





1. Introduction to Microservices with Rust
Microservices architecture is a modern approach to software development that emphasizes the creation of small, independent services that communicate over a network. This architecture allows for greater flexibility, scalability, and maintainability in software applications. Rust, a systems programming language known for its performance and safety, is increasingly being adopted for building rust microservices.
1.1. What are Microservices?
Microservices are a software architectural style that structures an application as a collection of loosely coupled services. Each service is designed to perform a specific business function and can be developed, deployed, and scaled independently. Key characteristics of microservices include:
- Independence: Each microservice can be developed and deployed independently, allowing teams to work on different services simultaneously.
- Scalability: Services can be scaled individually based on demand, optimizing resource usage.
- Technology Agnostic: Different services can be built using different programming languages or technologies, allowing teams to choose the best tools for their needs.
- Resilience: If one service fails, it does not necessarily bring down the entire application, enhancing overall system reliability.
- Continuous Delivery: Microservices facilitate continuous integration and delivery, enabling faster release cycles.
Microservices are often used in cloud-native applications, where they can take full advantage of containerization and orchestration technologies like Docker and Kubernetes. This architecture is particularly beneficial for large, complex applications that require frequent updates and scalability.
1.2. Why Rust for Microservices?
Rust is gaining traction in the microservices landscape due to its unique features that align well with the needs of modern software development. Here are some reasons why Rust is a suitable choice for building microservices:
- Performance: Rust is designed for high performance, comparable to C and C++. This makes it ideal for microservices that require efficient resource management and low latency.
- Memory Safety: Rust's ownership model ensures memory safety without a garbage collector, reducing the risk of memory leaks and segmentation faults. This is crucial for building reliable microservices.
- Concurrency: Rust provides powerful concurrency features, allowing developers to write safe concurrent code. This is essential for microservices that need to handle multiple requests simultaneously.
- Ecosystem: The Rust ecosystem is growing, with libraries and frameworks like Actix and Rocket that simplify the development of web services. These frameworks provide tools for routing, middleware, and asynchronous programming, making it easier to create a rust microservice framework.
- Community Support: Rust has a vibrant community that contributes to its development and provides resources for learning and troubleshooting.
To get started with building microservices in Rust, follow these steps:
- Install Rust using rustup:
language="language-bash"curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
- Create a new Rust project:
language="language-bash"cargo new my_microservice-a1b2c3-cd my_microservice
- Add dependencies in
Cargo.tomlfor a web framework (e.g., Actix):
language="language-toml"[dependencies]-a1b2c3-actix-web = "4.0"
- Write a simple HTTP server in
src/main.rs:
language="language-rust"use actix_web::{web, App, HttpServer, Responder};-a1b2c3--a1b2c3-async fn greet() -> impl Responder {-a1b2c3- "Hello, Microservices with Rust!"-a1b2c3-}-a1b2c3--a1b2c3-#[actix_web::main]-a1b2c3-async fn main() -> std::io::Result<()> {-a1b2c3- HttpServer::new(|| {-a1b2c3- App::new().route("/", web::get().to(greet))-a1b2c3- })-a1b2c3- .bind("127.0.0.1:8080")?-a1b2c3- .run()-a1b2c3- .await-a1b2c3-}
- Run the server:
language="language-bash"cargo run
By following these steps, you can create a basic microservice using Rust, leveraging its performance and safety features to build robust applications. Writing microservices in Rust can lead to more efficient and reliable systems.
At Rapid Innovation, we understand the complexities of adopting microservices architecture and the importance of choosing the right technology stack. Our expertise in rust development services can help you achieve greater ROI by enhancing your application's performance, scalability, and reliability. By partnering with us, you can expect tailored solutions that align with your business goals, reduced time-to-market, and improved operational efficiency. Let us guide you through your digital transformation journey, ensuring that you harness the full potential of microservices with Rust for your organization.
1.3. Key Benefits and Challenges
At Rapid Innovation, we understand the importance of selecting the right technology stack for your projects. Rust, a systems programming language, offers several compelling benefits that can significantly enhance your development process and overall project outcomes.
- Memory Safety: Rust's ownership model ensures memory safety without needing a garbage collector. This reduces the chances of common bugs like null pointer dereferencing and buffer overflows, leading to more reliable applications.
- Performance: Rust is designed for high performance, comparable to C and C++. It compiles to native code, allowing for efficient execution and low-level control over system resources. This means your applications can run faster and more efficiently, ultimately leading to a greater return on investment (ROI).
- Concurrency: Rust's type system and ownership model make it easier to write concurrent programs. It prevents data races at compile time, which is a significant advantage in multi-threaded applications. This capability allows your projects to scale effectively, handling more tasks simultaneously without compromising performance.
- Tooling and Ecosystem: Rust has a robust package manager (Cargo) and a growing ecosystem of libraries (crates) that simplify development and enhance productivity. This means faster development cycles and the ability to leverage existing solutions, reducing time-to-market for your products. The advantages of the Rust programming benefits are evident in its strong community support and documentation.
Challenges of using Rust:
- Learning Curve: Rust's unique concepts, such as ownership, borrowing, and lifetimes, can be challenging for newcomers. Developers familiar with languages like Python or Java may find it difficult to adapt. However, our team at Rapid Innovation is equipped to provide training and support to help your developers transition smoothly.
- Compilation Speed: While Rust's compile-time checks improve safety, they can lead to longer compilation times compared to other languages. This can slow down the development process, especially in large projects. We can assist in optimizing your build processes to mitigate these delays.
- Limited Libraries: Although the Rust ecosystem is growing, it may not have as many libraries or frameworks as more established languages. This can limit options for certain tasks or require more effort to implement features. Our expertise allows us to identify and create custom solutions tailored to your specific needs.
2. Setting Up the Development Environment
To start developing in Rust, you need to set up your development environment. This includes installing Rust and its package manager, Cargo, which simplifies dependency management and project building.
- Check System Requirements: Ensure your system meets the requirements for installing Rust. Rust supports Windows, macOS, and Linux.
- Install Rust: The recommended way to install Rust is through
rustup, a toolchain installer for Rust. It manages Rust versions and associated tools. - Set Up Your IDE: Choose an Integrated Development Environment (IDE) or text editor that supports Rust. Popular options include Visual Studio Code, IntelliJ Rust, and Eclipse with Rust plugins.
- Configure Your Environment: After installation, configure your environment variables if necessary, and ensure that the Rust toolchain is accessible from your command line.
2.1. Installing Rust and Cargo
To install Rust and Cargo, follow these steps:
- Open Terminal or Command Prompt: Depending on your operating system, open the terminal (Linux/macOS) or command prompt (Windows).
- Run the Installation Command: Use the following command to download and install Rust and Cargo:
language="language-bash"curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
- Follow the On-Screen Instructions: The installer will guide you through the installation process. You may need to adjust your system's PATH variable to include Cargo's bin directory.
- Verify the Installation: After installation, verify that Rust and Cargo are installed correctly by running:
language="language-bash"rustc --version-a1b2c3-cargo --version
- Update Rust: To keep your Rust installation up to date, you can run:
language="language-bash"rustup update
By following these steps, you will have a fully functional Rust development environment ready for building applications. At Rapid Innovation, we are committed to helping you leverage the power of Rust to achieve your business goals efficiently and effectively. Partner with us to unlock the full potential of your projects and maximize your ROI, taking full advantage of the rust language advantages.
2.2. Essential Tools and Libraries
When developing microservices, having the right tools and libraries is crucial for efficiency and effectiveness. At Rapid Innovation, we understand that the right technology stack can significantly impact your project's success. Here are some essential tools and libraries that can enhance your microservices development:
- Containerization Tools:
- Docker: Simplifies the deployment of applications by packaging them into containers, ensuring consistency across different environments. It is also essential for docker microservices local development.
- Kubernetes: Manages containerized applications across a cluster of machines, providing scalability and high availability.
- API Management:
- Swagger/OpenAPI: Helps in designing, documenting, and consuming RESTful APIs, making it easier for teams to collaborate and integrate.
- Postman: A popular tool for testing APIs and automating API workflows, ensuring that your services communicate effectively.
- Service Discovery:
- Consul: Provides service discovery and configuration management, allowing services to find and communicate with each other seamlessly.
- Eureka: A REST-based service that helps in locating services for the purpose of load balancing and failover, enhancing system reliability.
- Monitoring and Logging:
- Prometheus: An open-source monitoring system with a dimensional data model, enabling you to track performance metrics effectively.
- ELK Stack (Elasticsearch, Logstash, Kibana): A powerful set of tools for searching, analyzing, and visualizing log data in real time, helping you identify issues quickly.
- Messaging Systems:
- RabbitMQ: A message broker that facilitates communication between services, ensuring reliable message delivery.
- Apache Kafka: A distributed streaming platform that can handle real-time data feeds, making it ideal for high-throughput applications.
- Frameworks:
- Spring Boot: A framework that simplifies the development of Java-based microservices, allowing for rapid application development. It is particularly useful for devops tools and aws for java microservice developers.
- Micronaut: A modern JVM-based framework designed for building modular, easily testable microservices, promoting best practices in software design.
- Development Environment:
- Local development environment for microservices is essential for testing and iterating on your services before deployment.
- Microservices development tools are crucial for streamlining the development process and enhancing productivity.
2.3. IDE Setup and Recommended Extensions
Setting up your Integrated Development Environment (IDE) properly can significantly improve your productivity. At Rapid Innovation, we guide our clients in optimizing their development environments. Here’s how to set up your IDE and some recommended extensions:
- Choose Your IDE:
- Popular choices include Visual Studio Code, IntelliJ IDEA, and Eclipse. Each has its strengths depending on the programming language and framework you are using.
- Install Recommended Extensions:
- For Visual Studio Code:
- Docker: Provides support for Docker container management.
- REST Client: Allows you to send HTTP requests and view responses directly in the IDE.
- Prettier: A code formatter that helps maintain consistent code style.
- For IntelliJ IDEA:
- Spring Assistant: Enhances support for Spring Boot applications.
- Lombok: Reduces boilerplate code in Java applications.
- JRebel: Allows for instant reloading of code changes without restarting the application.
- For Visual Studio Code:
- Configure Your IDE:
- Set up version control integration (e.g., Git).
- Customize code formatting and linting rules to match your team's standards.
- Enable debugging tools to facilitate easier troubleshooting.
3. Designing Microservices Architecture
Designing a microservices architecture requires careful planning and consideration of various factors. At Rapid Innovation, we leverage our expertise to help clients create scalable and efficient architectures. Here are some key aspects to consider:
- Decompose the Application:
- Identify business capabilities and break them down into smaller, manageable services.
- Each microservice should focus on a single responsibility, promoting clarity and maintainability.
- Define Communication Protocols:
- Choose between synchronous (e.g., REST, gRPC) and asynchronous (e.g., message queues) communication based on the use case.
- Ensure that services can communicate effectively while maintaining loose coupling, which enhances flexibility.
- Data Management:
- Decide on a data management strategy, whether to use a shared database or a database per service.
- Consider eventual consistency and how to handle data synchronization across services to maintain data integrity.
- Security:
- Implement security measures such as API gateways, authentication, and authorization.
- Use tools like OAuth2 and JWT for secure communication between services, safeguarding sensitive information.
- Deployment Strategy:
- Choose a deployment strategy that suits your needs, such as blue-green deployments or canary releases.
- Use CI/CD pipelines to automate the deployment process, reducing time to market and minimizing errors.
- Monitoring and Resilience:
- Implement monitoring tools to track the health and performance of microservices.
- Use patterns like circuit breakers and retries to enhance resilience, ensuring your system remains robust under load.
By following these guidelines and utilizing the right tools, including devops tools and aws for java microservice developers free download, you can effectively design and implement a robust microservices architecture. Partnering with Rapid Innovation means you gain access to our expertise, ensuring that your projects are executed efficiently and effectively, ultimately leading to greater ROI and success in achieving your business goals.
3.1. Domain-Driven Design (DDD) Principles
Domain-Driven Design (DDD) is a software development approach that emphasizes collaboration between technical and domain experts to create a shared understanding of the domain. The key principles of DDD include:
- Focus on the Core Domain: Identify the core domain and prioritize it in the development process. This ensures that the most critical aspects of the business are addressed first, leading to more effective solutions that drive greater ROI.
- Ubiquitous Language: Establish a common language that both developers and domain experts use to communicate. This reduces misunderstandings and aligns the team on the domain model, fostering a collaborative environment that enhances productivity.
- Bounded Contexts: Define clear boundaries around different models within the domain. Each bounded context has its own model and is responsible for its own data and behavior, allowing for more manageable and scalable systems.
- Entities and Value Objects: Distinguish between entities (which have a unique identity) and value objects (which are defined by their attributes). This helps in modeling the domain accurately, ensuring that the software aligns closely with business needs.
- Aggregates: Group related entities and value objects into aggregates, which are treated as a single unit for data changes. This enforces consistency within the aggregate, reducing the risk of errors and improving system reliability.
- Domain Events: Use domain events to capture significant changes in the state of the domain. This allows for better communication between different parts of the system, facilitating a more responsive and adaptive architecture.
3.2. Service Boundaries and Responsibilities
Defining service boundaries and responsibilities is crucial for creating a scalable and maintainable architecture. Key considerations include:
- Single Responsibility Principle: Each service should have a single responsibility, focusing on a specific business capability. This makes services easier to understand and maintain, ultimately leading to faster development cycles and reduced costs.
- Loose Coupling: Services should be loosely coupled, meaning changes in one service should not heavily impact others. This can be achieved through well-defined interfaces and communication protocols, enhancing system resilience and flexibility.
- High Cohesion: Services should be cohesive, meaning that the functionalities within a service are closely related. This enhances the service's usability and reduces complexity, allowing for more efficient development and maintenance.
- API Design: Design clear and consistent APIs for services. This includes defining endpoints, request/response formats, and error handling strategies, which can significantly improve integration and user experience.
- Inter-Service Communication: Choose appropriate communication methods (e.g., REST, gRPC, message queues) based on the use case. Asynchronous communication can improve performance and resilience, ensuring that the system can handle varying loads effectively.
- Service Discovery: Implement service discovery mechanisms to allow services to find and communicate with each other dynamically. This is especially important in microservices architectures, enabling greater scalability and adaptability.
3.3. Data Management and Persistence Strategies
Effective data management and persistence strategies are essential for maintaining data integrity and performance. Consider the following strategies:
- Database Selection: Choose the right database technology based on the use case. Options include relational databases (e.g., PostgreSQL), NoSQL databases (e.g., MongoDB), and in-memory databases (e.g., Redis). The right choice can lead to significant performance improvements and cost savings.
- Data Modeling: Create a data model that reflects the domain model. This includes defining tables, relationships, and constraints in a relational database or collections and documents in a NoSQL database, ensuring that the data structure supports business operations effectively.
- Data Access Patterns: Implement data access patterns such as Repository and Unit of Work to abstract data access logic and promote separation of concerns. This can lead to cleaner code and easier maintenance, ultimately reducing development time.
- Caching Strategies: Use caching to improve performance and reduce database load. Consider in-memory caching solutions like Redis or Memcached, which can significantly enhance application responsiveness and user satisfaction.
- Data Migration: Plan for data migration strategies when evolving the data model. This includes versioning and backward compatibility to ensure smooth transitions, minimizing disruptions to business operations.
- Backup and Recovery: Establish backup and recovery procedures to protect data integrity. Regular backups and a well-defined recovery plan are essential for disaster recovery, safeguarding your business against data loss.
By adhering to these domain-driven design principles and strategies, teams can create robust, scalable, and maintainable systems that effectively address business needs, ultimately leading to greater ROI and enhanced operational efficiency. Partnering with Rapid Innovation ensures that you leverage these best practices to achieve your goals efficiently and effectively.
4. Building Core Microservices Components
4.1. Creating a Basic Microservice Structure
Creating a basic microservice structure is essential for developing scalable and maintainable applications. A microservices architecture allows you to break down your application into smaller, independent services that can be developed, deployed, and scaled independently.
- Define the Service Boundaries: Identify the specific functionality that each microservice will provide. This helps in maintaining a clear separation of concerns.
- Choose a Technology Stack: Select the programming language and framework that best suits your needs. Common choices include Node.js, Java with Spring Boot, and Python with Flask or Django.
- Set Up a Project Structure: Organize your project files in a way that promotes clarity and ease of navigation. A typical structure might look like this:
language="language-plaintext"/my-microservice-a1b2c3-/src-a1b2c3-/controllers-a1b2c3-/models-a1b2c3-/routes-a1b2c3-/services-a1b2c3-/tests-a1b2c3-/config-a1b2c3-package.json
- Implement Configuration Management: Use environment variables or configuration files to manage settings like database connections, API keys, and other sensitive information.
- Establish Communication Protocols: Decide how your microservices will communicate with each other. Common methods include HTTP REST, gRPC, or message brokers like RabbitMQ or Kafka.
- Set Up a Database: Choose a database that fits your service's needs. You can opt for SQL databases like PostgreSQL or NoSQL databases like MongoDB, depending on your data requirements.
- Implement Logging and Monitoring: Integrate logging frameworks and monitoring tools to track the performance and health of your microservices. Tools like ELK Stack or Prometheus can be beneficial.
4.2. Implementing RESTful APIs with Actix-web
Actix-web is a powerful, pragmatic, and extremely fast web framework for Rust. It is well-suited for building RESTful APIs due to its performance and ease of use.
- Set Up Your Rust Environment: Ensure you have Rust installed on your machine. You can install it using
rustup:
language="language-plaintext"curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
- Create a New Actix-web Project: Use Cargo, Rust's package manager, to create a new project:
language="language-plaintext"cargo new my_actix_service-a1b2c3-cd my_actix_service
- Add Dependencies: Update your
Cargo.tomlfile to include Actix-web:
language="language-toml"[dependencies]-a1b2c3-actix-web = "4.0"
- Implement Basic API Endpoints: Create a simple RESTful API by defining routes and handlers. Here’s a basic example:
language="language-rust"use actix_web::{web, App, HttpServer, Responder};-a1b2c3--a1b2c3-async fn greet() -> impl Responder {-a1b2c3- "Hello, World!"-a1b2c3-}-a1b2c3--a1b2c3-#[actix_web::main]-a1b2c3-async fn main() -> std::io::Result<()> {-a1b2c3- HttpServer::new(|| {-a1b2c3- App::new()-a1b2c3- .route("/", web::get().to(greet))-a1b2c3- })-a1b2c3- .bind("127.0.0.1:8080")?-a1b2c3- .run()-a1b2c3- .await-a1b2c3-}
- Run Your Service: Start your Actix-web service by running:
language="language-plaintext"cargo run
- Test Your API: Use tools like Postman or curl to test your API endpoints. For example:
language="language-plaintext"curl http://127.0.0.1:8080/
- Implement Error Handling: Ensure your API can handle errors gracefully by using Actix's built-in error handling features.
- Add Middleware: Consider adding middleware for logging, authentication, or CORS to enhance your API's functionality.
By following these steps, you can create a robust microservice structure and implement RESTful APIs using Actix-web, setting a solid foundation for your microservices architecture. At Rapid Innovation, we specialize in guiding clients through this process, ensuring that your microservices are not only well-structured but also optimized for performance and scalability. We can help you understand microservices design patterns and provide examples of microservices that fit your needs. Partnering with us means you can expect greater ROI through efficient development practices, reduced time-to-market, and enhanced application reliability. Let us help you achieve your goals effectively and efficiently.
4.3. Handling Configuration and Environment Variables
At Rapid Innovation, we understand that managing configuration and environment variables is crucial for the smooth operation of applications, especially in microservices architectures. Proper handling ensures that applications can adapt to different environments (development, testing, production) without code changes, ultimately leading to greater efficiency and effectiveness in achieving your business goals.
Environment Variables:
- We recommend using environment variables to store sensitive information like API keys, database credentials, and other configuration settings.
- This approach keeps sensitive data out of the codebase, enhancing security and reducing the risk of data breaches.
Configuration Files:
- Utilizing configuration files (e.g., YAML, JSON) for non-sensitive settings that may change between environments is a best practice we advocate.
- These files can be version-controlled and easily modified, allowing for seamless updates and management.
Configuration Management Tools:
- Our expertise includes leveraging tools like Consul, etcd, or Spring Cloud Config to centralize configuration management for microservices.
- These tools allow for dynamic configuration updates without restarting services, ensuring minimal downtime and improved operational efficiency.
Best Practices:
- We emphasize the importance of using a consistent naming convention for environment variables.
- Documenting the expected environment variables for each service is essential for clarity and ease of use.
- Validating configuration settings at startup helps catch errors early, reducing the risk of operational disruptions.
5. Inter-Service Communication
In a microservices architecture, effective inter-service communication is vital for functionality. Our team at Rapid Innovation can guide you in choosing the right communication method—synchronous or asynchronous—based on your specific use case.
- Synchronous Communication:
- Services can call each other directly and wait for a response, utilizing common protocols such as HTTP/REST and gRPC.
- Asynchronous Communication:
- Alternatively, services can communicate through message brokers (e.g., RabbitMQ, Kafka), which decouples services and allows for better scalability and fault tolerance.
- Choosing the Right Method:
- We help you consider the use case, latency requirements, and the need for real-time responses when selecting between synchronous and asynchronous communication.
5.1. Synchronous Communication with gRPC
gRPC is a high-performance, open-source RPC framework that uses HTTP/2 for transport and Protocol Buffers as the interface description language. It is particularly well-suited for microservices due to its efficiency and support for multiple programming languages.
Advantages of gRPC:
- Performance: gRPC is faster than traditional REST due to its binary serialization and HTTP/2 features like multiplexing, which can significantly enhance your application's responsiveness.
- Strongly Typed Contracts: Protocol Buffers enforce a strict contract between services, reducing errors and improving reliability.
- Streaming Support: gRPC supports bi-directional streaming, allowing for real-time data exchange, which can be a game-changer for applications requiring instant updates.
Setting Up gRPC:
- Our team can assist you in defining your service and messages in a
.protofile. - We guide you through generating server and client code using the Protocol Buffers compiler.
- Implementing the server logic and starting the gRPC server is streamlined with our expertise.
- Creating a client to call the gRPC service is made easy with our support.
Example Steps:
- Create a
.protofile:
language="language-protobuf"syntax = "proto3";-a1b2c3--a1b2c3-service Greeter {-a1b2c3- rpc SayHello (HelloRequest) returns (HelloReply);-a1b2c3-}-a1b2c3--a1b2c3-message HelloRequest {-a1b2c3- string name = 1;-a1b2c3-}-a1b2c3--a1b2c3-message HelloReply {-a1b2c3- string message = 1;-a1b2c3-}
- Generate code:
language="language-bash"protoc --go_out=plugins=grpc:. greeter.proto
- Implement the server:
language="language-go"type server struct{}-a1b2c3--a1b2c3-func (s *server) SayHello(ctx context.Context, req *HelloRequest) (*HelloReply, error) {-a1b2c3- return &HelloReply{Message: "Hello " + req.Name}, nil-a1b2c3-}
- Start the server:
language="language-go"lis, _ := net.Listen("tcp", ":50051")-a1b2c3-grpcServer := grpc.NewServer()-a1b2c3-RegisterGreeterServer(grpcServer, &server{})-a1b2c3-grpcServer.Serve(lis)
By following these guidelines and leveraging our expertise in microservices configuration management, you can effectively manage configuration and facilitate inter-service communication in a microservices architecture, ultimately achieving greater ROI and operational excellence. Partnering with Rapid Innovation means you can expect enhanced security, improved efficiency, and a robust framework for your development needs.
5.2. Asynchronous Messaging with Apache Kafka
Asynchronous messaging is a crucial aspect of microservices architecture, allowing services to communicate without being tightly coupled. Asynchronous messaging with Apache Kafka is a popular distributed event streaming platform that facilitates this communication.
- Decoupling Services: Kafka allows microservices to operate independently, significantly reducing the risk of cascading failures that can disrupt your operations.
- High Throughput: Kafka can handle thousands of messages per second, making it suitable for high-volume applications, which is essential for businesses looking to scale efficiently.
- Durability: Messages are stored on disk, ensuring that they are not lost even if a service goes down, thus enhancing the reliability of your systems.
- Scalability: Kafka can be scaled horizontally by adding more brokers to the cluster, allowing your infrastructure to grow alongside your business needs.
To implement asynchronous messaging with Apache Kafka, follow these steps:
- Set up a Kafka cluster by installing Kafka and Zookeeper.
- Create a topic for your microservices to publish and subscribe to messages.
- Use Kafka producers to send messages to the topic.
- Implement Kafka consumers in your microservices to process incoming messages.
5.3. Implementing Circuit Breakers and Retries
In a microservices architecture, failures can occur due to various reasons, such as network issues or service downtime. Implementing circuit breakers and retries helps to manage these failures gracefully, ensuring that your services remain resilient.
- Circuit Breaker Pattern: This pattern prevents a service from making calls to a failing service, allowing it to recover. It has three states:
- Closed: The circuit is closed, and requests are allowed.
- Open: The circuit is open, and requests are blocked.
- Half-Open: The circuit allows a limited number of requests to test if the service has recovered.
- Retry Mechanism: This involves retrying a failed request a certain number of times before giving up. It can be combined with exponential backoff to avoid overwhelming the service, thus improving the overall user experience.
To implement circuit breakers and retries, follow these steps:
- Choose a library or framework that supports circuit breakers (e.g., Hystrix, Resilience4j).
- Configure the circuit breaker settings, such as failure thresholds and timeout durations.
- Wrap service calls with the circuit breaker logic.
- Implement a retry mechanism with a defined number of attempts and backoff strategy.
6. Data Management in Microservices
Data management in microservices is essential for maintaining data consistency and integrity across distributed services. Each microservice typically manages its own database, leading to challenges in data synchronization and consistency.
- Database per Service: Each microservice should have its own database to ensure loose coupling. This allows teams to choose the best database technology for their needs, optimizing performance and resource utilization.
- Event Sourcing: This pattern involves storing the state of a service as a sequence of events, allowing for better traceability and recovery, which is vital for compliance and auditing.
- CQRS (Command Query Responsibility Segregation): This pattern separates read and write operations, optimizing performance and scalability, enabling your applications to handle increased loads effectively.
To manage data effectively in microservices, consider the following:
- Define clear data ownership for each microservice.
- Use API gateways to manage data access and enforce security.
- Implement data replication strategies if necessary to ensure data availability.
- Monitor data consistency and integrity across services using distributed tracing tools.
By following these practices, you can ensure effective data management in a microservices architecture, leading to improved performance and reliability. Partnering with Rapid Innovation allows you to leverage our expertise in these areas, ensuring that your systems are robust, scalable, and capable of delivering greater ROI. Our tailored solutions will help you achieve your business goals efficiently and effectively, positioning you for success in a competitive landscape.
6.1. Working with Databases (SQL and NoSQL)
Databases are essential for storing and managing data in applications. They can be broadly categorized into SQL (relational) and NoSQL (non-relational) databases.
SQL Databases:
- Use structured query language (SQL) for defining and manipulating data.
- Data is organized in tables with predefined schemas.
- Examples include MySQL, PostgreSQL, and SQLite.
- Ideal for applications requiring complex queries and transactions.
- Tools like database activity monitoring and database analytics software can enhance the management of SQL databases.
NoSQL Databases:
- Designed for unstructured or semi-structured data.
- Data can be stored in various formats such as key-value pairs, documents, or graphs.
- Examples include MongoDB, Cassandra, and Redis.
- Suitable for applications needing scalability and flexibility.
- Cloud based database solutions are increasingly popular for NoSQL implementations.
Key Differences:
- SQL databases enforce ACID properties (Atomicity, Consistency, Isolation, Durability), while NoSQL databases often prioritize availability and partition tolerance (CAP theorem).
- SQL databases are schema-based, whereas NoSQL databases are schema-less, allowing for more dynamic data structures.
Choosing the Right Database:
- Consider the nature of your data and application requirements.
- For structured data with complex relationships, SQL is preferable.
- For large volumes of unstructured data or rapid scaling, NoSQL is often the better choice.
- Solutions like cloud data migration services can assist in transitioning between different database types.
6.2. Implementing CQRS Pattern
CQRS (Command Query Responsibility Segregation) is a design pattern that separates the read and write operations of an application. This separation allows for more scalable and maintainable systems.
Benefits of CQRS:
- Improved performance: Read and write operations can be optimized independently.
- Scalability: Each side can be scaled according to its specific load.
- Flexibility: Different data models can be used for reading and writing.
Steps to Implement CQRS:
- Define the command and query models:
- Commands: Actions that change the state of the application (e.g., create, update, delete).
- Queries: Actions that retrieve data without modifying it.
- Create separate data stores:
- Use different databases or data models for commands and queries.
- Implement event handling:
- Use events to synchronize the command and query models.
- Use a messaging system:
- Implement a message broker (e.g., RabbitMQ, Kafka) to handle communication between command and query services.
Example Code Snippet:
language="language-rust"// Command model-a1b2c3-struct CreateUserCommand {-a1b2c3- username: String,-a1b2c3- email: String,-a1b2c3-}-a1b2c3--a1b2c3-// Query model-a1b2c3-struct UserQuery {-a1b2c3- user_id: String,-a1b2c3-}-a1b2c3--a1b2c3-// Event handler-a1b2c3-fn handle_user_created(event: UserCreatedEvent) {-a1b2c3- // Update read model-a1b2c3-}
6.3. Event Sourcing in Rust Microservices
Event sourcing is a pattern where state changes are stored as a sequence of events. This approach allows for reconstructing the current state of an application by replaying these events.
Benefits of Event Sourcing:
- Auditability: Every change is recorded, providing a complete history of state changes.
- Flexibility: The application can evolve by changing how events are processed without losing historical data.
- Simplified debugging: Replaying events can help identify issues in the application.
Implementing Event Sourcing in Rust:
- Define event types:
- Create structs for each event that represents a state change.
- Store events:
- Use a database or event store to persist events, which can include solutions like cloud based dbms.
- Rebuild state:
- Implement a function to replay events and reconstruct the current state.
Example Code Snippet:
language="language-rust"// Event struct-a1b2c3-struct UserCreatedEvent {-a1b2c3- user_id: String,-a1b2c3- username: String,-a1b2c3-}-a1b2c3--a1b2c3-// Function to apply events-a1b2c3-fn apply_event(events: Vec<UserCreatedEvent>) -> UserState {-a1b2c3- let mut state = UserState::default();-a1b2c3- for event in events {-a1b2c3- state.username = event.username;-a1b2c3- }-a1b2c3- state-a1b2c3-}
By leveraging these patterns and technologies, including tools like oracle corporation erp and sap hana, developers can create robust, scalable, and maintainable applications that effectively manage data and state. At Rapid Innovation, we specialize in guiding our clients through these complex decisions, ensuring that they select the right database solutions and architectural patterns to maximize their return on investment. Partnering with us means you can expect enhanced efficiency, reduced operational costs, and a strategic approach to technology that aligns with your business goals.
7. Authentication and Authorization
At Rapid Innovation, we understand that authentication authorization and accounting are critical components of any secure application. They ensure that users are who they claim to be and that they have the appropriate permissions to access resources, ultimately safeguarding your business's sensitive data.
7.1. Implementing JWT-based Authentication
JSON Web Tokens (JWT) are a popular method for implementing authentication in web applications. They allow for stateless authentication, meaning that the server does not need to store session information, which can lead to improved performance and scalability.
Key Features of JWT:
- Compact: JWTs are small in size, making them easy to transmit via URLs, POST parameters, or HTTP headers.
- Self-contained: They contain all the necessary information about the user, reducing the need for additional database queries.
- Secure: JWTs can be signed and optionally encrypted, ensuring data integrity and confidentiality.
Steps to Implement JWT-based Authentication:
- User logs in with credentials (username and password).
- Server verifies credentials against the database.
- Upon successful verification, the server generates a JWT containing user information and expiration time.
- The JWT is sent back to the client, typically in the response body or as an HTTP-only cookie.
- The client stores the JWT (local storage or cookie) and includes it in the Authorization header for subsequent requests.
- The server verifies the JWT on each request, checking its signature and expiration.
Sample Code for JWT Generation:
language="language-javascript"const jwt = require('jsonwebtoken');-a1b2c3--a1b2c3-function generateToken(user) {-a1b2c3- const payload = {-a1b2c3- id: user.id,-a1b2c3- username: user.username-a1b2c3- };-a1b2c3- const secret = 'your_jwt_secret';-a1b2c3- const options = { expiresIn: '1h' };-a1b2c3--a1b2c3- return jwt.sign(payload, secret, options);-a1b2c3-}
Considerations:
- Use HTTPS to protect JWTs in transit.
- Implement token expiration and refresh mechanisms to enhance security.
- Regularly rotate signing keys to mitigate risks.
7.2. Role-Based Access Control (RBAC)
Role-Based Access Control (RBAC) is a method of regulating access to resources based on the roles assigned to users. It simplifies management by grouping permissions into roles rather than assigning them individually, which can lead to significant time savings and reduced administrative overhead.
Key Features of RBAC:
- Simplified management: Roles can be easily assigned or modified without changing individual user permissions.
- Least privilege: Users are granted only the permissions necessary for their role, reducing the risk of unauthorized access.
- Scalability: RBAC can easily scale with the organization as new roles and permissions are added.
Steps to Implement RBAC:
- Define roles within the application (e.g., Admin, User, Guest).
- Assign permissions to each role (e.g., read, write, delete).
- Map users to roles based on their responsibilities.
- Implement middleware to check user roles before granting access to specific routes or resources.
Sample Code for RBAC Middleware:
language="language-javascript"function authorize(roles = []) {-a1b2c3- return (req, res, next) => {-a1b2c3- // Check if roles is an array-a1b2c3- if (typeof roles === 'string') {-a1b2c3- roles = [roles];-a1b2c3- }-a1b2c3--a1b2c3- // Check if user has the required role-a1b2c3- if (roles.length && !roles.includes(req.user.role)) {-a1b2c3- return res.status(403).json({ message: 'Access denied' });-a1b2c3- }-a1b2c3--a1b2c3- next();-a1b2c3- };-a1b2c3-}
Considerations:
- Regularly review roles and permissions to ensure they align with current organizational needs.
- Implement logging and monitoring to track access and changes to roles.
- Combine RBAC with other security measures, such as JWT, for enhanced protection.
By implementing JWT-based authentication and RBAC, applications can achieve a robust security framework that protects sensitive data and resources while providing a seamless user experience. At Rapid Innovation, we are committed to helping you navigate these complexities, ensuring that your applications are not only secure but also efficient and scalable, ultimately leading to greater ROI for your business. Partnering with us means you can expect enhanced security, streamlined processes, and a dedicated team focused on your success.
In addition, understanding the importance of authentication and authorization, including basic HTTP authorization and basic auth authentication, is essential for maintaining secure applications. The use of authentication accounting and authorization mechanisms, such as auth headers and headers auth, further enhances the security posture of your application.
7.3. Securing Service-to-Service Communication
Securing service-to-service communication is crucial in microservices architecture to protect sensitive data and maintain the integrity of the system. Here are some strategies to achieve this:
- Use HTTPS: Encrypt data in transit using HTTPS to prevent eavesdropping and man-in-the-middle attacks. This ensures that all communication between services is secure.
- Authentication and Authorization: Implement strong authentication mechanisms, such as OAuth2 or JWT (JSON Web Tokens), to verify the identity of services. Ensure that each service has the necessary permissions to access other services.
- Service Mesh: Consider using a service mesh like Istio or Linkerd. These tools provide built-in security features, such as mutual TLS (mTLS), which encrypts traffic between services and verifies their identities.
- Network Policies: Use network policies to restrict communication between services. This limits exposure and reduces the attack surface by allowing only necessary traffic.
- API Gateway: Implement an API gateway to manage and secure service-to-service communication. The gateway can handle authentication, rate limiting, and logging, providing a single entry point for all service interactions.
- Regular Security Audits: Conduct regular security audits and vulnerability assessments to identify and mitigate potential risks in service communication.
8. Testing Strategies for Rust Microservices
Testing is essential for ensuring the reliability and performance of Rust microservices. Here are some effective testing strategies:
- Unit Testing: Focus on testing individual components or functions in isolation. Rust's built-in test framework makes it easy to write and run unit tests.
- Integration Testing: Test how different services interact with each other. This can involve setting up a test environment that mimics production to ensure that services work together as expected.
- End-to-End Testing: Validate the entire application flow from the user's perspective. This ensures that all components, including the front end and back end, function correctly together.
- Load Testing: Assess how the microservices perform under heavy load. Tools like Apache JMeter or Locust can simulate multiple users to test the system's scalability.
- Continuous Integration/Continuous Deployment (CI/CD): Integrate testing into your CI/CD pipeline to automate the testing process. This ensures that tests are run every time code is pushed, catching issues early.
8.1. Unit Testing with Rust's Built-in Test Framework
Rust provides a robust built-in test framework that simplifies unit testing. Here’s how to get started:
- Create a Test Module: Use the
#[cfg(test)]attribute to create a test module within your Rust file. - Write Test Functions: Define test functions using the
#[test]attribute. Each function should contain assertions to verify the expected behavior. - Run Tests: Use the command
cargo testto compile and run your tests. The framework will automatically find and execute all test functions. - Use Assertions: Leverage Rust's assertion macros, such as
assert_eq!andassert!, to validate conditions in your tests. - Mocking Dependencies: Use libraries like
mockitoormockallto mock external dependencies, allowing you to isolate the unit being tested. - Test Coverage: Utilize tools like
cargo tarpaulinto measure test coverage and ensure that your tests cover a significant portion of your codebase.
By implementing these strategies, you can enhance the security and reliability of your Rust microservices, ensuring they perform well in production environments.
At Rapid Innovation, we understand the importance of these practices and are committed to helping our clients achieve greater ROI through effective implementation of service-to-service communication security and testing strategies. Partnering with us means you can expect improved system integrity, reduced vulnerabilities, and a streamlined development process that ultimately leads to higher returns on your investment. Let us guide you in navigating the complexities of AI and Blockchain development, ensuring your projects are not only successful but also secure and efficient.
8.2. Integration Testing Microservices
Integration testing in microservices is crucial for ensuring that different services work together as expected. Unlike traditional monolithic applications, microservices are independently deployable units that communicate over a network. This introduces complexities that require thorough testing, including integration tests for microservices.
h4. Key Aspects of Integration Testing
- Service Interaction: Verify that services can communicate with each other correctly.
- Data Consistency: Ensure that data is consistent across services, especially when they share databases or rely on each other for data.
- Error Handling: Test how services handle failures in other services, such as timeouts or unavailability.
- Performance: Assess the performance of service interactions under load to identify bottlenecks.
h4. Steps for Integration Testing
- Define the scope of integration tests.
- Set up a test environment that mimics production.
- Use tools like Postman or JUnit for API testing, including integration testing tools for microservices.
- Create test cases that cover various scenarios, including success and failure paths.
- Execute tests and monitor service interactions.
- Analyze results and fix any identified issues.
8.3. Contract Testing with Pact
Contract testing is a method that ensures that services adhere to agreed-upon contracts, which define how they interact. Pact is a popular tool for implementing contract testing in microservices.
h4. Benefits of Contract Testing
- Decoupling: Allows teams to work independently on services without breaking changes.
- Early Detection: Catches integration issues early in the development cycle.
- Documentation: Provides clear documentation of service interactions.
h4. How Pact Works
- Consumer-Driven Contracts: The consumer of a service defines the expectations for the service's API.
- Pact Files: Pact generates files that describe the interactions between services.
- Verification: The provider service verifies that it meets the expectations defined in the Pact files.
h4. Steps to Implement Pact
- Define the API contract from the consumer's perspective.
- Use Pact to create a contract file.
- Share the contract file with the provider team.
- The provider implements the API and runs Pact tests to verify compliance.
- Continuously integrate Pact tests into the CI/CD pipeline.
9. Deployment and Orchestration
Deployment and orchestration are critical for managing microservices in production. They ensure that services are deployed efficiently and can scale as needed.
h4. Key Concepts in Deployment and Orchestration
- Containerization: Use Docker to package microservices, ensuring consistency across environments.
- Orchestration Tools: Tools like Kubernetes or Docker Swarm manage the deployment, scaling, and operation of containerized applications.
- Service Discovery: Automatically detect and connect services in a dynamic environment.
h4. Steps for Deployment and Orchestration
- Containerize each microservice using Docker.
- Define deployment configurations using YAML files for Kubernetes.
- Set up a CI/CD pipeline to automate the build and deployment process.
- Use orchestration tools to manage service scaling and health checks.
- Monitor deployed services using tools like Prometheus or Grafana.
By following these practices, teams can ensure that their microservices architecture is robust, scalable, and maintainable. At Rapid Innovation, we specialize in guiding organizations through these processes, ensuring that your microservices are not only well-tested but also efficiently deployed. Our expertise in AI and Blockchain development allows us to tailor solutions that maximize your return on investment, streamline operations, and enhance overall performance. Partnering with us means you can expect improved efficiency, reduced time-to-market, and a significant boost in your project's success rate. Let us help you achieve your goals effectively and efficiently, including integration testing microservices examples and integration testing microservices Spring Boot.
9.1. Containerization with Docker
Containerization is a method of packaging applications and their dependencies into a single unit called a container. Docker is a popular platform for creating, deploying, and managing these containers, making it a key player in docker containerization.
Benefits of using Docker:
- Isolation: Each container runs in its own environment, ensuring that applications do not interfere with each other. This isolation leads to increased stability and security for your applications.
- Portability: Containers can run on any system that supports Docker, making it easy to move applications between environments. This flexibility allows businesses to adapt quickly to changing requirements, which is a significant advantage of docker container software.
- Scalability: Docker allows for easy scaling of applications by spinning up multiple containers as needed. This capability is essential for businesses looking to grow and meet increasing demand without compromising performance, especially when using containerization and docker together.
Steps to get started with Docker:
- Install Docker on your machine.
- Create a Dockerfile to define your application environment.
- Build the Docker image using the command:
language="language-bash"docker build -t your-image-name .
- Run the container using:
language="language-bash"docker run -d -p 80:80 your-image-name
9.2. Orchestration with Kubernetes
Kubernetes is an open-source orchestration platform that automates the deployment, scaling, and management of containerized applications. It is particularly useful for managing large-scale applications across clusters of machines, especially in conjunction with containerization docker kubernetes.
Key features of Kubernetes:
- Load Balancing: Distributes traffic across multiple containers to ensure no single container is overwhelmed. This feature enhances application performance and user experience.
- Self-Healing: Automatically restarts containers that fail or replaces them if they become unresponsive. This resilience minimizes downtime and ensures continuous service availability.
- Scaling: Easily scale applications up or down based on demand. This flexibility allows businesses to optimize resource usage and reduce costs.
Steps to deploy an application using Kubernetes:
- Install Kubernetes (using Minikube for local development).
- Create a deployment configuration file (YAML format) for your application.
- Apply the configuration using:
language="language-bash"kubectl apply -f your-deployment-file.yaml
- Expose your application to the internet with:
language="language-bash"kubectl expose deployment your-deployment-name --type=LoadBalancer --port=80
9.3. Implementing CI/CD Pipelines
Continuous Integration (CI) and Continuous Deployment (CD) are practices that automate the integration and deployment of code changes. Implementing CI/CD pipelines ensures that code changes are automatically tested and deployed, leading to faster and more reliable releases.
Benefits of CI/CD:
- Faster Releases: Automates the testing and deployment process, allowing for quicker delivery of features. This speed can significantly enhance your competitive edge in the market.
- Improved Quality: Automated tests catch bugs early in the development process. This proactive approach reduces the cost and effort associated with fixing issues later in the development cycle.
- Reduced Manual Errors: Minimizes human intervention, reducing the risk of errors during deployment. This reliability fosters trust in your development processes.
Steps to implement a CI/CD pipeline:
- Choose a CI/CD tool (e.g., Jenkins, GitLab CI, CircleCI).
- Set up a version control system (e.g., Git) to manage your codebase.
- Create a configuration file for your CI/CD tool to define the pipeline stages (build, test, deploy).
- Integrate automated tests to run during the CI process.
- Deploy the application automatically to your production environment after successful tests.
By leveraging Docker for containerization, including dockerization and containerization practices, Kubernetes for orchestration, and CI/CD pipelines for automation, organizations can enhance their development processes, improve application reliability, and accelerate time-to-market. At Rapid Innovation, we specialize in these technologies, helping our clients achieve greater ROI through efficient and effective solutions tailored to their unique needs. Partnering with us means you can expect increased operational efficiency, reduced costs, and a faster path to innovation. Monitoring and observability are crucial components in maintaining the health and performance of applications. They provide insights into system behavior, enabling developers and operators to identify issues before they escalate. This includes utilizing prometheus application logs, application insights log based metrics, and application logging and metrics to gain a comprehensive understanding of application performance.
10.1. Logging with slog and log4rs
Logging is an essential practice for tracking application behavior and diagnosing issues. Two popular logging libraries in Rust are slog and log4rs.
- slog:
- A structured logging library that allows for rich, contextual logging.
- Supports various output formats, making it flexible for different use cases.
- Enables logging at different levels (e.g., debug, info, warn, error).
- Can be easily integrated with other libraries and frameworks.
- log4rs:
- A logging framework inspired by the Java log4j library.
- Provides a configuration file to manage logging settings, making it easy to adjust logging levels and outputs without changing code.
- Supports asynchronous logging, which can improve performance in high-throughput applications.
- Allows for different logging outputs (e.g., console, file, etc.) and can be configured to rotate log files.
To implement logging with slog and log4rs, follow these steps:
- Using slog:
- Add
slogandslog-termto yourCargo.toml:
- Add
language="language-toml"[dependencies]-a1b2c3-slog = "2.7"-a1b2c3-slog-term = "2.7"
- Initialize the logger in your application:
language="language-rust"use slog::{Drain, Logger};-a1b2c3-use slog_term;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let drain = slog_term::streamer().build().fuse();-a1b2c3- let logger = Logger::root(drain, o!());-a1b2c3- info!(logger, "Application started");-a1b2c3-}
- Using log4rs:
- Add
log4rsto yourCargo.toml:
- Add
language="language-toml"[dependencies]-a1b2c3-log4rs = "1.2"
- Create a configuration file (e.g.,
log4rs.yaml):
language="language-yaml"appenders:-a1b2c3- stdout:-a1b2c3- kind: console-a1b2c3- encoder:-a1b2c3- pattern: "{d} {l} - {m}{n}"-a1b2c3-root:-a1b2c3- level: info-a1b2c3- appenders:-a1b2c3- - stdout
- Initialize the logger in your application:
language="language-rust"use log4rs;-a1b2c3-use log::{info, error};-a1b2c3--a1b2c3-fn main() {-a1b2c3- log4rs::init_file("log4rs.yaml", Default::default()).unwrap();-a1b2c3- info!("Application started");-a1b2c3-}
10.2. Metrics Collection with Prometheus
Metrics collection is vital for understanding application performance and resource usage. Prometheus is a powerful tool for gathering and querying metrics.
- Key Features of Prometheus:
- Pull-based model: Prometheus scrapes metrics from configured endpoints at specified intervals.
- Multi-dimensional data model: Metrics can be labeled with key-value pairs, allowing for detailed queries.
- Powerful query language (PromQL) for aggregating and analyzing metrics.
- Built-in support for alerting based on metrics thresholds.
To set up metrics collection with Prometheus, follow these steps:
- Integrate Prometheus in your application:
- Add the
prometheuscrate to yourCargo.toml:
- Add the
language="language-toml"[dependencies]-a1b2c3-prometheus = "0.11"
- Create a metrics endpoint in your application:
language="language-rust"use prometheus::{Encoder, IntCounter, Opts, Registry, TextEncoder};-a1b2c3-use warp::Filter;-a1b2c3--a1b2c3-fn main() {-a1b2c3- let registry = Registry::new();-a1b2c3- let counter_opts = Opts::new("my_counter", "An example counter");-a1b2c3- let counter = IntCounter::with_opts(counter_opts).unwrap();-a1b2c3- registry.register(Box::new(counter.clone())).unwrap();-a1b2c3--a1b2c3- let metrics_route = warp::path("metrics")-a1b2c3- .map(move || {-a1b2c3- let mut buffer = vec![];-a1b2c3- let encoder = TextEncoder::new();-a1b2c3- encoder.encode(®istry.gather(), &mut buffer).unwrap();-a1b2c3- String::from_utf8(buffer).unwrap()-a1b2c3- });-a1b2c3--a1b2c3- warp::serve(metrics_route).run(([127, 0, 0, 1], 3030));-a1b2c3-}
- Configure Prometheus to scrape your application:
- Add a job in your
prometheus.ymlconfiguration file:
- Add a job in your
language="language-yaml"scrape_configs:-a1b2c3- - job_name: 'my_app'-a1b2c3- static_configs:-a1b2c3- - targets: ['localhost:3030']
By implementing logging with slog or log4rs and collecting metrics with Prometheus, you can significantly enhance the observability of your applications, leading to better performance and reliability. This includes leveraging prometheus application logs and application insights log based metrics to gain deeper insights into your application's behavior.
At Rapid Innovation, we understand the importance of these practices in achieving operational excellence. By partnering with us, clients can expect tailored solutions that not only improve their application's performance but also drive greater ROI through efficient resource management and proactive issue resolution. Our expertise in AI and Blockchain development ensures that we provide innovative solutions that align with your business goals, ultimately leading to enhanced productivity and profitability.
10.3. Distributed Tracing with OpenTelemetry
Distributed tracing is a critical technique for monitoring and troubleshooting microservices architectures. OpenTelemetry is an open-source observability framework that provides a standardized way to collect and export telemetry data, including traces, metrics, and logs.
- Key Features of OpenTelemetry:
- Unified framework for tracing, metrics, and logging.
- Supports multiple programming languages and platforms.
- Integrates with various backends like Jaeger, Zipkin, and Prometheus.
- Benefits of Distributed Tracing:
- Visibility: Gain insights into the flow of requests across services.
- Latency Analysis: Identify bottlenecks and optimize performance.
- Error Tracking: Quickly locate the source of errors in complex systems.
- Implementing OpenTelemetry:
- Install the OpenTelemetry SDK for your programming language.
- Initialize the tracer and set up the exporter to send data to your chosen backend, such as Jaeger or OpenTelemetry.
- Instrument your code to create spans for operations and record attributes.
Example code snippet for initializing OpenTelemetry in a Rust application:
language="language-rust"use opentelemetry::{global, sdk::trace as sdktrace, KeyValue};-a1b2c3--a1b2c3-fn init_tracer() {-a1b2c3- let tracer = sdktrace::TracerProvider::builder()-a1b2c3- .with_simple_exporter()-a1b2c3- .build()-a1b2c3- .get_tracer("example_tracer");-a1b2c3--a1b2c3- global::set_tracer_provider(tracer);-a1b2c3-}
- Best Practices:
- Use meaningful span names and attributes for better context, especially when using opentelemetry jaeger.
- Keep trace context propagation consistent across services.
- Regularly review and analyze trace data to improve system performance, leveraging tools like jaeger opentelemetry.
11. Performance Optimization
Performance optimization is essential for ensuring that microservices operate efficiently and can handle increased loads. It involves identifying and addressing performance bottlenecks in the system.
Common Performance Bottlenecks:
- Slow database queries.
- Inefficient algorithms or data structures.
- Network latency and overhead.
Optimization Techniques:
- Caching: Store frequently accessed data in memory to reduce load times.
- Load Balancing: Distribute incoming requests evenly across multiple instances.
- Asynchronous Processing: Use non-blocking calls to improve responsiveness.
Monitoring and Metrics:
- Use tools like Prometheus and Grafana to monitor performance metrics.
- Set up alerts for unusual spikes in latency or error rates.
11.1. Profiling Rust Microservices
Profiling is a crucial step in performance optimization, especially for Rust microservices, as it helps identify resource-intensive parts of the code.
Profiling Tools for Rust:
- cargo-flamegraph: Generates flame graphs to visualize CPU usage.
- perf: A powerful Linux profiling tool that can be used with Rust applications.
- valgrind: Useful for memory profiling and detecting leaks.
- Steps to Profile a Rust Microservice:
- Add profiling dependencies to your
Cargo.tomlfile. - Build your application in release mode for accurate profiling.
- Run the profiler and collect data during typical workloads.
Example command to generate a flame graph:
language="language-bash"cargo flamegraph --release
Analyzing Profiling Results:
- Look for functions with high CPU usage or long execution times.
- Identify opportunities for code refactoring or algorithm improvements.
- Test changes and re-profile to measure performance gains.
By implementing distributed tracing with OpenTelemetry and optimizing performance through profiling, developers can significantly enhance the efficiency and reliability of their Rust microservices. At Rapid Innovation, we leverage these advanced techniques, including using opentelemetry for tracing and jaeger tracing docker compose, to help our clients achieve greater ROI by ensuring their systems are not only functional but also optimized for performance and scalability. Partnering with us means you can expect improved visibility into your operations, faster troubleshooting, and ultimately, a more robust and efficient architecture that drives your business goals forward.
11.2. Optimizing Database Queries
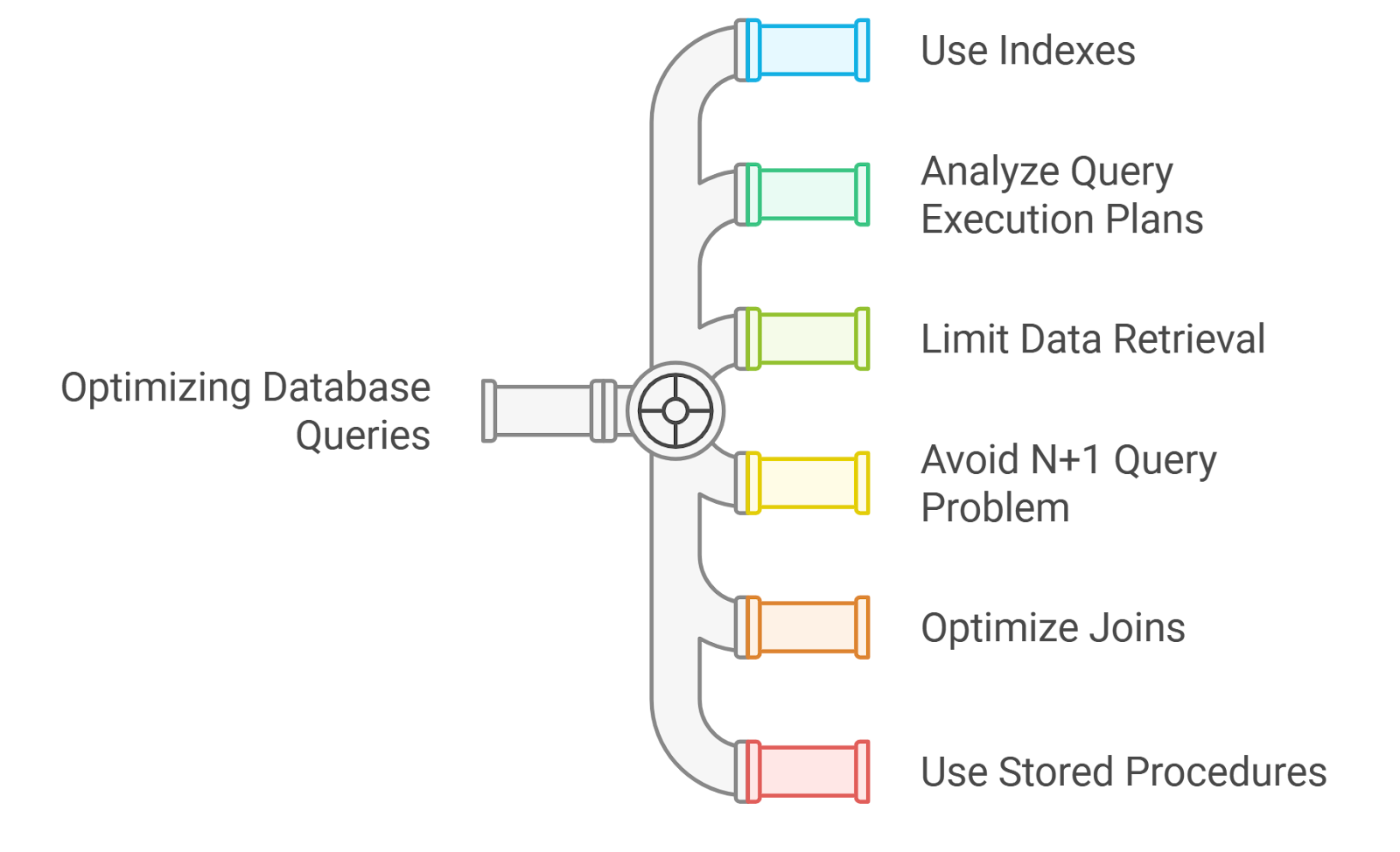
At Rapid Innovation, we understand that optimizing database queries is crucial for enhancing application performance and minimizing latency. Poorly written queries can lead to slow response times and increased load on the database server, ultimately affecting your bottom line. Here are some strategies we employ to optimize database queries for our clients:
- Use Indexes:
- We create indexes on columns that are frequently used in WHERE clauses, JOIN conditions, or ORDER BY clauses.
- Our team ensures that indexes are maintained and updated as data changes, leading to faster query execution.
- Analyze Query Execution Plans:
- We utilize tools like EXPLAIN in SQL to analyze how queries are executed.
- By identifying bottlenecks, we optimize the query structure accordingly, ensuring efficient data retrieval.
- Limit Data Retrieval:
- Our approach includes using SELECT statements to retrieve only the necessary columns instead of using SELECT *.
- We implement pagination to limit the number of rows returned in a single query, enhancing performance.
- Avoid N+1 Query Problem:
- We use JOINs to fetch related data in a single query instead of executing multiple queries, reducing database load.
- Our team considers batch processing for bulk data operations, further optimizing performance.
- Optimize Joins:
- We ensure that join conditions utilize indexed columns, which speeds up data processing.
- Whenever possible, we use INNER JOINs instead of OUTER JOINs to minimize the amount of data processed.
- Use Stored Procedures:
- We encapsulate complex queries in stored procedures to reduce the overhead of query parsing and execution, leading to faster performance.
- Regularly Monitor and Tune:
- Our team continuously monitors query performance and makes adjustments as necessary.
- We utilize database profiling tools to identify slow queries and optimize them, ensuring your applications run smoothly.
11.3. Implementing Caching Strategies
Caching is an effective way to improve application performance by storing frequently accessed data in memory, thereby reducing the need for repeated database queries. At Rapid Innovation, we implement various caching strategies tailored to our clients' needs:
- In-Memory Caching:
- We leverage caching solutions like Redis or Memcached to store data in memory for quick access.
- Our team caches results of expensive database queries or API calls, significantly improving response times.
- HTTP Caching:
- We implement HTTP caching headers (e.g., Cache-Control, ETag) to allow browsers and proxies to cache responses.
- By using CDNs (Content Delivery Networks), we cache static assets closer to users, enhancing load times.
- Application-Level Caching:
- We cache data at the application level using frameworks like Spring Cache or Django’s caching framework.
- Our approach includes storing user session data in cache to reduce database load, improving overall application performance.
- Cache Invalidation:
- We implement strategies for cache invalidation to ensure that stale data is not served.
- Our team uses time-based expiration or event-based invalidation (e.g., when data is updated) to maintain data accuracy.
- Distributed Caching:
- For microservices architectures, we consider using distributed caching solutions to share cached data across services.
- We ensure that the caching layer is resilient and can handle failures, providing a seamless experience.
- Cache Warm-Up:
- We preload cache with frequently accessed data during application startup to reduce initial latency.
- Our team uses background jobs to refresh cache data periodically, ensuring optimal performance.
12. Scaling Microservices
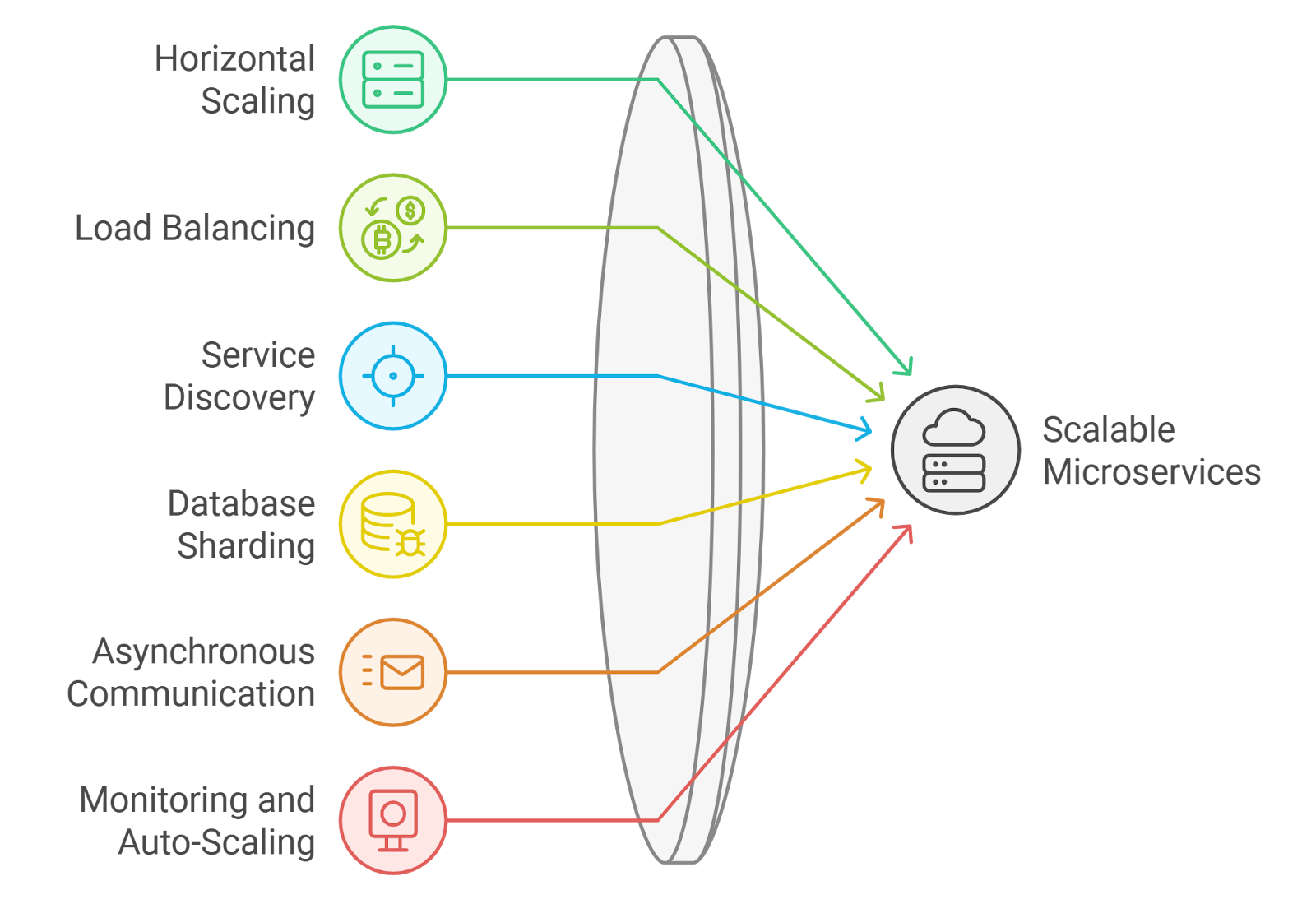
Scaling microservices is essential for handling increased load and ensuring high availability. At Rapid Innovation, we employ effective strategies for scaling microservices to meet our clients' growing demands:
- Horizontal Scaling:
- We deploy multiple instances of a microservice to distribute the load effectively.
- Our team utilizes container orchestration tools like Kubernetes to manage scaling automatically, ensuring seamless performance.
- Load Balancing:
- We implement load balancers to distribute incoming requests evenly across service instances.
- By using round-robin or least connections algorithms, we ensure effective load distribution.
- Service Discovery:
- We utilize service discovery tools (e.g., Consul, Eureka) to dynamically locate service instances.
- Our approach ensures that services can register and deregister themselves as they scale, maintaining operational efficiency.
- Database Sharding:
- We split databases into smaller, more manageable pieces (shards) to improve performance and scalability.
- Our team ensures that each microservice can access its relevant shard efficiently, optimizing data retrieval.
- Asynchronous Communication:
- We use message queues (e.g., RabbitMQ, Kafka) for asynchronous communication between services.
- This decouples services and allows them to scale independently, enhancing overall system performance.
- Monitoring and Auto-Scaling:
- We implement monitoring tools to track performance metrics and set up auto-scaling rules based on load.
- Our team uses alerts to notify when services are underperforming or require scaling, ensuring high availability.
By partnering with Rapid Innovation, organizations can optimize their database queries, effectively implement caching strategies, and scale their microservices to meet growing demands, ultimately achieving greater ROI and operational efficiency. This includes utilizing sql query optimization techniques, performance tuning in sql, and applying sql optimization strategies to enhance overall database performance.
12.1. Horizontal and Vertical Scaling Techniques
Scaling is essential for managing increased loads on applications. There are two primary techniques: horizontal and vertical scaling.
Horizontal Scaling (Scale Out/In)
- Involves adding more machines or instances to handle increased load.
- Benefits include:
- Improved fault tolerance.
- Better resource utilization.
- Easier to manage large-scale applications.
- Commonly used in cloud environments where resources can be dynamically allocated.
- Application scaling techniques are crucial in this context, as they help determine the best approach to scale out effectively.
Vertical Scaling (Scale Up/Down)
- Involves adding more resources (CPU, RAM) to an existing machine.
- Benefits include:
- Simplicity in management since only one instance is involved.
- No need for application changes to distribute load.
- Limitations include:
- Physical hardware limits.
- Downtime during upgrades.
Both techniques can be used in tandem for optimal performance. For instance, a system can be vertically scaled until it reaches its limits, after which horizontal scaling can be implemented. Scaling techniques for applications are essential to understand in order to choose the right method for specific needs.
12.2. Load Balancing with Nginx
Nginx is a powerful web server that can also function as a load balancer. It distributes incoming traffic across multiple servers, ensuring no single server becomes overwhelmed.
Key Features of Nginx Load Balancing
- Supports various load balancing methods:
- Round Robin: Distributes requests evenly across servers.
- Least Connections: Directs traffic to the server with the fewest active connections.
- IP Hash: Routes requests based on the client's IP address, ensuring consistent routing.
Steps to Set Up Load Balancing with Nginx
- Install Nginx on your server.
- Configure the Nginx configuration file (usually located at
/etc/nginx/nginx.conf). - Define upstream servers:
language="language-nginx"upstream backend {-a1b2c3- server backend1.example.com;-a1b2c3- server backend2.example.com;-a1b2c3-}
- Set up the server block to use the upstream:
language="language-nginx"server {-a1b2c3- listen 80;-a1b2c3- location / {-a1b2c3- proxy_pass http://backend;-a1b2c3- }-a1b2c3-}
- Test the configuration:
language="language-bash"nginx -t
- Restart Nginx to apply changes:
language="language-bash"systemctl restart nginx
Nginx also provides health checks to ensure that traffic is only sent to healthy servers, enhancing reliability.
12.3. Implementing Auto-scaling in Kubernetes
Auto-scaling in Kubernetes allows applications to automatically adjust the number of active pods based on current demand. This ensures optimal resource usage and cost efficiency.
Key Components of Kubernetes Auto-scaling
- Horizontal Pod Autoscaler (HPA): Automatically scales the number of pods in a deployment based on observed CPU utilization or other select metrics.
- Cluster Autoscaler: Adjusts the number of nodes in a cluster based on the resource requests of the pods.
Steps to Implement Auto-scaling in Kubernetes
- Ensure metrics server is installed in your cluster:
language="language-bash"kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
- Create a deployment:
language="language-bash"kubectl create deployment my-app --image=my-app-image
- Expose the deployment:
language="language-bash"kubectl expose deployment my-app --type=LoadBalancer --port=80
- Create an HPA resource:
language="language-bash"kubectl autoscale deployment my-app --cpu-percent=50 --min=1 --max=10
- Monitor the scaling:
language="language-bash"kubectl get hpa
By implementing auto-scaling, Kubernetes can dynamically adjust resources based on real-time demand, ensuring applications remain responsive and cost-effective.
At Rapid Innovation, we leverage these advanced scaling techniques and load balancing strategies to help our clients optimize their applications, ensuring they can handle increased traffic and workloads efficiently. By partnering with us, clients can expect improved performance, reduced downtime, and ultimately, a greater return on investment. Our expertise in AI and Blockchain development further enhances our ability to deliver tailored solutions that align with your business goals.
13. Error Handling and Resilience
Error handling is a critical aspect of software development, ensuring that applications can gracefully manage unexpected situations. At Rapid Innovation, we understand the importance of robust error handling in creating resilient applications, particularly when leveraging technologies like Rust. Our expertise in AI and Blockchain development allows us to guide clients in implementing effective error management strategies that enhance application performance and reliability.
13.1. Robust Error Handling in Rust
Rust employs a unique approach to error handling that distinguishes between two types of errors: recoverable and unrecoverable. This is primarily achieved through the use of the Result and Option types.
- Result Type:
- Represents either success (
Ok) or failure (Err). - Encourages developers to handle errors explicitly, reducing the chances of unhandled exceptions.
- Represents either success (
- Option Type:
- Represents a value that can be either
Some(a valid value) orNone(no value). - Useful for functions that may not return a value, allowing for safe handling of absence.
- Represents a value that can be either
Rust's error handling promotes the use of pattern matching, which allows developers to handle different error cases effectively.
- Pattern Matching:
- Enables concise and clear handling of various outcomes.
- Example:
language="language-rust"fn divide(a: f64, b: f64) -> Result<f64, String> {-a1b2c3- if b == 0.0 {-a1b2c3- Err("Cannot divide by zero".to_string())-a1b2c3- } else {-a1b2c3- Ok(a / b)-a1b2c3- }-a1b2c3-}-a1b2c3--a1b2c3-match divide(4.0, 0.0) {-a1b2c3- Ok(result) => println!("Result: {}", result),-a1b2c3- Err(e) => println!("Error: {}", e),-a1b2c3-}
- Error Propagation:
- Rust allows for easy propagation of errors using the
?operator. - This operator simplifies error handling by returning early from functions when an error occurs.
- Rust allows for easy propagation of errors using the
- Custom Error Types:
- Developers can define their own error types to provide more context.
- This can be done by implementing the
std::error::Errortrait.
- Logging Errors:
- Using crates like
logorsentrycan help in logging errors for better monitoring and debugging.
- Using crates like
13.2. Implementing Retry Mechanisms
In scenarios where transient errors may occur, implementing retry mechanisms can enhance the resilience of applications. This is particularly useful in network calls or database operations where temporary failures are common.
- Exponential Backoff:
- A common strategy for retrying operations that gradually increases the wait time between retries.
- Helps to reduce the load on the system and increases the chances of success.
- Basic Retry Logic:
- Define a maximum number of retries and a delay between attempts.
- Example:
language="language-rust"use std::time::Duration;-a1b2c3-use std::thread::sleep;-a1b2c3--a1b2c3-fn retry<F, T, E>(mut operation: F, max_retries: usize) -> Result<T, E>-a1b2c3-where-a1b2c3- F: FnMut() -> Result<T, E>,-a1b2c3-{-a1b2c3- let mut attempts = 0;-a1b2c3- while attempts < max_retries {-a1b2c3- match operation() {-a1b2c3- Ok(result) => return Ok(result),-a1b2c3- Err(_) => {-a1b2c3- attempts += 1;-a1b2c3- sleep(Duration::from_secs(attempts as u64)); // Exponential backoff can be implemented here-a1b2c3- }-a1b2c3- }-a1b2c3- }-a1b2c3- Err(operation().unwrap_err()) // Return the last error-a1b2c3-}
- Using Libraries:
- Libraries like
retryortokio-retrycan simplify the implementation of retry logic. - These libraries often provide built-in strategies for retries, including exponential backoff.
- Libraries like
- Configurable Parameters:
- Allow configuration of retry limits and delays to adapt to different scenarios.
- This flexibility can help in optimizing performance based on specific use cases.
By implementing robust error handling and retry mechanisms, developers can create resilient applications that can withstand and recover from unexpected failures. At Rapid Innovation, we are committed to helping our clients achieve greater ROI through effective software solutions that prioritize resilience and reliability. Partnering with us means you can expect enhanced application performance, reduced downtime, and a more efficient development process, ultimately leading to greater success in your business endeavors.
13.3. Graceful Degradation and Fallback Strategies
Graceful degradation is a design principle that ensures a system continues to function, albeit with reduced capabilities, when some components fail. This approach is crucial for maintaining user experience and system reliability.
- Key Concepts:
- User Experience: Prioritize maintaining a usable interface even when some features are unavailable.
- Fallback Strategies: Implement alternative methods to provide essential functionality when primary services fail.
- Implementation Steps:
- Identify critical features of your application.
- Design fallback mechanisms for each feature, such as:
- Static content delivery when dynamic content fails.
- Cached data usage when real-time data is unavailable.
- Monitor system performance and user feedback to refine fallback strategies.
- Examples:
- A video streaming service may reduce video quality instead of stopping playback entirely.
- An e-commerce site could display previously viewed items from cache if the recommendation engine is down.
- Benefits:
- Enhances user trust and satisfaction.
- Reduces the impact of failures on business operations.
14. API Gateway and Service Mesh
An API Gateway acts as a single entry point for managing and routing requests to various microservices. It simplifies client interactions and provides essential features like authentication, logging, and load balancing. The design pattern of an API Gateway is crucial in microservices architecture.
- Key Features:
- Request Routing: Directs incoming requests to the appropriate service.
- Rate Limiting: Controls the number of requests a service can handle to prevent overload.
- Security: Enforces authentication and authorization policies.
A Service Mesh complements the API Gateway by managing service-to-service communication, providing observability, and enhancing security.
- Key Features:
- Traffic Management: Controls how requests are routed between services.
- Service Discovery: Automatically detects services and their instances.
- Resilience: Implements retries, timeouts, and circuit breakers to improve reliability.
- Implementation Steps:
- Choose an API Gateway solution (e.g., Kong, NGINX, AWS API Gateway design).
- Set up the gateway to route requests to microservices.
- Integrate a service mesh (e.g., Istio, Linkerd) to manage internal service communication.
- Configure observability tools to monitor performance and troubleshoot issues.
14.1. Implementing an API Gateway with Rust
Rust is known for its performance and safety, making it an excellent choice for building an API Gateway. Here’s how to implement a simple API Gateway using Rust.
- Prerequisites:
- Install Rust and Cargo.
- Familiarity with asynchronous programming in Rust.
- Implementation Steps:
- Create a new Rust project:
language="language-bash"cargo new api_gateway-a1b2c3- cd api_gateway
- Add dependencies in
Cargo.toml:
language="language-toml"[dependencies]-a1b2c3- actix-web = "4.0"-a1b2c3- reqwest = { version = "0.11", features = ["json"] }
- Implement the API Gateway:
language="language-rust"use actix_web::{web, App, HttpServer, HttpResponse};-a1b2c3- use reqwest::Client;-a1b2c3--a1b2c3- async fn proxy_request(client: web::Data<Client>, path: web::Path<String>) -> HttpResponse {-a1b2c3- let response = client.get(format!("http://service_url/{}", path)).await;-a1b2c3--a1b2c3- match response {-a1b2c3- Ok(res) => HttpResponse::Ok().body(res.text().await.unwrap()),-a1b2c3- Err(_) => HttpResponse::InternalServerError().finish(),-a1b2c3- }-a1b2c3- }-a1b2c3--a1b2c3- #[actix_web::main]-a1b2c3- async fn main() -> std::io::Result<()> {-a1b2c3- let client = Client::new();-a1b2c3- HttpServer::new(move || {-a1b2c3- App::new()-a1b2c3- .app_data(web::Data::new(client.clone()))-a1b2c3- .route("/{path:.*}", web::get().to(proxy_request))-a1b2c3- })-a1b2c3- .bind("127.0.0.1:8080")?-a1b2c3- .run()-a1b2c3- .await-a1b2c3- }
- Run the API Gateway:
language="language-bash"cargo run
- Testing:
- Use tools like Postman or curl to send requests to your API Gateway and verify it routes correctly to the intended services.
This implementation provides a basic structure for an API Gateway in Rust, allowing for further enhancements such as authentication, logging, and error handling.
At Rapid Innovation, we leverage these principles and technologies, including the API Gateway design pattern and system design API Gateway, to help our clients build resilient systems that not only meet their immediate needs but also adapt to future challenges. By partnering with us, clients can expect improved system reliability, enhanced user satisfaction, and ultimately, a greater return on investment. Our expertise in AI and Blockchain development ensures that we deliver solutions that are not only effective but also innovative, helping you stay ahead in a competitive landscape.
14.2. Service Discovery and Load Balancing
At Rapid Innovation, we understand that service discovery and load balancing are critical components in microservices architecture, ensuring that services can communicate efficiently and reliably. Our expertise in these areas can help your organization achieve greater operational efficiency and return on investment (ROI).
Service Discovery:
- Service discovery allows services to find and communicate with each other dynamically, which is essential for maintaining seamless operations.
- It can be implemented in two ways:
- Client-side discovery: The client is responsible for determining the location of the service instances, which can lead to increased complexity, especially in scenarios like client side load balancing spring boot microservices.
- Server-side discovery: The client sends requests to a load balancer, which then forwards the request to the appropriate service instance, simplifying the process.
- Common tools for service discovery include:
- Consul: Provides service discovery and health checking, ensuring that your services are always available.
- Eureka: A REST-based service that is part of the Netflix OSS stack, known for its reliability, and supports load balancing in addition to service discovery.
- Kubernetes: Uses built-in DNS for service discovery, making it a popular choice for modern applications, particularly in the context of service discovery and load balancing in Kubernetes.
By leveraging our expertise in service discovery, we can help you implement the most suitable solution for your needs, ultimately enhancing your system's reliability and performance.
Load Balancing:
- Load balancing distributes incoming network traffic across multiple servers to ensure no single server becomes overwhelmed, which is vital for maintaining high availability.
- It can be implemented at different layers:
- Layer 4 (Transport Layer): Directs traffic based on IP address and TCP/UDP ports, providing a straightforward approach.
- Layer 7 (Application Layer): Makes routing decisions based on the content of the request (e.g., HTTP headers), allowing for more intelligent traffic management.
- Popular load balancers include:
- NGINX: Acts as a reverse proxy and load balancer, known for its performance and flexibility.
- HAProxy: A high-performance TCP/HTTP load balancer, ideal for handling large volumes of traffic, and is often used in conjunction with Kubernetes service discovery.
- AWS Elastic Load Balancing: Automatically distributes incoming application traffic, ensuring optimal resource utilization.
By partnering with Rapid Innovation, you can expect to enhance your system's performance and reliability, leading to improved customer satisfaction and increased ROI. Our solutions, such as spring cloud load balancer with eureka example, illustrate how we support load balancing in addition to service discovery.
14.3. Introducing Service Mesh with Linkerd
A service mesh is an infrastructure layer that manages service-to-service communication, providing features like traffic management, security, and observability. Our team at Rapid Innovation can help you implement a service mesh to streamline your microservices architecture.
Linkerd:
- Linkerd is a lightweight service mesh designed for simplicity and performance, making it an excellent choice for organizations looking to enhance their microservices.
- It provides several key features:
- Traffic Management: Enables fine-grained control over traffic routing, retries, and timeouts, ensuring optimal service performance.
- Security: Offers mTLS (mutual TLS) for secure communication between services, protecting sensitive data.
- Observability: Provides metrics, tracing, and logging to monitor service interactions, allowing for proactive issue resolution.
Key Components of Linkerd:
- Data Plane: Consists of lightweight proxies deployed alongside each service instance, intercepting and managing traffic for improved performance.
- Control Plane: Manages the configuration and policies for the data plane proxies, simplifying management tasks.
Steps to Install Linkerd:
- Install the Linkerd CLI:
language="language-bash"curl -sL https://run.linkerd.io/install | sh
- Validate the installation:
language="language-bash"linkerd check
- Install Linkerd on your Kubernetes cluster:
language="language-bash"linkerd install | kubectl apply -f -
- Add Linkerd to your application:
language="language-bash"linkerd inject deployment.yaml | kubectl apply -f -
15. Security Best Practices
Implementing security best practices is essential in microservices architecture to protect sensitive data and ensure secure communication. At Rapid Innovation, we prioritize security in all our solutions.
Best Practices:
- Use mTLS: Ensure that all service-to-service communication is encrypted using mutual TLS to prevent eavesdropping and man-in-the-middle attacks.
- Implement API Gateway: Use an API gateway to manage authentication, authorization, and rate limiting for incoming requests, enhancing security.
- Regularly Update Dependencies: Keep all libraries and dependencies up to date to mitigate vulnerabilities, ensuring your system remains secure.
- Conduct Security Audits: Regularly perform security audits and penetration testing to identify and address potential weaknesses, safeguarding your infrastructure.
- Use Network Policies: In Kubernetes, implement network policies to control traffic flow between services, limiting exposure to only necessary communications.
- Monitor and Log: Continuously monitor and log service interactions to detect anomalies and respond to potential security incidents promptly.
By collaborating with Rapid Innovation, you can expect a robust and secure microservices architecture that not only meets your business needs but also enhances your overall ROI. Our commitment to excellence ensures that your organization can thrive in a competitive landscape.
15.1. Secure Coding Practices in Rust
At Rapid Innovation, we understand that Rust is designed with safety in mind, making it an excellent choice for secure coding practices in rust. Here are some secure coding practices that we recommend to our clients:
- Use the Ownership Model: Rust's ownership model helps prevent data races and memory leaks. It is crucial to understand how ownership, borrowing, and lifetimes work to avoid common pitfalls, ensuring your applications run smoothly and securely.
- Leverage the Type System: Rust's strong type system can help catch errors at compile time. We advise using enums and structs to represent data accurately and avoiding generic types when specific types are needed, which can lead to more robust applications.
- Avoid Unsafe Code: While Rust allows for unsafe code, it should be used sparingly. Always question the necessity of using
unsafeand ensure that you fully understand the implications. Our team can guide you in making informed decisions about when to use this feature. - Input Validation: Always validate user input to prevent injection attacks. Utilizing libraries like
regexfor pattern matching and validation is essential for maintaining application integrity. - Error Handling: Use Rust's
ResultandOptiontypes for error handling instead of panicking. This approach allows for more graceful error recovery, enhancing user experience and application reliability. - Dependencies Management: Regularly updating dependencies and using tools like
cargo auditto check for vulnerabilities in third-party libraries is vital. We can assist in establishing a robust dependency management strategy to mitigate risks.
15.2. Implementing Rate Limiting and Throttling
At Rapid Innovation, we recognize that rate limiting and throttling are essential for protecting applications from abuse and ensuring fair usage. Here’s how we help our clients implement these strategies:
- Define Rate Limits: We work with you to determine the maximum number of requests a user can make in a given timeframe (e.g., 100 requests per hour), tailored to your application's needs.
- Choose a Storage Mechanism: Our team recommends using in-memory stores like Redis or databases to track user requests, allowing for quick access and updates.
- Implement Middleware: We can help create middleware in your application to intercept requests and check against the defined rate limits, ensuring compliance and security.
- Use Tokens: Implementing a token bucket algorithm where users are given tokens for requests is a strategy we advocate. If they exceed the limit, we can help you deny further requests until tokens are replenished.
- Return Appropriate Responses: When a user exceeds the rate limit, we ensure that your application returns a
429 Too Many Requestsstatus code along with a message indicating when they can try again, maintaining transparency with users. - Monitor and Adjust: Our experts continuously monitor usage patterns and adjust rate limits as necessary to balance user experience and security, ensuring optimal performance.
15.3. Handling Sensitive Data and Encryption
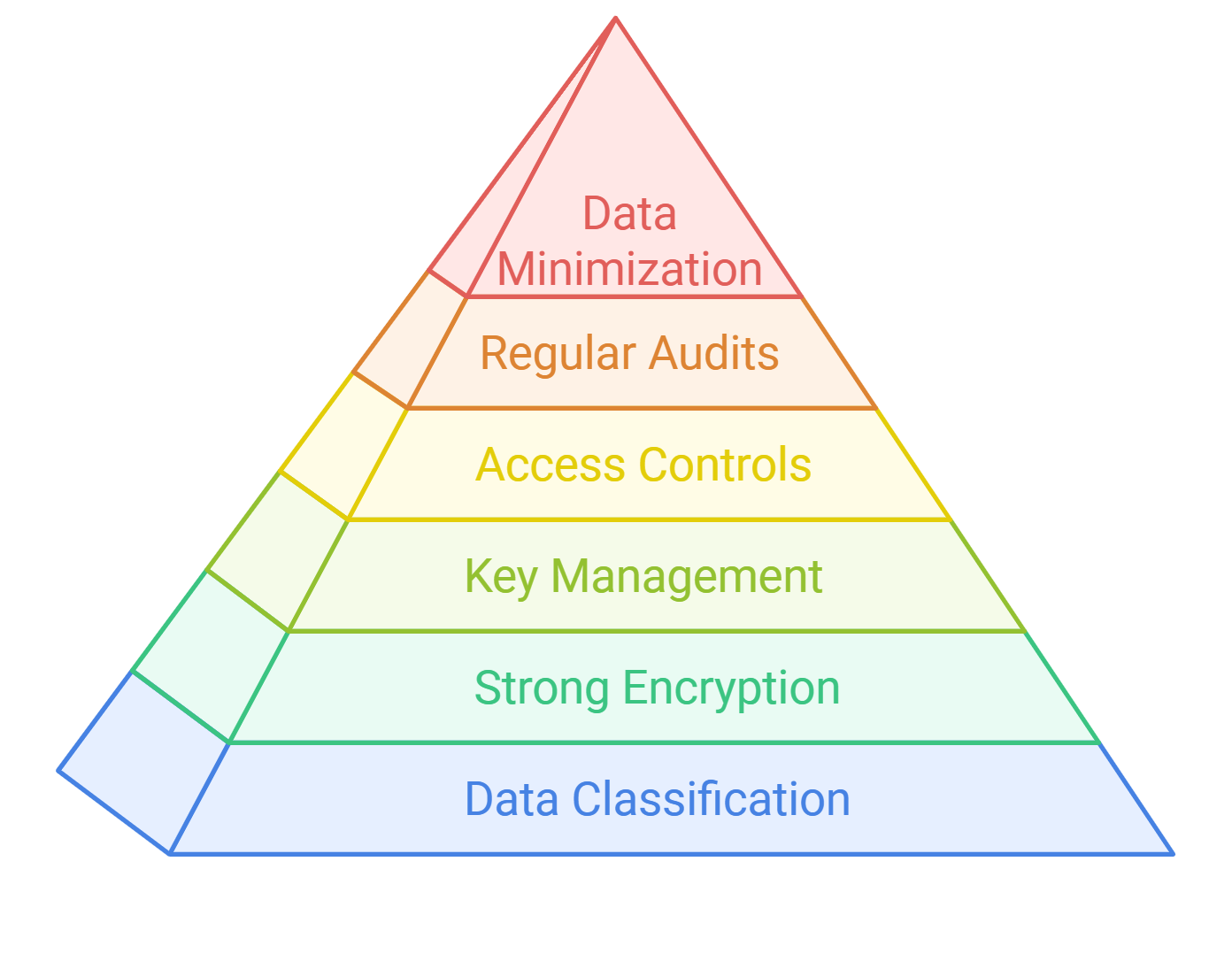
Handling sensitive data securely is crucial for any application, and at Rapid Innovation, we emphasize best practices for managing sensitive data and encryption:
- Data Classification: We assist in identifying and classifying sensitive data (e.g., personal information, financial data) to apply appropriate security measures tailored to your business needs.
- Use Strong Encryption: Always encrypt sensitive data both at rest and in transit. We recommend using established algorithms like AES for encryption and TLS for secure communication to protect your data.
- Key Management: Implementing a secure key management strategy is essential. Our team can guide you in using services like AWS KMS or HashiCorp Vault to manage encryption keys securely.
- Access Controls: We help limit access to sensitive data based on the principle of least privilege, ensuring that only authorized users can access or modify sensitive information.
- Regular Audits: Conducting regular security audits and vulnerability assessments is vital. We can assist in identifying and mitigating risks associated with sensitive data handling.
- Data Minimization: Collecting only the data you need and avoiding storing sensitive information unless absolutely necessary is a principle we advocate. This reduces the risk of exposure and enhances your security posture.
By following these practices, our clients can create secure applications that protect user data and maintain trust, ultimately leading to greater ROI and business success. Partnering with Rapid Innovation means you gain access to our expertise, ensuring your projects are executed efficiently and effectively. Refactoring and evolving microservices is a crucial aspect of modern software development, especially when transitioning from monolithic architectures. This process involves breaking down large, complex systems into smaller, manageable services that can be developed, deployed, and scaled independently. Refactoring monolithic to microservices is a key step in this journey.
16.1. Strategies for Breaking Down Monoliths
Breaking down a monolithic application into microservices can be challenging but is essential for improving scalability, maintainability, and deployment speed. Here are some effective strategies:
- Identify Business Capabilities:
- Analyze the existing monolith to identify distinct business capabilities.
- Group related functionalities that can be encapsulated into a microservice.
- Use Domain-Driven Design (DDD):
- Apply DDD principles to define bounded contexts.
- Each bounded context can become a separate microservice, ensuring clear ownership and responsibility.
- Strangle Pattern:
- Gradually replace parts of the monolith with microservices.
- Start by routing new features to the microservice while keeping existing functionality in the monolith until fully transitioned.
- Decompose by Subdomains:
- Break down the monolith based on subdomains identified in the business model.
- Each subdomain can be developed as an independent microservice.
- Data Ownership:
- Ensure that each microservice owns its data.
- Avoid shared databases to reduce coupling between services.
- Incremental Refactoring:
- Refactor the monolith incrementally rather than attempting a complete rewrite.
- This approach minimizes risk and allows for continuous delivery, making refactoring to microservices more manageable.
- Automated Testing:
- Implement automated tests to ensure that existing functionality remains intact during the refactoring process.
- Use unit tests, integration tests, and end-to-end tests to cover various aspects of the application.
- Monitoring and Observability:
- Establish monitoring and logging to track the performance of both the monolith and the new microservices.
- Use tools like Prometheus or ELK stack for observability.
16.2. Versioning Microservices APIs
Versioning APIs is essential for maintaining backward compatibility while evolving microservices. Here are some strategies for effective versioning:
- URI Versioning:
- Include the version number in the API endpoint (e.g.,
/api/v1/resource). - This method is straightforward and easy to implement.
- Include the version number in the API endpoint (e.g.,
- Query Parameter Versioning:
- Use query parameters to specify the version (e.g.,
/api/resource?version=1). - This approach allows clients to request specific versions without changing the endpoint structure.
- Use query parameters to specify the version (e.g.,
- Header Versioning:
- Specify the version in the request header (e.g.,
Accept: application/vnd.yourapi.v1+json). - This method keeps the URL clean but may require more complex client implementations.
- Specify the version in the request header (e.g.,
- Semantic Versioning:
- Follow semantic versioning principles (MAJOR.MINOR.PATCH) to communicate changes effectively.
- Increment the major version for breaking changes, minor for new features, and patch for bug fixes.
- Deprecation Policy:
- Establish a clear deprecation policy for older versions.
- Communicate changes to clients well in advance and provide a timeline for phasing out old versions.
- Documentation:
- Maintain comprehensive documentation for each version of the API.
- Ensure that clients can easily understand the differences and migration paths between versions.
- Testing Across Versions:
- Implement tests to ensure that new versions do not break existing functionality.
- Use contract testing to verify that the API adheres to expected behaviors.
By employing these strategies, organizations can effectively refactor their monolithic applications into microservices and manage API versioning, ensuring a smooth transition and ongoing evolution of their software architecture. Refactoring microservices is an ongoing process that requires attention to detail and a commitment to best practices.
At Rapid Innovation, we specialize in guiding our clients through this transformative journey. Our expertise in AI and Blockchain development allows us to tailor solutions that not only meet your unique business needs but also enhance your operational efficiency. By partnering with us, you can expect greater ROI through improved scalability, reduced time-to-market, and a more agile development process. Let us help you unlock the full potential of your software architecture and achieve your business goals effectively and efficiently.
16.3. Managing Database Schema Changes
At Rapid Innovation, we understand that managing database schema changes is a critical aspect of software development, particularly for applications that evolve over time. Schema changes can encompass adding new tables, modifying existing ones, or altering relationships between tables. Our expertise in this area ensures data integrity and minimizes downtime, ultimately leading to greater efficiency and effectiveness for our clients.
- Version Control for Database Schemas
- We recommend utilizing tools like Liquibase or Flyway to version control your database schema. Our team will help you maintain a comprehensive changelog that documents each change, including the date, author, and purpose, ensuring transparency and traceability. This is particularly important for database schema management and schema version control.
- Backward Compatibility
- Our approach emphasizes the importance of backward compatibility to avoid breaking existing functionality. We employ techniques such as adding new columns instead of modifying existing ones, which allows for seamless transitions and minimal disruption. This is crucial for maintaining the integrity of your inventory database schema and other related schemas.
- Testing Schema Changes
- We implement a robust testing strategy that includes unit tests and integration tests for schema changes. By utilizing a staging environment to test changes before deploying to production, we help mitigate risks and ensure a smooth rollout. This is especially relevant for database schema change management tools.
- Rollback Strategies
- Our team prepares rollback scripts to swiftly revert changes if any issues arise. Additionally, we emphasize the importance of regular database backups to restore it to a previous state when necessary, safeguarding your data. This is vital for any configuration management database schema.
- Communication with Team
- Effective communication is key. We ensure that all stakeholders are informed about upcoming schema changes and document these changes in a shared repository for easy access, fostering collaboration and alignment. This is essential for project management database schema and other related schemas.
17. Case Study: Building a Real-world Application
Building a real-world application involves several stages, from initial planning to deployment and maintenance. At Rapid Innovation, we guide our clients through these key steps, focusing on the challenges faced and the solutions we implement to achieve greater ROI.
- Defining Requirements
- We gather requirements from stakeholders through interviews and surveys, creating user stories that capture both functional and non-functional requirements. This thorough understanding allows us to align the project with your business goals.
- Choosing Technology Stack
- ur team assists in selecting a technology stack that aligns with project goals and team expertise. Common stacks we recommend include MERN (MongoDB, Express, React, Node.js) or LAMP (Linux, Apache, MySQL, PHP), ensuring optimal performance and scalability. This is particularly relevant for MongoDB inventory management schema.
- Agile Development Methodology
- We adopt an Agile approach to facilitate iterative development and continuous feedback. Regular sprint reviews and retrospectives help us refine processes and deliver value more efficiently.
- User Interface Design
- Our design team creates wireframes and prototypes to visualize the application, utilizing tools like Figma or Adobe XD for design collaboration. This ensures that the final product meets user expectations and enhances user experience.
- Implementation
- We break down the application into smaller components for easier management and use version control systems like Git to track changes and collaborate effectively, ensuring a streamlined development process. This is crucial for database schema management tools.
- Testing and Quality Assurance
- Our commitment to quality includes implementing automated testing for both frontend and backend components. We conduct user acceptance testing (UAT) to ensure the application meets user needs and expectations.
- Deployment
- We leverage Continuous Integration/Continuous Deployment (CI/CD) pipelines for automated deployment, choosing cloud platforms like AWS or Azure for hosting the application, which enhances reliability and scalability.
- Monitoring and Maintenance
- Our team sets up monitoring tools to track application performance and user behavior, allowing for proactive maintenance. We regularly update the application to fix bugs and add new features, ensuring it remains relevant and effective.
17.1. Designing the System Architecture
Designing the system architecture is crucial for ensuring scalability, reliability, and maintainability of the application. At Rapid Innovation, we focus on creating a well-thought-out architecture that significantly impacts the application's performance and user experience.
- Microservices Architecture
- We consider using a microservices architecture to break the application into smaller, independent services. This approach allows each service to be developed, deployed, and scaled independently, enhancing flexibility and responsiveness.
- Database Design
- Our experts help you choose the right database type (SQL vs. NoSQL) based on your data requirements. We prioritize normalizing data to reduce redundancy while ensuring efficient access patterns, which optimizes performance. This is particularly relevant for asset management database schema and other related schemas.
- API Design
- We design RESTful APIs for seamless communication between frontend and backend services. By using OpenAPI specifications to document APIs, we facilitate better collaboration among development teams.
- Load Balancing
- Implementing load balancers is part of our strategy to distribute traffic evenly across servers, ensuring high availability and improved response times for your application.
- Caching Strategies
- We utilize caching mechanisms like Redis or Memcached to reduce database load, caching frequently accessed data to enhance performance and user experience.
- Security Measures
- Our commitment to security includes implementing best practices such as data encryption and secure authentication. We also prioritize regularly updating dependencies to mitigate vulnerabilities.
By partnering with Rapid Innovation, clients can effectively manage database schema changes and build robust applications that meet user needs while being scalable and maintainable. Our expertise ensures that you achieve greater ROI, allowing you to focus on your core business objectives. This includes managing various database schemas such as property management database schema, it asset management database schema, and more.
17.2. Implementing Key Microservices
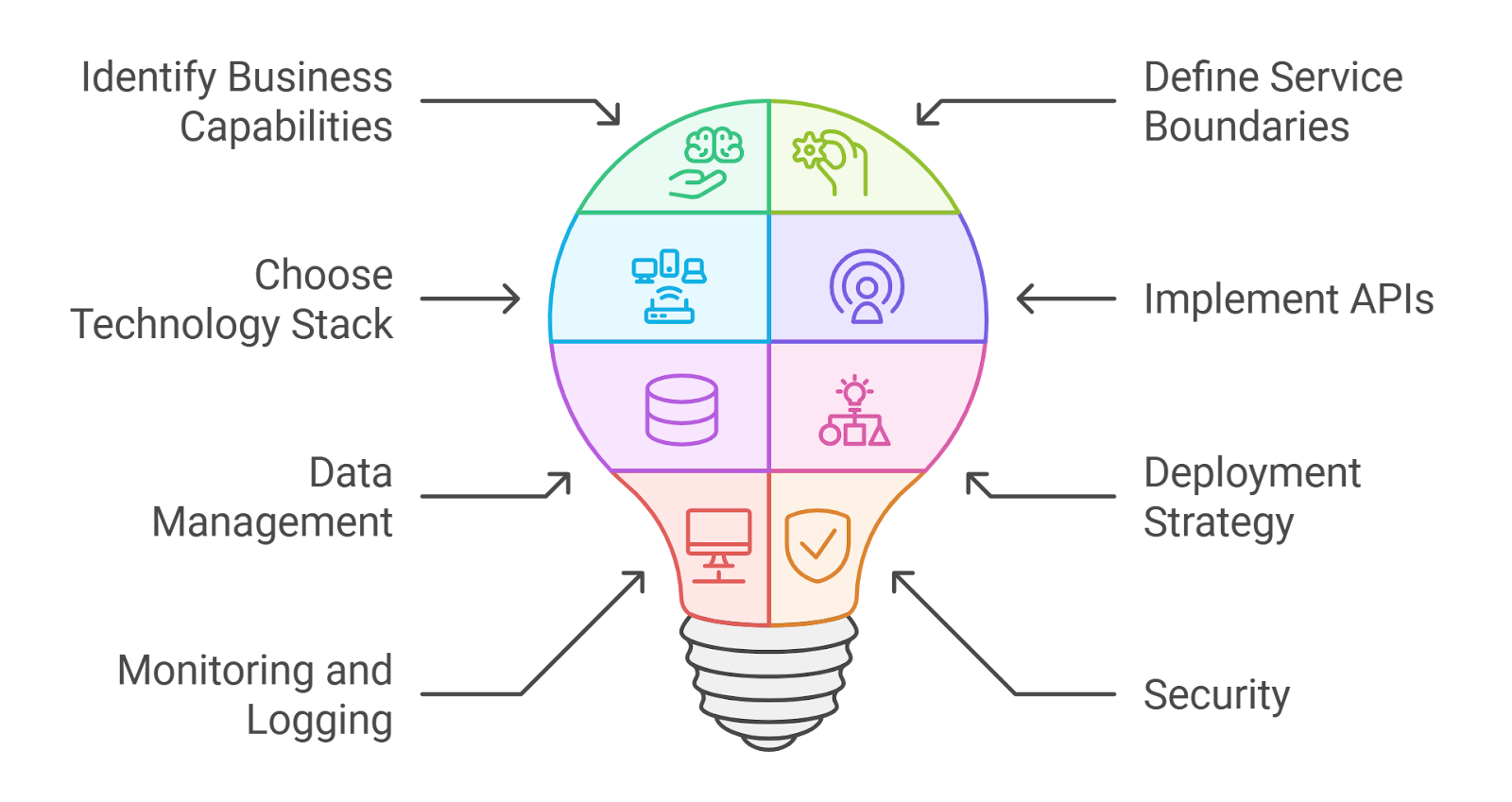
At Rapid Innovation, we understand that microservices architecture allows for the development of applications as a suite of small, independent services. Each service focuses on a specific business capability and can be developed, deployed, and scaled independently. Implementing key microservices involves several steps:
- Identify Business Capabilities: We assist clients in breaking down their applications into distinct business functions. For example, in an e-commerce application, we might help identify services for user management, product catalog, order processing, and payment processing, ensuring that each function is optimized for performance.
- Define Service Boundaries: Our team works with clients to clearly define the boundaries of each microservice. This minimizes dependencies and ensures that each service can operate independently, leading to greater flexibility and faster deployment cycles.
- Choose Technology Stack: We guide clients in selecting the appropriate technologies for each microservice. This could include programming languages, databases, and frameworks that best suit the service's requirements, ultimately enhancing performance and maintainability. For instance, we may recommend implementing microservices in node js or using .NET 5 for microservices architecture and implementation.
- Implement APIs: Our experts design RESTful APIs or GraphQL endpoints for seamless communication between services. We ensure that the APIs are well-documented and versioned to facilitate future changes, which is crucial for maintaining a competitive edge. This includes implementing health check APIs for microservices to monitor their status.
- Data Management: We help clients decide on the best data storage strategy. Each microservice can have its own database, which helps in maintaining data integrity and independence, leading to improved data management and security. We also assist in implementing rabbitmq in microservices for effective messaging.
- Deployment Strategy: Utilizing containerization (e.g., Docker) and orchestration tools (e.g., Kubernetes), we implement deployment strategies that allow for easy scaling and management of services, ensuring that clients can respond quickly to market demands. This may involve implementing a red-black deployment strategy for microservice applications.
- Monitoring and Logging: We implement monitoring tools (e.g., Prometheus, Grafana) and centralized logging (e.g., ELK stack) to track the performance and health of microservices, enabling proactive issue resolution and performance optimization. This is essential for implementing microservices architecture effectively.
- Security: Our team ensures that each microservice is secured by implementing robust authentication and authorization mechanisms (e.g., OAuth2, JWT), safeguarding client data and maintaining compliance with industry standards. We also focus on implementing security in microservices to protect sensitive information.
17.3. Integrating Third-party Services
Integrating third-party services can significantly enhance the functionality of your application without the need to build everything from scratch. Here are steps to effectively integrate these services:
- Identify Required Services: We work with clients to determine which third-party services can add value to their applications. This could include payment gateways, email services, or analytics tools, ensuring that the integrations align with business goals.
- Review Documentation: Our team thoroughly reviews the API documentation of the third-party service, understanding the authentication methods, rate limits, and data formats to ensure a smooth integration process.
- Set Up Authentication: We implement the necessary authentication methods, such as OAuth or API keys, as specified in the documentation, ensuring secure and reliable access to third-party services.
- Create Integration Layer: We develop an integration layer within the application that handles communication with the third-party service. This layer manages API calls, error handling, and data transformation, streamlining the integration process.
- Test Integration: Before going live, we rigorously test the integration in a staging environment, checking for edge cases and ensuring that the application handles failures gracefully, which minimizes downtime and enhances user experience.
- Monitor Performance: After deployment, we continuously monitor the performance of the integrated services, using tools to track response times and error rates, allowing for timely adjustments and improvements.
- Stay Updated: Our team keeps an eye on updates from the third-party service provider, ensuring that any changes in their API are promptly addressed, maintaining the integrity of the integration.
18. Advanced Topics and Future Trends
As microservices and third-party integrations evolve, several advanced topics and future trends are emerging:
- Service Mesh: We explore the implementation of a dedicated infrastructure layer that manages service-to-service communication, providing features like load balancing, service discovery, and security, enhancing overall application performance.
- Serverless Architecture: Our team leverages serverless computing to run microservices without managing servers, leading to cost savings and increased scalability for our clients.
- Event-Driven Architecture: We implement event-driven patterns to enable asynchronous communication between microservices, improving responsiveness and scalability, which is essential for modern applications. This includes implementing saga patterns for managing distributed transactions.
- AI and Machine Learning Integration: We help clients leverage AI and ML services to enhance application capabilities, such as personalized recommendations or predictive analytics, driving greater user engagement and satisfaction.
- API Management: As the number of APIs grows, we emphasize effective API management, utilizing tools for monitoring, securing, and analyzing API usage, which is crucial for maintaining operational efficiency.
- DevOps Practices: We advocate for continuous integration and continuous deployment (CI/CD) practices to streamline the development and deployment of microservices, ensuring that our clients can innovate rapidly and respond to market changes.
By focusing on these areas, organizations can build robust, scalable applications that leverage the power of microservices and third-party integrations, ultimately achieving greater ROI and business success when partnering with Rapid Innovation.
18.1. Serverless Microservices with Rust
At Rapid Innovation, we understand that serverless architecture empowers developers to build and run applications without the burden of managing servers. Rust, renowned for its performance and safety, stands out as an exceptional choice for serverless microservices with Rust, enabling our clients to achieve their goals efficiently.
Benefits of using Rust in serverless microservices:
- Performance: Rust's compiled nature leads to faster execution times, which is crucial for serverless environments where cold start times can impact performance. This means your applications can respond more quickly to user requests, enhancing user satisfaction and engagement.
- Memory Safety: Rust's ownership model ensures memory safety without a garbage collector, reducing runtime errors and improving reliability. This translates to fewer disruptions and a more stable application, ultimately leading to higher customer retention.
- Concurrency: Rust's concurrency model allows for efficient handling of multiple requests, making it suitable for high-load scenarios. This capability ensures that your applications can scale seamlessly, accommodating growth without compromising performance.
To create serverless microservices with Rust, follow these steps:
- Set up a Rust environment:
- Install Rust using
rustup. - Create a new Rust project with
cargo new my_serverless_service.
- Install Rust using
- Choose a serverless platform:
- AWS Lambda, Azure Functions, or Google Cloud Functions are popular choices.
- Write your microservice:
- Implement your business logic in Rust.
- Use frameworks like
actix-weborwarpfor building web services.
- Package and deploy:
- Use tools like
serverless-rustorcargo-lambdato package your application. - Deploy to your chosen serverless platform.
- Use tools like
18.2. Machine Learning Integration in Microservices
Integrating machine learning (ML) into microservices allows for scalable and modular applications that can leverage advanced analytics and predictions. At Rapid Innovation, we help clients harness the power of ML to drive innovation and improve decision-making.
Key considerations for ML integration:
- Model Deployment: Use containerization (e.g., Docker) to deploy ML models as microservices, ensuring consistency across environments. This approach minimizes deployment issues and accelerates time-to-market.
- API Design: Create RESTful APIs for your ML models, allowing other microservices to interact with them easily. This modularity enhances collaboration and integration across your technology stack.
- Data Management: Ensure proper data pipelines for training and inference, using tools like Apache Kafka or Apache Airflow. Effective data management leads to more accurate models and better insights.
Steps to integrate ML into microservices:
- Train your ML model:
- Use libraries like TensorFlow or PyTorch to develop and train your model.
- Save the trained model in a format suitable for deployment (e.g., ONNX).
- Create a microservice for the model:
- Set up a new microservice project using a framework like Flask or FastAPI.
- Load the trained model in your service.
- Expose an API:
- Define endpoints for predictions and model management (e.g.,
/predict,/retrain). - Implement input validation and error handling.
- Define endpoints for predictions and model management (e.g.,
- Deploy the microservice:
- Use containerization to package your service.
- Deploy to a cloud provider or Kubernetes for scalability.
18.3. Edge Computing and Microservices
Edge computing brings computation and data storage closer to the location where it is needed, reducing latency and bandwidth use. Rapid Innovation leverages this architecture to help clients build more responsive and efficient applications.
Advantages of edge computing in microservices:
- Reduced Latency: Processing data closer to the source minimizes delays, which is critical for real-time applications. This leads to improved user experiences and faster decision-making.
- Bandwidth Efficiency: By processing data at the edge, only necessary information is sent to the cloud, saving bandwidth. This efficiency can lead to cost savings and better resource utilization.
- Scalability: Edge devices can handle local processing, allowing for more scalable applications. This flexibility enables businesses to grow without being constrained by infrastructure limitations.
To implement edge computing with microservices:
- Identify use cases:
- Determine which services can benefit from edge processing (e.g., IoT applications, real-time analytics).
- Design microservices for the edge:
- Create lightweight microservices that can run on edge devices.
- Use frameworks like K3s or OpenFaaS for deploying microservices at the edge.
- Implement data synchronization:
- Ensure that edge services can communicate with central services for data consistency.
- Use message queues or event-driven architectures for real-time updates.
- Monitor and manage:
- Implement monitoring tools to track performance and health of edge microservices.
- Use orchestration tools to manage deployments and updates across edge devices.
By partnering with Rapid Innovation, clients can expect to achieve greater ROI through enhanced performance, reduced operational costs, and improved scalability. Our expertise in AI and blockchain development ensures that your projects are executed efficiently and effectively, driving your business forward in today's competitive landscape.
19. Conclusion and Best Practices
19.1. Recap of Key Concepts
In any technical field, understanding the foundational concepts is crucial for effective implementation and problem-solving. Here’s a recap of key concepts that have been discussed:
- Understanding the Problem: Clearly define the problem you are trying to solve. This includes identifying the requirements and constraints.
- Choosing the Right Tools: Selecting appropriate tools and technologies can significantly impact the efficiency and effectiveness of your solution.
- Implementation Strategy: A well-thought-out implementation strategy ensures that the project progresses smoothly. This includes planning, execution, and testing phases, as well as best practices in Jira and Asana best practices for task management.
- Documentation: Maintaining clear and concise documentation is essential for future reference and for onboarding new team members. This is particularly important in project management ITIL and project management in ITIL contexts.
- Feedback Loops: Incorporating feedback mechanisms allows for continuous improvement and adaptation of the solution based on user needs and performance metrics.
- Testing and Validation: Rigorous testing ensures that the solution meets the defined requirements and functions as intended. Following project scheduling best practices can aid in this process.
- Scalability and Maintenance: Consideration for future growth and ease of maintenance is vital for long-term success.
19.2. Best Practices and Common Pitfalls
Implementing best practices can help avoid common pitfalls that may derail a project. Here are some best practices to consider:
- Plan Thoroughly:
- Conduct a comprehensive analysis of the project requirements.
- Create a detailed project plan with timelines and milestones.
- Engage Stakeholders:
- Involve stakeholders early in the process to gather insights and expectations.
- Regularly update them on progress to maintain alignment.
- Iterative Development:
- Use an agile approach to allow for flexibility and adaptability.
- Break the project into smaller, manageable tasks for easier tracking, applying kanban best practices where applicable.
- Code Quality:
- Follow coding standards and best practices to ensure maintainability.
- Conduct code reviews to catch issues early.
- Automated Testing:
- Implement automated testing to streamline the testing process.
- Regularly run tests to catch regressions and ensure functionality.
- Version Control:
- Use version control systems (like Git) to manage changes and collaborate effectively.
- Maintain a clear commit history for accountability.
- Monitor Performance:
- Set up monitoring tools to track performance metrics.
- Analyze data to identify areas for improvement.
Common pitfalls to avoid include:
- Neglecting Documentation: Failing to document processes can lead to confusion and inefficiencies later on.
- Ignoring User Feedback: Disregarding user input can result in a product that does not meet their needs.
- Overcomplicating Solutions: Striving for overly complex solutions can lead to increased maintenance costs and difficulties in understanding.
- Underestimating Time and Resources: Failing to accurately estimate the time and resources required can lead to project delays and budget overruns.
- Lack of Testing: Skipping or rushing through testing can result in undetected bugs and issues that affect user experience.
By adhering to these best practices, such as best PMP exam prep and best PMP practice exam strategies, and being aware of common pitfalls, you can enhance the likelihood of project success and create solutions that are robust, user-friendly, and maintainable. At Rapid Innovation, we are committed to guiding you through this process, ensuring that your projects not only meet but exceed expectations, ultimately leading to greater ROI and long-term success.
19.3. Resources for Further Learning
In the ever-evolving landscape of technology and knowledge, continuous learning is essential. At Rapid Innovation, we understand the importance of staying ahead in your field. Here are some valuable resources that can help you expand your understanding and skills in various domains, ultimately leading to greater efficiency and effectiveness in achieving your goals.
Online Learning Platforms
- Coursera: Offers courses from top universities and companies. You can find courses on a wide range of topics, from data science to personal development, enabling you to enhance your skill set and drive better ROI.
- edX: Similar to Coursera, edX provides access to high-quality courses from institutions like Harvard and MIT. Many courses are free to audit, allowing you to learn without financial constraints.
- Udacity: Focuses on tech skills, particularly in programming, data science, and artificial intelligence. Their Nanodegree programs are well-regarded in the industry, equipping you with the skills needed to innovate and excel.
- LinkedIn Learning website: Offers a variety of online courses, including human resources management courses online, which can help you develop essential skills in HR.
- Online human resources courses: These courses provide valuable insights into HR practices and strategies, enhancing your professional development.
- HR management course online: A focused program that covers key aspects of human resource management, ideal for those looking to advance their careers in HR.
- HR management classes online: These classes offer flexibility and convenience for learning about HR principles and practices.
- Online course for HR: A great option for professionals seeking to improve their HR knowledge and skills.
Books and eBooks
- "The Pragmatic Programmer" by Andrew Hunt and David Thomas: A classic book that provides practical advice for software developers, helping you to streamline your development processes.
- "Clean Code" by Robert C. Martin: This book emphasizes the importance of writing clean, maintainable code and offers guidelines for achieving it, which can lead to reduced costs and increased productivity.
- "You Don’t Know JS" by Kyle Simpson: A series of books that dive deep into JavaScript, perfect for both beginners and experienced developers looking to refine their skills.
YouTube Channels
- Traversy Media: Offers tutorials on web development, covering various languages and frameworks, which can help you implement effective solutions for your projects.
- Academind: Provides in-depth tutorials on web development, including React, Angular, and Node.js, ensuring you stay updated with the latest technologies.
- The Net Ninja: Features a wide range of programming tutorials, from beginner to advanced levels, allowing you to learn at your own pace.
Podcasts
- Software Engineering Daily: Discusses various topics in software engineering, featuring interviews with industry experts, providing insights that can inform your strategic decisions.
- The Changelog: Focuses on open-source software and the people who make it, fostering a community of innovation and collaboration.
- Data Skeptic: Explores topics in data science, machine learning, and artificial intelligence, helping you leverage these technologies for better business outcomes.
Online Communities
- Stack Overflow: A question-and-answer site for programmers. You can ask questions, share knowledge, and learn from others, enhancing your problem-solving capabilities.
- GitHub: A platform for version control and collaboration. Explore open-source projects and contribute to them, gaining practical experience that can translate into real-world applications.
- Reddit: Subreddits like r/learnprogramming and r/datascience provide a space for discussion and resource sharing, connecting you with like-minded professionals.
Coding Practice
- LeetCode: A platform for practicing coding problems, especially useful for preparing for technical interviews, ensuring you are well-equipped for challenges.
- HackerRank: Offers coding challenges and competitions to improve your skills in various programming languages, fostering a culture of continuous improvement.
- Codewars: A gamified platform where you can solve coding challenges and improve your skills through practice, making learning engaging and effective.
Documentation and Official Resources
- MDN Web Docs: A comprehensive resource for web developers, covering HTML, CSS, and JavaScript, ensuring you have access to the latest standards and best practices.
- Python.org: The official Python documentation is an excellent resource for learning the language and its libraries, empowering you to build robust applications.
- React Documentation: The official React documentation provides a thorough guide to building applications with React, enabling you to create dynamic user experiences.
Conferences and Workshops
- TechCrunch Disrupt: An annual conference that showcases startups and new technologies, offering networking opportunities that can lead to strategic partnerships.
- PyCon: A conference for Python enthusiasts, featuring talks, tutorials, and networking opportunities, allowing you to connect with industry leaders.
- Google I/O: An annual developer conference where Google showcases its latest technologies and products, keeping you informed about cutting-edge advancements.
MOOCs and Specializations
- Google's Data Analytics Professional Certificate: A comprehensive program that covers data analysis skills, equipping you to make data-driven decisions.
- IBM Data Science Professional Certificate: A series of courses designed to help you become a data scientist, enhancing your analytical capabilities.
- Harvard's CS50: An introduction to computer science that is available for free online, providing foundational knowledge that can be applied across various domains.
- Free online learning courses for adults: These courses provide opportunities for adult learners to gain new skills and knowledge.
- Free online learning courses with certificates: Ideal for those looking to enhance their resumes with recognized credentials.
- Best online learning websites: A collection of platforms that offer high-quality educational content across various subjects.
These resources can help you stay updated and enhance your skills in your chosen field. By partnering with Rapid Innovation, you can leverage these insights and tools to achieve your goals efficiently and effectively, ultimately leading to greater ROI and success in your endeavors. Whether you prefer structured courses, self-study through books, or engaging with communities, there are plenty of options available to suit your learning style.








.svg)