional Neural Networks (CNNs) are a specific type of deep learning architecture particularly effective for image processing.
- Neural Networks:
- Composed of interconnected nodes (neurons) organized in layers.
- Each layer transforms the input data, allowing the model to learn hierarchical features.
- Convolutional Neural Networks (CNNs):
- Specifically designed for processing grid-like data, such as images.
- Utilize convolutional layers to automatically extract features from images.
- Include pooling layers to reduce dimensionality and computational load.
- Applications:
- Image and video recognition (e.g., facial recognition, object detection).
- Natural language processing (e.g., sentiment analysis, language translation).
- Medical diagnosis (e.g., analyzing medical images).
- Advantages:
- Capable of learning complex representations directly from raw data.
- Achieve state-of-the-art performance in various tasks, especially in computer vision.
- Reduce the need for manual feature extraction.
- Limitations:
- Require large amounts of labeled data for effective training.
- Computationally expensive, often needing specialized hardware (e.g., GPUs).
- Can be seen as "black boxes," making interpretation of results challenging.
At Rapid Innovation, we leverage these advanced methodologies to help our clients achieve their goals efficiently and effectively. By integrating machine learning and deep learning techniques into your operations, we can enhance your data analysis capabilities, leading to greater ROI. Our expertise allows us to tailor solutions that not only meet your specific needs but also drive innovation and growth.
When you partner with us, you can expect:
- Increased Efficiency: Streamlined processes through automation and intelligent systems.
- Enhanced Decision-Making: Data-driven insights that empower your strategic choices.
- Scalability: Solutions that grow with your business, adapting to changing demands.
- Cost Savings: Optimized resource allocation and reduced operational costs.
Let us help you navigate the complexities of AI and blockchain technology to unlock new opportunities for your business. We also offer online courses in data analysis, covering various data analysis methods and techniques, including exploratory analysis and qualitative analysis, to further enhance your skills in this field. Additionally, we utilize the Grubbs outlier test as part of our data analysis methodology to ensure data integrity and accuracy.
For more insights on how AI is enhancing design and building efficiency, check out AI in Architecture: Enhancing Design and Building Efficiency.
4.4. Instance Segmentation
Instance segmentation is a computer vision task that involves detecting and delineating each object instance within an image. Unlike semantic segmentation, which classifies each pixel into a category, instance segmentation distinguishes between different objects of the same class.
Key features of instance segmentation:
- Object Detection: Identifies the presence of objects in an image.
- Pixel-wise Segmentation: Assigns a label to each pixel, indicating which object it belongs to.
- Instance Differentiation: Differentiates between multiple instances of the same object class.
Applications of instance segmentation:
- Autonomous Vehicles: Helps in identifying pedestrians, vehicles, and obstacles on the road.
- Medical Imaging: Assists in segmenting different anatomical structures in medical scans.
- Robotics: Enables robots to interact with objects by recognizing and locating them.
Popular algorithms for instance segmentation:
- Mask R-CNN: Extends Faster R-CNN by adding a branch for predicting segmentation masks.
- YOLACT: A real-time instance segmentation model that combines speed and accuracy.
- DeepLab: Utilizes atrous convolution for dense feature extraction and segmentation.
Challenges in instance segmentation:
- Occlusion: Objects may overlap, making it difficult to segment them accurately.
- Variability: Different object shapes, sizes, and appearances can complicate detection.
- Computational Complexity: High-resolution images require significant processing power.
5. Visual Simultaneous Localization and Mapping (SLAM)
Visual Simultaneous Localization and Mapping (SLAM) is a technique used in robotics and computer vision to create a map of an unknown environment while simultaneously keeping track of the agent's location within that environment. It relies on visual data from cameras to achieve this.
Core components of visual SLAM:
- Mapping: Building a representation of the environment.
- Localization: Determining the position and orientation of the camera or robot.
- Data Association: Matching observed features in the environment with previously mapped features.
Benefits of visual SLAM:
- Real-time Processing: Enables immediate feedback for navigation and mapping.
- Low-cost Sensors: Utilizes inexpensive cameras instead of costly LiDAR systems.
- Robustness: Can operate in various environments, including indoor and outdoor settings.
Applications of visual SLAM:
- Robotics: Used in autonomous robots for navigation and obstacle avoidance.
- Augmented Reality: Enhances user experience by accurately overlaying digital content on the real world.
- Drones: Assists in autonomous flight and mapping of areas.
5.1. Principles of SLAM
The principles of SLAM revolve around the integration of perception and motion estimation to achieve simultaneous mapping and localization. The process can be broken down into several key principles:
- Sensor Fusion: Combines data from multiple sensors (e.g., cameras, IMUs) to improve accuracy.
- Feature Extraction: Identifies key points or features in the environment that can be tracked over time.
- State Estimation: Uses algorithms like Kalman filters or particle filters to estimate the current state of the system.
- Loop Closure: Detects when the agent revisits a previously mapped area to correct drift in the map and improve accuracy.
SLAM algorithms can be categorized into:
- Filter-based SLAM: Uses probabilistic methods to estimate the state of the system.
- Graph-based SLAM: Constructs a graph where nodes represent poses and edges represent spatial constraints.
Challenges in SLAM:
- Dynamic Environments: Moving objects can introduce noise and inaccuracies in the map.
- Scale Drift: Errors can accumulate over time, leading to inaccuracies in the map.
- Computational Load: Real-time processing requires efficient algorithms to handle large amounts of data.
Recent advancements in SLAM:
- Deep Learning: Incorporating neural networks for feature extraction and data association.
- Multi-View Geometry: Using multiple camera views to enhance mapping accuracy.
- Robustness to Illumination Changes: Developing algorithms that can adapt to varying lighting conditions.
At Rapid Innovation, we understand the complexities and challenges associated with advanced technologies like instance segmentation and visual SLAM. Our expertise in AI and blockchain development allows us to provide tailored solutions that help our clients achieve their goals efficiently and effectively.
By partnering with us, clients can expect:
- Increased ROI: Our innovative solutions are designed to optimize processes, reduce costs, and enhance productivity, leading to a greater return on investment.
- Expert Guidance: Our team of experienced professionals will work closely with you to understand your unique needs and provide strategic insights that drive success.
- Cutting-edge Technology: We leverage the latest advancements in AI and blockchain to deliver solutions that are not only effective but also future-proof.
- Scalability: Our solutions are designed to grow with your business, ensuring that you can adapt to changing market demands without compromising on quality.
Let us help you navigate the complexities of technology and unlock new opportunities for growth and success.
5.2. Feature-based SLAM
Feature-based SLAM (Simultaneous Localization and Mapping) is a method that relies on identifying and tracking distinct features in the environment to build a map and localize the sensor within that map. This approach is widely used in robotics, including applications in slam robotics and slam technology, as well as in computer vision.
- Key characteristics:
- Utilizes identifiable landmarks or features (e.g., corners, edges) in the environment.
- Extracts features from sensor data (like images) using algorithms such as SIFT, SURF, or ORB.
- Matches features across different frames to estimate motion and update the map.
- Advantages:
- Robust to changes in lighting and perspective.
- Efficient in terms of computational resources, as it focuses on a limited number of features.
- Can work well in environments with rich textures, making it suitable for applications like slam scanning and slam lidar.
- Disadvantages:
- Performance can degrade in feature-poor environments (e.g., plain walls).
- Requires good feature extraction and matching algorithms to ensure accuracy.
- May struggle with dynamic environments where features change over time, such as in slam autonomous driving or slam self driving car scenarios.
5.3. Direct SLAM Methods
Direct SLAM methods differ from feature-based approaches by using the raw pixel intensity values from images rather than extracting features. This technique focuses on minimizing the photometric error between images to estimate motion and build a map.
- Key characteristics:
- Operates directly on image pixel values, making it sensitive to lighting conditions.
- Uses techniques like bundle adjustment to optimize the camera pose and map simultaneously.
- Often employs depth information from stereo cameras or depth sensors.
- Advantages:
- Can provide dense mapping, capturing more information about the environment.
- Less dependent on feature extraction, which can be beneficial in texture-less environments.
- Generally more accurate in terms of motion estimation due to the use of all pixel information.
- Disadvantages:
- Computationally intensive, requiring more processing power and memory.
- Sensitive to changes in lighting and occlusions, which can affect performance.
- May require careful calibration of sensors to ensure accuracy.
5.4. Visual Odometry
Visual odometry is a technique used to estimate the motion of a camera by analyzing the sequence of images it captures. It is often a component of SLAM systems but can also be used independently for navigation, including applications in ar slam and slam in ar.
- Key characteristics:
- Focuses on estimating the trajectory of the camera based on visual input.
- Can be implemented using either feature-based or direct methods.
- Often involves calculating the relative motion between consecutive frames.
- Advantages:
- Provides real-time motion estimation, which is crucial for navigation tasks.
- Can be used in conjunction with other sensors (e.g., IMU) for improved accuracy.
- Works well in environments where GPS signals are weak or unavailable.
- Disadvantages:
- Accumulation of errors over time can lead to drift, requiring periodic correction.
- Performance can be affected by rapid motion, lighting changes, or lack of texture.
- May require additional algorithms for loop closure to correct drift and improve accuracy, especially in applications like slam autonomous vehicles and slam drone.
At Rapid Innovation, we understand the complexities of implementing advanced technologies like SLAM, and we are here to guide you through the process. Our expertise in AI and Blockchain development allows us to tailor solutions that not only meet your specific needs but also enhance your operational efficiency. By partnering with us, you can expect a significant return on investment (ROI) through improved accuracy, reduced operational costs, and faster time-to-market for your projects.
Our team is dedicated to ensuring that you leverage the latest advancements in technology to achieve your goals effectively. Whether you are looking to enhance your robotics capabilities or improve your navigation systems, we provide the insights and support necessary to drive your success. With Rapid Innovation, you can expect a collaborative approach that prioritizes your objectives and delivers measurable results.
6. Motion Tracking and Estimation
At Rapid Innovation, we recognize that motion tracking and estimation are pivotal in various sectors, including robotics, computer vision, and augmented reality. Our expertise in these areas enables us to help clients understand and predict the movement of objects over time, which is essential for tasks such as navigation, object recognition, and interaction. By leveraging our advanced solutions, clients can achieve their goals efficiently and effectively, ultimately leading to greater ROI.
6.1. Optical Flow
Optical flow refers to the pattern of apparent motion of objects in a visual scene based on the movement of the observer. It is a technique used to estimate the motion of objects between two consecutive frames of video or images.
- Key concepts:
- Optical flow is derived from the changes in intensity patterns in the image.
- It assumes that the brightness of an object remains constant as it moves.
- The flow can be represented as a vector field, where each vector indicates the direction and speed of motion.
- Applications:
- Object tracking: Optical flow can be used to follow moving objects in video sequences, enhancing surveillance and monitoring systems.
- Motion analysis: It helps in understanding the dynamics of moving objects, which is useful in sports analytics and performance optimization.
- Robot navigation: Robots can utilize optical flow to avoid obstacles and navigate through environments, improving operational efficiency.
- Techniques:
- Lucas-Kanade method: A widely used differential method that assumes a small motion between frames and computes the flow based on local image gradients.
- Horn-Schunck method: A global method that imposes smoothness constraints on the flow field, providing a dense optical flow estimation.
- Limitations:
- Sensitive to noise: Optical flow can be affected by noise in the image, leading to inaccurate motion estimates.
- Assumes constant brightness: The assumption that brightness remains constant may not hold in all scenarios, especially in dynamic lighting conditions.
6.2. Kalman Filtering
Kalman filtering is a mathematical technique used for estimating the state of a dynamic system from a series of noisy measurements. It is particularly effective in applications where the system is subject to random disturbances.
- Key concepts:
- The Kalman filter operates in two steps: prediction and update.
- It uses a series of measurements observed over time to produce estimates of unknown variables.
- The filter assumes that both the process and measurement noise are Gaussian.
- Applications:
- Robotics: Kalman filters are used for sensor fusion, combining data from various sensors to improve the accuracy of position and velocity estimates, leading to enhanced robotic performance.
- Navigation: It is widely used in GPS and inertial navigation systems to provide accurate location tracking, ensuring reliable navigation solutions.
- Finance: Kalman filters can be applied to estimate the state of financial markets, helping in predicting stock prices and making informed investment decisions.
- Advantages:
- Real-time processing: Kalman filters can process measurements in real-time, making them suitable for dynamic systems and applications requiring immediate feedback.
- Optimal estimation: It provides the best linear unbiased estimate of the system state, minimizing the mean of the squared errors, which is crucial for high-stakes applications.
- Limitations:
- Linear assumptions: The standard Kalman filter assumes linearity in the system dynamics, which may not be applicable in all cases.
- Requires accurate models: The performance of the filter heavily relies on the accuracy of the system and measurement models.
In summary, both optical flow and Kalman filtering are essential techniques in motion tracking and estimation, each with its unique strengths and applications. By partnering with Rapid Innovation, clients can harness these advanced methodologies to improve performance across various technological fields, ultimately driving greater ROI and achieving their strategic objectives.
6.3. Particle Filters
Particle filters are a set of algorithms used for estimating the state of a system that changes over time. They are particularly useful in robotics and computer vision for tasks such as localization and tracking, including applications in robotic navigation, such as slam navigation and ros navigation.
- Basic Concept:
- Particle filters represent the probability distribution of a system's state using a set of particles, each representing a possible state.
- Each particle has a weight that reflects how well it matches the observed data.
- Process:
- Prediction: Each particle is moved according to a motion model, simulating the system's dynamics.
- Update: The weights of the particles are updated based on the likelihood of the observed data given the particle's state.
- Resampling: Particles with low weights are discarded, while those with high weights are replicated, focusing on the most probable states.
- Applications:
- Used in robot localization to estimate a robot's position and orientation in an environment, applicable in technologies like lidar navigation and slam robot navigation.
- Effective in tracking moving objects in video sequences.
- Advantages:
- Can handle non-linear and non-Gaussian processes.
- Flexible and can be adapted to various types of problems, including autonomous navigation robot systems.
- Challenges:
- Computationally intensive, especially with a large number of particles.
- Requires careful tuning of parameters to achieve optimal performance.
6.4. Visual Servoing
Visual servoing is a technique in robotics that uses visual information from cameras to control the motion of a robot. It integrates computer vision and control theory to achieve precise manipulation and navigation, which is essential in applications like ros robot navigation and vslam navigation.
- Types of Visual Servoing:
- Position-Based Visual Servoing (PBVS):
- Uses 3D information to control the robot's position relative to the target.
- Requires accurate 3D models of the environment.
- Image-Based Visual Servoing (IBVS):
- Directly uses image features to control the robot's motion.
- More robust to changes in the environment but may require more complex algorithms.
- Position-Based Visual Servoing (PBVS):
- Process:
- Feature Extraction: Identify key features in the image that represent the target.
- Control Law: Develop a control law that adjusts the robot's motion based on the difference between the desired and current feature positions.
- Feedback Loop: Continuously update the robot's motion based on real-time visual feedback.
- Applications:
- Used in robotic arms for tasks like assembly, pick-and-place, and manipulation.
- Essential in autonomous vehicles for navigation and obstacle avoidance, including applications in robotic navigation like autonomous navigation robot and amr navigation.
- Advantages:
- Allows for real-time adjustments based on visual feedback.
- Can operate in dynamic environments where pre-defined paths may not be feasible.
- Challenges:
- Sensitive to changes in lighting and occlusions.
- Requires robust feature extraction and matching algorithms.
7. Robotic Navigation using Computer Vision
Robotic navigation using computer vision involves the use of visual data to help robots understand and navigate their environment. This approach combines various techniques from computer vision, machine learning, and robotics, including methods like 3d slam navigation and ros autonomous navigation.
- Key Components:
- Perception: Robots use cameras and sensors to gather visual information about their surroundings.
- Mapping: Creating a map of the environment using visual data, often employing techniques like SLAM (Simultaneous Localization and Mapping), which can include technologies like excelsius gps robot and remi robotic navigation system.
- Path Planning: Determining the best route to a destination while avoiding obstacles.
- Techniques:
- Feature Detection and Matching: Identifying and matching key features in the environment to aid in navigation.
- Depth Estimation: Using stereo vision or depth sensors to understand the distance to objects.
- Optical Flow: Analyzing the motion of objects in the visual field to infer the robot's movement.
- Applications:
- Autonomous vehicles use computer vision for lane detection, obstacle avoidance, and traffic sign recognition.
- Drones utilize visual navigation for tasks like surveying and mapping, which can be enhanced with technologies like arduino robot gps navigation and lidar navigation.
- Advantages:
- Provides rich information about the environment, enabling more informed decision-making.
- Can adapt to changes in the environment in real-time.
- Challenges:
- Computationally demanding, requiring powerful processing capabilities.
- Performance can be affected by environmental factors such as lighting, weather, and occlusions.
At Rapid Innovation, we leverage advanced technologies like particle filters and visual servoing to enhance robotic navigation and tracking capabilities. By partnering with us, clients can expect to achieve greater ROI through improved efficiency, reduced operational costs, and enhanced decision-making processes. Our expertise in AI and blockchain development ensures that we provide tailored solutions that meet the unique needs of each client, ultimately driving innovation and success in their projects, including those focused on robotic navigation such as arduino autonomous robot navigation and agv lidar navigation.
7.1. Path Planning
Path planning is a critical component in robotics and autonomous systems, enabling them to navigate from one point to another efficiently and safely. It involves determining the best route while considering various constraints and objectives.
- Algorithms: Common algorithms used in path planning include A*, Dijkstra's, and Rapidly-exploring Random Trees (RRT). Each has its strengths depending on the environment and requirements. Best path planning algorithms are essential for optimizing routes in complex scenarios.
- Factors to consider:
- Environment complexity: The presence of obstacles, terrain types, and dynamic elements can affect path planning, especially in multi robot path planning scenarios.
- Computational efficiency: The algorithm must balance accuracy with speed, especially in real-time applications like mobile robot motion planning.
- Goal-oriented: The path should not only reach the destination but also optimize for factors like distance, time, and energy consumption, which is crucial in robot trajectory planning.
- Applications: Path planning is used in various fields, including:
- Autonomous vehicles for route optimization.
- Robotics for task execution in manufacturing and service industries, including path planning robotics.
- Drones for efficient flight paths in delivery and surveillance, utilizing techniques like collision free path planning.
- Manipulator path planning for robotic arms, ensuring precise movements.
- 3D motion planning for navigating complex environments.
- Arduino path planning for small-scale robotics projects.
7.2. Obstacle Detection and Avoidance
Obstacle detection and avoidance are essential for ensuring the safety and efficiency of autonomous systems. This process involves identifying potential obstacles in the environment and taking appropriate actions to avoid collisions.
- Sensor technologies: Various sensors are employed for obstacle detection, including:
- Lidar: Provides high-resolution 3D mapping of the environment.
- Cameras: Used for visual recognition of obstacles and features.
- Ultrasonic sensors: Effective for short-range detection.
- Techniques for avoidance:
- Reactive methods: These involve immediate responses to detected obstacles, often using simple rules to change direction or speed.
- Predictive methods: These analyze the environment and predict potential obstacles' movements, allowing for preemptive actions.
- Challenges:
- Dynamic environments: Moving obstacles, such as pedestrians or vehicles, require real-time processing and adaptability.
- Sensor limitations: Factors like weather conditions and sensor range can affect detection accuracy.
- Applications: Obstacle detection and avoidance are crucial in:
- Autonomous vehicles navigating urban environments.
- Drones avoiding obstacles during flight.
- Robotic vacuum cleaners maneuvering around furniture.
7.3. Visual Landmarks and Mapping
Visual landmarks and mapping play a vital role in helping autonomous systems understand and navigate their environments. This involves recognizing key features and creating a spatial representation of the surroundings.
- Landmark recognition: Visual landmarks are distinctive features in the environment that can be used for navigation. These may include:
- Buildings, trees, or unique structures.
- Road signs and traffic signals.
- Natural features like mountains or rivers.
- Mapping techniques:
- Simultaneous Localization and Mapping (SLAM): This technique allows a robot to build a map of an unknown environment while keeping track of its location within that map.
- Feature-based mapping: Involves identifying and using specific features to create a map, which can be more efficient in certain scenarios.
- Importance of mapping:
- Enhances navigation accuracy by providing a reference for the robot's position.
- Facilitates path planning by allowing the system to understand the layout of the environment.
- Applications: Visual landmarks and mapping are utilized in:
- Autonomous vehicles for navigation and route planning.
- Robotics in indoor environments, such as warehouses or homes.
- Augmented reality systems that overlay information on real-world views.
At Rapid Innovation, we leverage our expertise in AI and blockchain technologies to enhance these critical components of autonomous systems. By partnering with us, clients can expect tailored solutions that not only improve operational efficiency but also drive greater ROI. Our team is dedicated to helping you navigate the complexities of technology implementation, ensuring that your projects are completed on time and within budget. With our innovative approach, we empower businesses to achieve their goals effectively and efficiently.
8. Human-Robot Interaction through Vision
Human-robot interaction (HRI) is a rapidly evolving field that focuses on how robots can effectively communicate and collaborate with humans. Vision-based systems play a crucial role in enhancing this interaction, allowing robots to perceive and interpret human actions and emotions. This section delves into two key aspects of HRI through vision: gesture recognition and facial expression analysis.
8.1. Gesture Recognition
Gesture recognition is the process by which a robot interprets human gestures as commands or signals. This capability is essential for creating intuitive and natural interactions between humans and robots.
Types of gestures:
- Static gestures: These are hand positions or postures that convey specific meanings.
- Dynamic gestures: These involve movement, such as waving or pointing, and can indicate actions or requests.
Technologies used:
- Computer vision: Algorithms analyze video feeds to detect and interpret gestures.
- Depth sensors: Devices like Microsoft Kinect or Intel RealSense capture 3D data to enhance gesture recognition accuracy.
Applications:
- Robotic assistants: Robots can respond to user gestures, making them more user-friendly.
- Gaming: Gesture recognition enhances user experience in interactive gaming environments, including human robot games.
- Healthcare: Gesture-based controls can assist patients with mobility issues in interacting with devices.
Challenges:
- Variability in gestures: Different individuals may perform the same gesture differently.
- Environmental factors: Lighting and background can affect recognition accuracy.
- Real-time processing: Ensuring quick response times is critical for effective interaction.
8.2. Facial Expression Analysis
Facial expression analysis involves the interpretation of human emotions through facial cues. This capability allows robots to understand and respond to human feelings, enhancing the emotional aspect of HRI.
Key components:
- Facial landmarks: Specific points on the face, such as the eyes, mouth, and nose, are tracked to identify expressions.
- Emotion recognition: Algorithms classify expressions into categories like happiness, sadness, anger, and surprise.
Technologies used:
- Machine learning: Models are trained on large datasets of facial expressions to improve recognition accuracy.
- Deep learning: Convolutional neural networks (CNNs) are often employed for more nuanced analysis.
Applications:
- Social robots: Robots designed for companionship can adjust their behavior based on the emotional state of their human counterparts, enhancing social human robot interaction.
- Customer service: Robots in retail can gauge customer satisfaction and tailor their responses accordingly.
- Therapeutic settings: Robots can assist in therapy by recognizing and responding to patients' emotional needs.
Challenges:
- Cultural differences: Facial expressions can vary significantly across cultures, complicating recognition.
- Subtle expressions: Detecting slight changes in facial expressions can be difficult.
- Privacy concerns: The use of facial recognition technology raises ethical questions regarding surveillance and consent.
At Rapid Innovation, we leverage our expertise in AI and blockchain to enhance HRI technologies, including cognitive human robot interaction and computational human robot interaction, ensuring that our clients can achieve greater ROI through innovative solutions. By partnering with us, customers can expect improved efficiency, enhanced user experiences, and the ability to stay ahead in a competitive landscape. Our tailored consulting services and development solutions are designed to meet the unique needs of each client, driving success in their projects related to human robot interaction an introduction and types of human robot interaction.
8.3. Pose Estimation
Pose estimation is a critical aspect of computer vision that involves determining the position and orientation of an object or a person in a given space. This technology is widely used in various applications, including robotics, augmented reality, and human-computer interaction.
- Definition: Pose estimation can be defined as the process of identifying the spatial configuration of an object or a person, typically represented by a set of key points or a bounding box.
- Types of Pose Estimation:
- 2D Pose Estimation: Involves detecting key points in a two-dimensional image, often used for human pose tracking.
- 3D Pose Estimation: Extends the concept to three dimensions, providing depth information and allowing for more accurate spatial representation.
- Techniques:
- Model-based methods: Use predefined models of objects or humans to estimate pose.
- Learning-based methods: Utilize machine learning algorithms, particularly deep learning, to learn pose estimation from large datasets.
- Applications:
- Robotics: Enables robots to understand their environment and interact with objects or humans effectively.
- Augmented Reality: Enhances user experience by overlaying digital information on the real world based on the user's pose. This is particularly relevant in pose estimation for augmented reality a hands-on survey.
- Sports Analytics: Analyzes athletes' movements to improve performance and technique.
- Challenges:
- Occlusion: Difficulty in estimating pose when parts of the object or person are hidden.
- Variability: Changes in appearance due to different lighting conditions, clothing, or body shapes can affect accuracy.
- Tools and Frameworks: Popular libraries for pose estimation include OpenPose, AlphaPose, and MediaPipe. The advancements in pose estimation technology continue to drive innovation in various fields, including Pose Estimation's Impact on Gaming & Entertainment.
9. Advanced Topics in Computer Vision for Robotics
Advanced topics in computer vision for robotics encompass a range of sophisticated techniques and methodologies that enhance the capabilities of robots in understanding and interacting with their environment.
- Object Recognition: Identifying and classifying objects within an image or video stream, crucial for tasks like navigation and manipulation.
- Scene Understanding: Involves interpreting the context of a scene, including identifying relationships between objects and their surroundings.
- Visual SLAM (Simultaneous Localization and Mapping): A technique that allows robots to build a map of an unknown environment while keeping track of their location within it.
- Depth Perception: Utilizing stereo vision or depth sensors to perceive the distance of objects, aiding in navigation and obstacle avoidance.
- Semantic Segmentation: The process of classifying each pixel in an image into predefined categories, providing a detailed understanding of the scene.
- Human-Robot Interaction: Developing systems that allow robots to understand and respond to human actions and intentions effectively.
9.1. Multi-sensor Fusion
Multi-sensor fusion refers to the integration of data from multiple sensors to improve the accuracy and reliability of information used in robotics and computer vision applications.
- Definition: The process of combining sensory data from various sources to create a more comprehensive understanding of the environment.
- Benefits:
- Enhanced Accuracy: Combining data from different sensors can reduce errors and improve the overall accuracy of measurements.
- Robustness: Multi-sensor systems are more resilient to sensor failures or inaccuracies, as they can rely on alternative data sources.
- Improved Perception: Fusing data from sensors like cameras, LiDAR, and IMUs (Inertial Measurement Units) provides a richer understanding of the environment.
- Techniques:
- Kalman Filtering: A mathematical approach used to estimate the state of a dynamic system from a series of noisy measurements.
- Particle Filtering: A method that uses a set of particles to represent the probability distribution of a system's state, useful in non-linear and non-Gaussian scenarios.
- Deep Learning: Leveraging neural networks to learn how to combine data from multiple sensors effectively.
- Applications:
- Autonomous Vehicles: Use multi-sensor fusion to navigate safely by integrating data from cameras, radar, and LiDAR.
- Robotics: Enhances robot perception for tasks like object manipulation and navigation in complex environments.
- Augmented Reality: Combines data from cameras and motion sensors to create immersive experiences.
- Challenges:
- Data Synchronization: Ensuring that data from different sensors is aligned in time and space can be complex.
- Computational Complexity: Fusing data from multiple sources can require significant processing power and sophisticated algorithms.
- Sensor Calibration: Accurate calibration of sensors is essential for effective fusion, as misalignment can lead to errors in perception.
At Rapid Innovation, we leverage our expertise in these advanced technologies to help clients achieve their goals efficiently and effectively. By partnering with us, clients can expect enhanced accuracy, improved operational efficiency, and a greater return on investment (ROI) through tailored solutions that meet their specific needs. Our commitment to innovation ensures that we stay at the forefront of technology, providing our clients with the tools they need to succeed in a rapidly evolving landscape. For more information on our offerings, visit Pose Estimation Solutions & Services | Rapid Innovation.
9.2. Event-based Vision
Event-based vision is a novel approach to visual perception that captures changes in a scene rather than traditional frame-based images. This technology is inspired by the way biological systems, particularly the human eye, perceive motion and changes in the environment.
- Event-driven data: Unlike conventional cameras that capture frames at fixed intervals, event-based cameras, including event based sensors, detect changes in the scene asynchronously. They generate data only when there is a change in brightness, resulting in a stream of events that indicate the time, location, and intensity of changes.
- High temporal resolution: Event-based vision systems can achieve temporal resolutions in the microsecond range, allowing them to capture fast-moving objects and dynamic scenes that traditional cameras might miss.
- Reduced data redundancy: By focusing only on changes, event-based cameras produce significantly less data compared to frame-based systems, which can lead to more efficient processing and storage.
- Robustness to motion blur: Since event-based cameras capture changes in real-time, they are less susceptible to motion blur, making them ideal for applications in robotics and autonomous vehicles.
- Applications: Event-based vision is being explored in various fields, including:
- Robotics for navigation and obstacle avoidance
- Augmented and virtual reality for enhanced user experiences
- Surveillance systems for detecting unusual activities
- Event based vision sensors for improved accuracy in dynamic environments
- Sony event based vision sensor technology for advanced imaging solutions
- Eventbased vision technology in smart surveillance systems
9.3. Reinforcement Learning for Vision-based Tasks
Reinforcement learning (RL) is a machine learning paradigm where an agent learns to make decisions by interacting with an environment. When combined with vision-based tasks, RL can significantly enhance the performance of systems that require visual perception.
- Learning from interaction: In RL, agents learn optimal policies through trial and error, receiving rewards or penalties based on their actions. This approach is particularly useful in vision-based tasks where the environment is dynamic and complex.
- Vision as input: RL algorithms can utilize visual data as input, allowing agents to make informed decisions based on what they see. This is crucial for tasks such as:
- Object recognition and manipulation
- Navigation in unknown environments
- Game playing, where visual feedback is essential
- Deep reinforcement learning: The integration of deep learning with RL has led to significant advancements. Deep reinforcement learning (DRL) uses neural networks to process visual inputs, enabling agents to learn from high-dimensional data effectively.
- Challenges: While RL for vision-based tasks shows promise, it also faces challenges, including:
- Sample inefficiency: RL often requires a large number of interactions to learn effectively.
- Generalization: Agents may struggle to generalize learned behaviors to new, unseen environments.
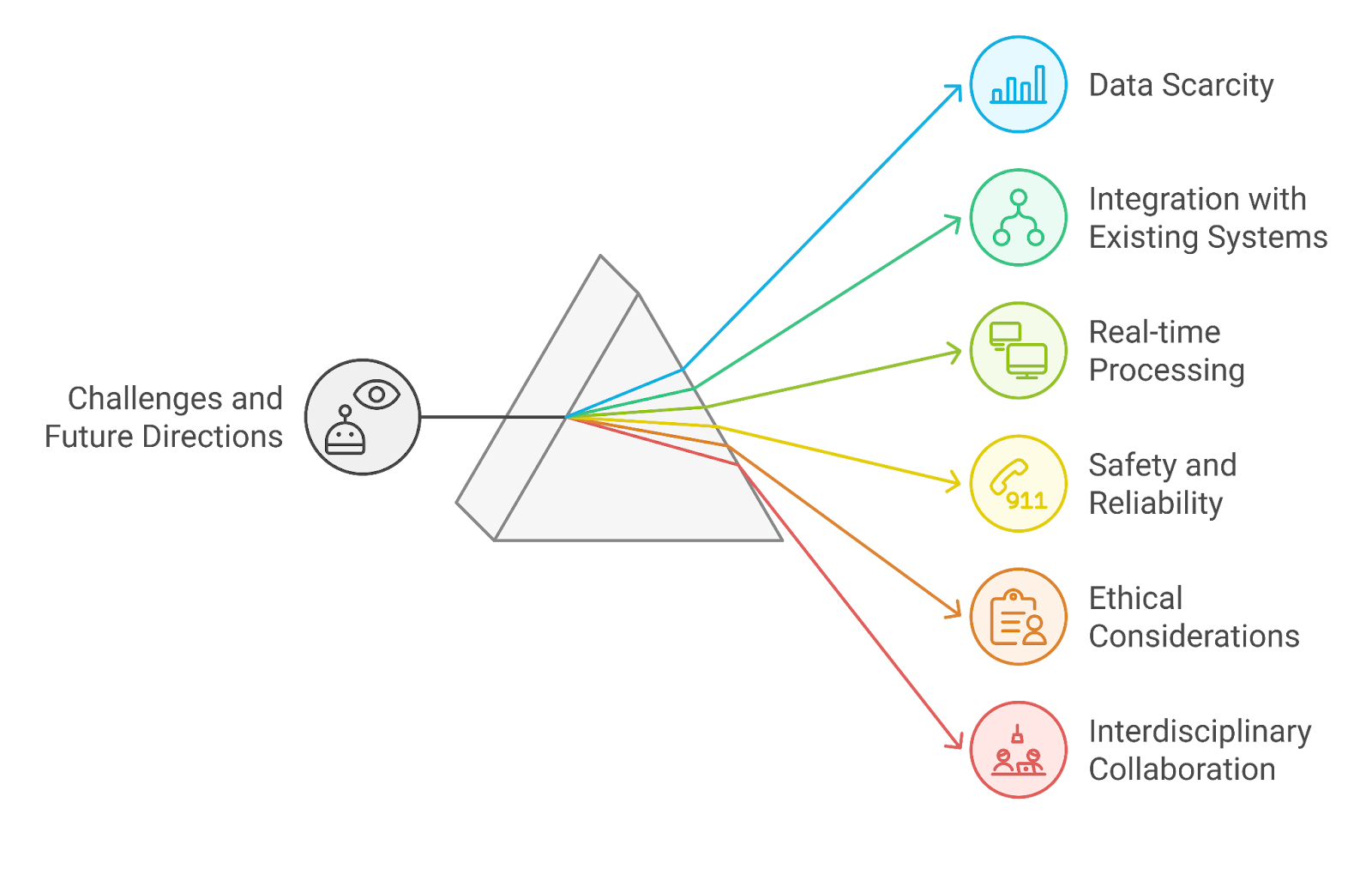
10. Challenges and Future Directions
The fields of event-based vision and reinforcement learning for vision-based tasks are rapidly evolving, but they face several challenges that need to be addressed for further advancements.
- Data scarcity: Event-based vision systems often lack large labeled datasets for training, which can hinder the development of robust algorithms. Future research may focus on generating synthetic data or developing unsupervised learning techniques.
- Integration with existing systems: Combining event-based vision with traditional frame-based systems poses challenges in terms of data fusion and processing. Developing hybrid models that leverage the strengths of both approaches could be a promising direction.
- Real-time processing: Achieving real-time performance in reinforcement learning for vision-based tasks remains a challenge. Future work may explore more efficient algorithms and hardware acceleration to improve processing speeds.
- Safety and reliability: In applications such as autonomous driving, ensuring the safety and reliability of vision-based systems is critical. Research into robust algorithms that can handle unexpected scenarios is essential.
- Ethical considerations: As these technologies advance, ethical concerns regarding privacy, surveillance, and decision-making in critical applications must be addressed. Developing guidelines and frameworks for responsible use will be important.
- Interdisciplinary collaboration: The future of event-based vision and reinforcement learning will benefit from collaboration across disciplines, including neuroscience, robotics, and computer vision. This interdisciplinary approach can lead to innovative solutions and applications.
At Rapid Innovation, we leverage these cutting-edge technologies to help our clients achieve their goals efficiently and effectively. By integrating event-based vision and reinforcement learning into your projects, we can enhance your systems' performance, reduce costs, and ultimately drive greater ROI. Partnering with us means you can expect innovative solutions tailored to your specific needs, expert guidance throughout the development process, and a commitment to delivering results that exceed your expectations. Let us help you navigate the complexities of AI and blockchain technology to unlock new opportunities for growth and success.
10.1. Real-time Processing
Real-time processing refers to the capability of a system to process data and provide output almost instantaneously. This is crucial in various applications where timely responses are essential, such as realtime data processing and real time processing.
- Enables immediate decision-making in critical situations, such as in autonomous vehicles or medical monitoring systems, allowing businesses to enhance safety and operational efficiency.
- Supports applications in finance, where stock trading algorithms need to react to market changes within milliseconds, ensuring clients can capitalize on market opportunities swiftly.
- Utilizes advanced algorithms and hardware to minimize latency, ensuring that data is processed as it is received, which can significantly improve user satisfaction and engagement.
- Often involves the use of edge computing, where data processing occurs closer to the source, reducing the time taken to send data to a central server, thus optimizing resource utilization.
- Real-time processing is essential in industries like telecommunications, gaming, and online services, where user experience is heavily dependent on speed, ultimately leading to higher customer retention and loyalty. This includes real time data integration, real time data analysis, and real time data enrichment.
10.2. Robustness in Varying Environments
Robustness in varying environments refers to a system's ability to maintain performance and reliability despite changes in conditions or unexpected challenges.
- Systems must be designed to handle fluctuations in temperature, humidity, and other environmental factors without compromising functionality, ensuring uninterrupted service delivery.
- Robustness is critical in sectors like aerospace, where equipment must operate under extreme conditions, thereby safeguarding investments and enhancing operational reliability.
- Incorporates redundancy and fail-safes to ensure continued operation in case of component failure, which can significantly reduce downtime and associated costs.
- In software, robustness can be achieved through error handling and recovery mechanisms that allow systems to adapt to unexpected inputs or situations, thereby improving overall system integrity.
- Testing in diverse scenarios is essential to identify potential weaknesses and improve system resilience, ultimately leading to greater customer trust and satisfaction.
10.3. Energy Efficiency
Energy efficiency is the ability of a system to perform its functions while consuming the least amount of energy possible. This is increasingly important in today's technology-driven world.
- Reduces operational costs and environmental impact, making it a priority for both businesses and consumers, which can enhance brand reputation and customer loyalty.
- Involves optimizing algorithms and hardware to minimize energy consumption without sacrificing performance, leading to improved profitability for clients.
- Energy-efficient systems can lead to longer battery life in portable devices, enhancing user convenience and satisfaction, which can drive repeat business.
- The use of renewable energy sources and smart grid technologies can further improve energy efficiency in larger systems, aligning with corporate sustainability goals.
- Regulatory standards and certifications, such as Energy Star, encourage the development of energy-efficient products and practices, providing clients with a competitive edge in the market.
By partnering with Rapid Innovation, clients can leverage our expertise in these areas to achieve greater ROI, enhance operational efficiency, and drive sustainable growth. Our tailored solutions ensure that your business not only meets current demands but is also well-prepared for future challenges, including real time etl, real time stream analytics, and real time stream processing. Additionally, we offer solutions for real time data ingestion, realtime data ingestion, and kafka real time streaming, as well as batch and real time processing. Our services also include examples of real time processing, aws real time data processing, real time analytics processing, real time big data processing examples, real time data streaming python, snowflake real time data ingestion, azure real time data ingestion, and real time data processing aws.
10.4. Ethical Considerations
At Rapid Innovation, we recognize that ethical considerations in business are paramount in various fields, including research, healthcare, and technology. These principles guide our decision-making processes and ensure that our actions align with the highest moral standards. Here are some key aspects we prioritize:
- Informed Consent
- We ensure that participants in research or clinical trials are fully informed about the nature of the study, potential risks, and benefits.
- Consent is obtained voluntarily, without any form of coercion.
- Participants retain the right to withdraw at any time without penalty, reinforcing our commitment to ethical practices.
- Confidentiality and Privacy
- Protecting the privacy of individuals is a cornerstone of our operations, especially when handling sensitive data.
- We implement robust measures to safeguard personal information, ensuring that our clients can trust us with their data.
- Anonymization techniques are employed to maintain confidentiality and protect individual identities.
- Integrity and Honesty
- We uphold transparency in reporting results and findings, fostering trust and credibility with our clients.
- Misrepresentation of data or plagiarism is strictly prohibited, as we believe in maintaining the highest ethical standards.
- We disclose any conflicts of interest that may influence our work, ensuring that our clients are fully informed.
- Fairness and Justice
- Our ethical considerations demand equitable treatment of all participants in our projects.
- We are committed to protecting vulnerable populations from exploitation and ensuring that access to benefits and burdens of research is distributed fairly.
- Responsibility to Society
- We understand our duty to consider the broader impact of our work on society.
- The ethical implications of technology, such as AI and blockchain, are carefully evaluated in our projects.
- Engaging with communities and stakeholders allows us to address societal concerns effectively.
- Environmental Ethics
- We prioritize consideration of environmental impact in our operations and projects.
- Sustainable practices are at the forefront of our initiatives, minimizing harm to the planet.
- We assess our ecological footprint and strive for responsible resource use in all our endeavors.
- Cultural Sensitivity
- Our ethical considerations account for cultural differences and values, enhancing our global reach.
- Engaging with diverse communities enriches our understanding and respect for various cultural norms.
- We remain aware of cultural practices that may influence our work, ensuring inclusivity.
- Regulatory Compliance
- Adhering to laws and regulations is a fundamental ethical obligation we uphold.
- We stay informed about relevant guidelines and standards, ensuring compliance that protects the rights of individuals.
- Our commitment to accountability is reflected in our adherence to regulatory frameworks.
- Continuous Ethical Reflection
- We believe that ethical considerations are not static; they require ongoing reflection and adaptation.
- Engaging in discussions about ethical dilemmas fosters a culture of integrity within our organization.
- We integrate training and education on ethics into our professional development programs, ensuring our team remains informed.
- Global Perspectives
- We acknowledge that ethical considerations can vary across different cultures and regions.
- Our global collaboration necessitates an understanding of diverse ethical frameworks, allowing us to operate effectively in various markets.
- We strive for a balance between universal ethical principles and local customs, ensuring respect and understanding in all our interactions.
Incorporating these ethical considerations into our practices and policies not only enhances trust and accountability but also reinforces our commitment to social responsibility across various sectors, including ethical and legal considerations in business. Partnering with Rapid Innovation means aligning with a firm that values ethics as much as innovation, ensuring that your projects are executed with integrity and respect for all stakeholders involved.










